Pandas の DataFrame(データフレーム) は、Python で表形式データを扱うときの「土台」となるデータ構造です。 CSV や Excel、データベースなどから読み込んだデータは、まず DataFrame に載せてから 前処理・集計・可視化・機械学習へと進んでいきます。
ただ、初めて触るときは次のようなところでつまずきがちです。
- Excel の表と何が違うのか、イメージがつかみにくい
- リスト・辞書・NumPy 配列など、作り方が多すぎて混乱する
- Series と DataFrame の違いがあいまいなまま進んでしまう
[]と[[]]、locとilocの違いが分からない
✅ この記事のゴール
- DataFrame の構造(値・列名・インデックス・
values)を図解でイメージできるようになる - リスト/辞書/辞書のリスト/NumPy 配列/CSV からの5種類の作り方を自力で書けるようになる
[]・[[]]・loc・ilocの違いを迷わず使い分けられるようになる- 実務の最初の一歩で使う 基本操作10個(
head/infoなど)がひと通り身につく
- 【この記事で学べること】
- 前提:Pandasのインストールとインポート
- Pandas DataFrame入門:全体像をつかむ
- Pandas DataFrame の作り方(生成方法)
- Pandas DataFrame と Series の違いを徹底理解
- 初心者が必ずつまずく「[] と [[]] の違い」
- 最初に覚えたい10個の基本操作(DataFrame版チェックリスト)
- ミニ演習:DataFrameの基本操作を手を動かして確認しよう
- 実務で最初に覚えるべき DataFrame 操作10個(完全チェックリスト)
- ✅ まとめ:DataFrameはPandas学習の「土台」
- 関連記事:Pandasデータ分析の次のステップ
- Zenn・Qiitaでも要点まとめています
【この記事で学べること】
- Pandas DataFrame とは何か?(Excel/スプレッドシートとの違い)
- DataFrame の基本構造(データ本体・列名・インデックス・
values・axes) - リスト/辞書/辞書のリスト/NumPy 配列/CSV から DataFrame を作成する 5 通りの方法
- Series と DataFrame の違いを直感的に理解するポイント
- 初心者がよくつまずく
[]と[[]]の違いと、その対処法 head/info/loc/ilocなど、最初に覚えたい基本操作 10 個- 実務でよく出てくる疑問をまとめた FAQ(DataFrame と Excel の違い・保存方法・型変換・コピー時の注意点など)
「細かいメソッドを丸暗記する」のではなく、DataFrame の構造イメージをつかむことをゴールにしています。
ここで土台を固めておくと、今後の loc / iloc、groupby、merge、concat、isin などの理解が一気に楽になります。
—————————————————————-
【体験談】私自身、最初にSeriesとDataFrameの違いが分からず、二重リストをSeriesに渡してエラーになったり、 [] と [[]] の違いに混乱したりしました。 「Series=1次元、DataFrame=2次元」という考え方と、列や行のラベル(インデックス)のイメージを持てるようになってから、Pandas全体が一気に理解しやすくなりました。
前提:Pandasのインストールとインポート
まだPandasをインストールしていない場合は、まず次のコマンドを実行します。
pip install pandas
Pythonコード内で使うときは、次のように pd という別名でインポートするのが定番です。
import pandas as pd
Pandas DataFrame入門:全体像をつかむ
pandas dataframeとは?:データ分析の中心となる表形式データ
Pandas DataFrame は、行と列からなる 2次元の表形式データ構造 です。 イメージとしては「Excelの表」「スプレッドシート」に近く、1 行が 1 レコード(1件のデータ)、1 列が 1 つの項目(属性)を表します。
各列には「列名(カラム名)」が付き、行には「インデックス(index)」と呼ばれるラベルが付きます。 これにより、単なる配列よりも 「どのデータが何を表しているか」 をはっきりさせながら処理できるのが特徴です。
Pandas DataFrame の基本構造を図でイメージする
例えば、次のようなテーブルを考えてみましょう。
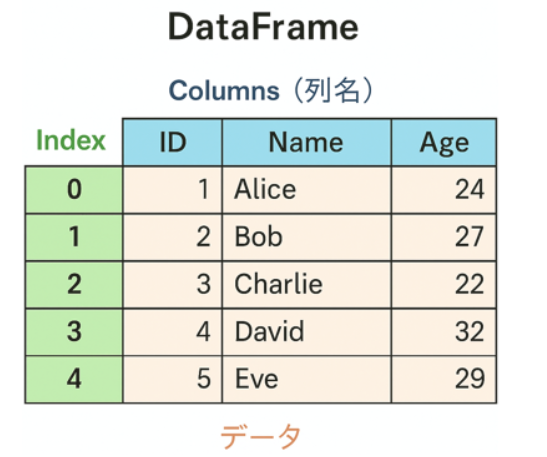
この表を DataFrame として考えると、ざっくり次のような構造になっています。
- 縦方向(行方向)に「レコード」が並ぶ。
- 横方向(列方向)に「項目(カラム)」が並ぶ。
- 行には index 、列には columns というラベルが付く。indexはデフォルトでは0から始まる連番だが、自由な値を設定できる。
- 実際の値は values として データが保持される。
コード上では、次のようにして DataFrame を扱います。
data = {'ID': [1, 2, 3, 4, 5],
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 27, 22, 32, 29]
}
df = pd.DataFrame(data)
display(df)
| ID | Name | Age | |
|---|---|---|---|
| 0 | 1 | Alice | 24 |
| 1 | 2 | Bob | 27 |
| 2 | 3 | Charlie | 22 |
| 3 | 4 | David | 32 |
| 4 | 5 | Eve | 29 |
内部構造をもう少しだけ深く:values・axes・dtypes
DataFrame の中身は、ざっくり次のような属性で確認できます。
- df.values … 実データ
- df.index … 行ラベル(インデックス)
- df.columns … 列ラベル(カラム名)
- df.dtypes … 各列のデータ型(int64, float64, object など)
- df.axes … 行と列のラベルをまとめた情報
これらを意識できるようになると、 「どの軸に沿って操作しているのか」 が分かりやすくなり、 axis=0 / axis=1 の指定なども迷いにくくなります。
よく使う属性:shape / columns / index / dtypes
特に次の4つは、DataFrameを受け取った直後に確認する「健康診断」のようなものです。
display(df.shape) # (行数, 列数)
display(df.columns) # 列名の一覧
display(df.index) # 行ラベルの一覧
display(df.dtypes) # 各列のデータ型
(5, 3)
Index([‘ID’, ‘Name’, ‘Age’], dtype=’object’)
RangeIndex(start=0, stop=5, step=1)
| 0 | |
|---|---|
| ID | int64 |
| Name | object |
| Age | int64 |
本格的なデータ分析に入る前に、 「どの列が数値で、どの列が文字列なのか」「行数・列数はどれくらいか」 をざっくり把握しておくと、後のトラブルを避けやすくなります。
Pandas DataFrame の作り方(生成方法)
DataFrame の作り方はいくつかパターンがありますが、よく使うのは次の6つです。
- リストのリストから作成する
- 辞書のリストから作成する(実務でよく使うパターン)
- 辞書から作成する(列ごとにデータがまとまっている場合)
- NumPy配列から作成する
- インデックスを指定して作成・変更する
- CSVファイルなど外部ファイルから作成する
1. リストのリストから作成する
data = [[1, 'Alice', 24],
[2, 'Bob', 27],
[3, 'Charlie', 22],
[4, 'David', 32],
[5, 'Eve', 29]
]
# columns引数で列名を指定してDataFrameを作成
df= pd.DataFrame(data, columns=['ID', 'Name', 'Age'])
display(df)
| ID | Name | Age | |
|---|---|---|---|
| 0 | 1 | Alice | 24 |
| 1 | 2 | Bob | 27 |
| 2 | 3 | Charlie | 22 |
| 3 | 4 | David | 32 |
| 4 | 5 | Eve | 29 |
2. 辞書のリストから作成する(実務でよく使うパターン)
Web API や JSON などから取得したデータは、この「辞書のリスト」形式になっていることが多いため、最も実務で登場しやすいパターンです。
data = [{'ID':1,'Name':'Alice','Age':24},
{'ID':2,'Name':'Bob','Age':27},
{'ID':3,'Name':'Charlie','Age':22},
{'ID':4,'Name':'David','Age':32},
{'ID':5,'Name':'Eve','Age':29},
]
df = pd.DataFrame(data)
display(df)
| ID | Name | Age | |
|---|---|---|---|
| 0 | 1 | Alice | 24 |
| 1 | 2 | Bob | 27 |
| 2 | 3 | Charlie | 22 |
| 3 | 4 | David | 32 |
| 4 | 5 | Eve | 29 |
3. 辞書から作成する(列ごとにデータがまとまっている場合)
列単位でデータが用意されているときは、辞書からの作成 がシンプルです。 辞書の「キー」が DataFrame の列名、「値」がその列のデータ(リストやNumPy配列)になります。
data = {'ID': [1, 2, 3, 4, 5],
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 27, 22, 32, 29]
}
df = pd.DataFrame(data)
display(df)
| ID | Name | Age | |
|---|---|---|---|
| 0 | 1 | Alice | 24 |
| 1 | 2 | Bob | 27 |
| 2 | 3 | Charlie | 22 |
| 3 | 4 | David | 32 |
| 4 | 5 | Eve | 29 |
4. NumPy配列から作成する
すでに NumPy配列 としてデータを持っている場合は、そのまま pd.DataFrame() に渡すこともできます。
# Numpyのインポート
# NumpyをPythonコード内で使うために、まずインポートします。一般的に、npという別名でインポートします。
import numpy as np
# NumPyは高速な数値計算を行うためのライブラリですが、
# 初心者の方は現時点でその詳細な使い方を深く気にする必要はありません。
# Pandas DataFrameを作成する際などに利用されることがある、という認識でまずは十分です。
# 同じ型の要素を持つ多次元配列を効率的に扱うのに役立ちます。
data = np.array([[1, 'Alice', 24],
[2, 'Bob', 27],
[3, 'Charlie', 22],
[4, 'David', 32],
[5, 'Eve', 29]
])
df = pd.DataFrame(data, columns=['ID', 'Name', 'Age'])
display(df)
| ID | Name | Age | |
|---|---|---|---|
| 0 | 1 | Alice | 24 |
| 1 | 2 | Bob | 27 |
| 2 | 3 | Charlie | 22 |
| 3 | 4 | David | 32 |
| 4 | 5 | Eve | 29 |
5. インデックスを指定して作成・変更する
インデックス(index) は各行のラベルで、DataFrame の「行番号」を人間が使いやすい形にしたものです。デフォルトでは 0, 1, 2, … の連番ですが、ID や日付など意味のある値に変えると、後の抽出や結合が分かりやすくなります。
data_dict_for_index = {'ID': [1, 2, 3, 4, 5],
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [24, 27, 22, 32, 29]}
df_index_example = pd.DataFrame(data_dict_for_index) # 元のdfを上書きしないように変数名を変更
display('インデックス設定前のDataFrame:', df_index_example)
# 'ID'列をインデックスに設定
df_with_index = df_index_example.set_index('ID')
display('ID列をインデックスに設定したDataFrame:', df_with_index)
‘インデックス設定前のDataFrame:’
| ID | Name | Age | |
|---|---|---|---|
| 0 | 1 | Alice | 24 |
| 1 | 2 | Bob | 27 |
| 2 | 3 | Charlie | 22 |
| 3 | 4 | David | 32 |
| 4 | 5 | Eve | 29 |
‘ID列をインデックスに設定したDataFrame:’
| Name | Age | |
|---|---|---|
| ID | ||
| 1 | Alice | 24 |
| 2 | Bob | 27 |
| 3 | Charlie | 22 |
| 4 | David | 32 |
| 5 | Eve | 29 |
既存の DataFrame に対してインデックスを変更したい場合は、 set_index() や reset_index() を使います。
6. CSVファイルなど外部ファイルから作成する
実務では、手書きのリストや辞書から作成するよりも、CSV / Excel / データベースなどのファイルから直接 DataFrameを読み込む ケースが多くなります。
既存のdf_index_exampleを利用してdata.csvを作成し、読み込みの準備をします。
# CSVファイルを作成
df_index_example.to_csv('data.csv', index=False)
# CSVファイルの読み込み
df = pd.read_csv("data.csv")
display(df)
| ID | Name | Age | |
|---|---|---|---|
| 0 | 1 | Alice | 24 |
| 1 | 2 | Bob | 27 |
| 2 | 3 | Charlie | 22 |
| 3 | 4 | David | 32 |
| 4 | 5 | Eve | 29 |
外部ファイルからの読み込みは DataFrame の代表的な利用シーンです。 詳しい使い方は、 Google ColabでCSVを読み書きする方法 で詳しく解説しています。
Pandas DataFrame と Series の違いを徹底理解
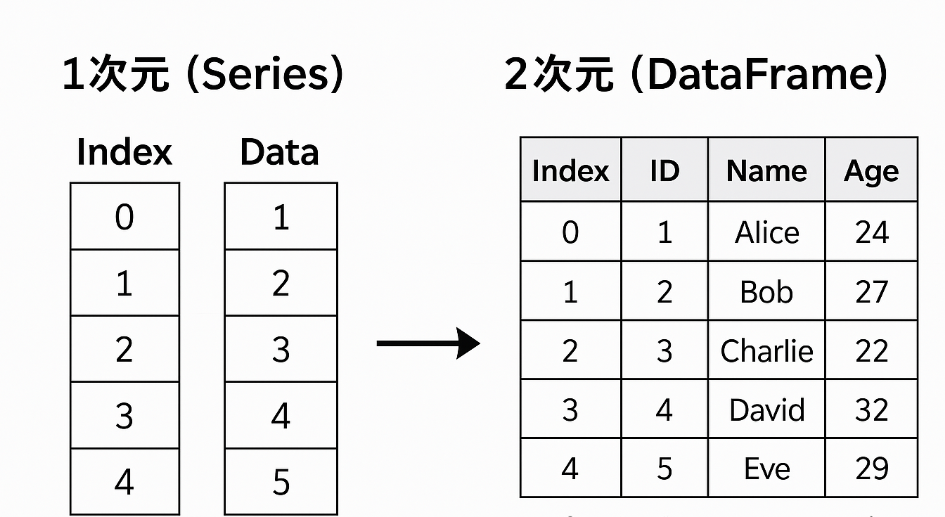
Seriesとは?:DataFrameの「1列」を表す1次元データ構造
Series は、DataFrame の「1列」に相当する 1次元のデータ構造 です。
s = pd.Series([25, 30, 35], name='Age')
display(s)
| Age | |
|---|---|
| 0 | 25 |
| 1 | 30 |
| 2 | 35 |
Seriesの基本的な作り方
Pandas Series も、pd.Series() メソッドを使って様々なデータ形式から作成できます。DataFrameの列が Series であることを理解するために、基本的な作成方法を簡単に見てみましょう。詳細な作成方法については、別の機会に詳しく解説します。
# リストから作成する例
data_s_list = [10, 20, 30, 40]
series_from_list = pd.Series(data_s_list)
display('リストから作成したSeries:', series_from_list)
# 辞書から作成する例(インデックスを指定したい場合に便利)
data_s_dict = {'a': 10, 'b': 20, 'c': 30, 'd': 40}
series_from_dict = pd.Series(data_s_dict)
display('辞書から作成したSeries:', series_from_dict)
‘リストから作成したSeries:’
| 0 | |
|---|---|
| 0 | 10 |
| 1 | 20 |
| 2 | 30 |
| 3 | 40 |
‘辞書から作成したSeries:’
| 0 | |
|---|---|
| a | 10 |
| b | 20 |
| c | 30 |
| d | 40 |
Series と DataFrame の決定的な違い(構造・次元・操作)
- Series … 1次元(インデックス + 値)
- DataFrame … 2次元(インデックス + 列 + 値)
「行列(2次元表)なのか、1本の列なのか」というイメージを意識すると、 [] や loc / iloc を使ったときの挙動が理解しやすくなります。
初心者が必ずつまずく「[] と [[]] の違い」
DataFrame から列を取り出すとき、次の2つの書き方がよく登場します。
display(df['Age']) # Series(1次元)
display(df[['Age']]) # DataFrame(2次元)
| Age | |
|---|---|
| 0 | 24 |
| 1 | 27 |
| 2 | 22 |
| 3 | 32 |
| 4 | 29 |
| Age | |
|---|---|
| 0 | 24 |
| 1 | 27 |
| 2 | 22 |
| 3 | 32 |
| 4 | 29 |
最初は違いが分かりにくいですが、次のように覚えるとスッキリします。
- df['col'] … 1本の列(Series)がほしいとき
- df[['col']] … 列は1つでも「表(DataFrame)」として扱いたいとき
一部のメソッド( groupby や merge など)を使用する際は「DataFrameを渡すこと」を前提としているため、そのような場面では [[]] を使います。
最初に覚えたい10個の基本操作(DataFrame版チェックリスト)
DataFrameのすべてを一気に覚える必要はありません。 まずは次の 10個の基本操作 だけ押さえておけば、入門〜基礎的な実務はほぼこなせます。
| カテゴリ | 代表的なメソッド・属性 | 何ができるか | 詳しい解説記事 |
|---|---|---|---|
| ① 中身を見る |
df.head()
,
df.tail()
|
先頭・末尾の数行を確認して、全体のイメージをつかむ | ▶ head()/tail()で先頭・末尾を確認 |
| ② 構造・型を確認 |
df.info()
,
df.describe()
,
df.shape
,
df.dtypes
|
行数・列数、欠損、データ型、基本統計量をまとめてチェック | ▶ info()/describe()で構造と統計量を確認 |
| ③ 行・列を指定して抽出 |
df["col"]
,
df[["col1","col2"]]
,
df.loc[行ラベル, 列ラベル]
,
df.iloc[行番号, 列番号]
|
欲しい行・列だけを取り出す(1次元Seriesか2次元DataFrameかを意識) |
▶
locでラベル抽出
▶ ilocで番号抽出 ▶ locとilocの違いと使い分け |
| ④ 条件で絞り込む |
比較演算(
==
,
>
等)、
&
,
|
,
~
,
isin()
|
「点数が80点以上」「都道府県が東京都 or 大阪府」などの条件で行を抽出 |
▶
条件抽出・フィルタリング
▶ isinで複数条件をまとめて抽出 |
| ⑤ 並び替える |
df.sort_values()
,
df.sort_index()
|
売上の高い順、日付の新しい順などにソートして並び順を整える | ▶ sort_values/sort_indexで並び替え |
| ⑥ 列を追加・更新する |
df["new_col"] = ...
,
assign()
|
合計点や平均点、フラグ列(True/False)などの派生列を作る | ▶ (列追加の詳細は drop/dropna記事 も合わせて確認) |
| ⑦ 不要な行・列を削除 |
df.drop()
,
df.dropna()
,
df.drop_duplicates()
|
不要な列や欠損・重複を取り除き、分析しやすい形にする | ▶ drop/dropna/drop_duplicatesで削除 |
| ⑧ グループごとに集計 |
df.groupby()
,
agg()
,
mean()
,
sum()
|
店舗ごとの売上合計、学年ごとの平均点など、カテゴリ別に集計する | ▶ groupby/aggで集計 |
| ⑨ 表同士を結合・連結 |
pd.concat()
,
pd.merge()
|
同じ列構造の表を上下にくっつけたり、キー列を軸に結合したりする |
▶
concatで縦横連結
▶ mergeで結合 |
| ⑩ CSVファイルの読み書き |
pd.read_csv()
,
df.to_csv()
|
CSVファイルから読み込んでDataFrameを作り、加工後のデータをCSVとして保存 |
▶ Google ColabでCSVを読み書き |
上の表を「チェックリスト」として使い、1つずつ実際のデータで試してみるのがおすすめです。 すべてのメソッドを完璧に覚える必要はなく、 「こんなときにこのメソッドを使う」 という対応関係だけ押さえておけば十分です。
ミニ演習:DataFrameの基本操作を手を動かして確認しよう
最後に、この記事で紹介した内容を小さなデータセットで試してみましょう。 以下のコードでサンプルDataFrame df_students を作成します。
import pandas as pd
data = { 'name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'math': [80, 65, 90, 70, 85],
'english': [75, 88, 92, 60, 78],
'class': ['A', 'B', 'A', 'B', 'A']
}
df_students = pd.DataFrame(data)
display(df_students)
| name | math | english | class | |
|---|---|---|---|---|
| 0 | Alice | 80 | 75 | A |
| 1 | Bob | 65 | 88 | B |
| 2 | Charlie | 90 | 92 | A |
| 3 | David | 70 | 60 | B |
| 4 | Eve | 85 | 78 | A |
この df_students を使って、次の問題を解いてみてください。
- 先頭3行だけを確認 してみましょう。
- 行数・列数・列名・データ型 をそれぞれ1行ずつで確認してみましょう。
- 数学の点数が80点以上 の行だけを抽出してみましょう。
- 各クラスごとの数学の平均点 を求めてみましょう。
- 総合点(math + english) の列を追加し、総合点の高い順に並び替えてみましょう。
解答例(一例)
# 1. 先頭3行
display(df_students.head(3))
# 2. 構造・型の確認
# (行数, 列数)
display(df_students.shape)
# 列名
display(df_students.columns)
# 各列のデータ型
display(df_students.dtypes)
# まとめて確認
display(df_students.info())
# 3. 数学が80点以上の行を抽出
display(df_students[df_students['math'] >= 80])
# 4. クラスごとの数学の平均点
display(df_students.groupby('class')['math'].mean())
# 5. 総合点の列を追加し、高い順に並び替え
df_students['total'] = df_students['math'] + df_students['english']
df_sorted = df_students.sort_values('total', ascending=False)
display(df_sorted)
| name | math | english | class | |
|---|---|---|---|---|
| 0 | Alice | 80 | 75 | A |
| 1 | Bob | 65 | 88 | B |
| 2 | Charlie | 90 | 92 | A |
| 0 | |
|---|---|
| name | object |
| math | int64 |
| english | int64 |
| class | object |
| name | math | english | class | |
|---|---|---|---|---|
| 0 | Alice | 80 | 75 | A |
| 2 | Charlie | 90 | 92 | A |
| 4 | Eve | 85 | 78 | A |
| math | |
|---|---|
| class | |
| A | 85.0 |
| B | 67.5 |
| name | math | english | class | total | |
|---|---|---|---|---|---|
| 2 | Charlie | 90 | 92 | A | 182 |
| 4 | Eve | 85 | 78 | A | 163 |
| 0 | Alice | 80 | 75 | A | 155 |
| 1 | Bob | 65 | 88 | B | 153 |
| 3 | David | 70 | 60 | B | 130 |
ここで使った操作の多くは、この記事の 「最初に覚えたい10個の基本操作」 に含まれています。 分からないところがあれば、該当する項目に戻ったり、リンク先の詳しい解説記事も参照してみてください。
実務で最初に覚えるべき DataFrame 操作10個(完全チェックリスト)
DataFrame を使う仕事(データ前処理・分析)では、まず次の 10 個を覚えるだけで 80% のタスクはこなせます。
- df.head():データの先頭を確認
- df.tail():データの末尾を確認
- df.info():データ型・欠損の有無を確認
- df.describe(include=’all’):統計量の確認
- df.columns / df.index:列名・行名を確認
- df[‘col’] / df[[‘col’]]:列の抽出(Series / DataFrame)
- df.loc[row, col] / df.iloc[row, col]:行・列の抽出
- df.sort_values():並び替え(昇順・降順)
- df.isnull().sum():欠損値のチェック
- df.drop():列削除・行削除
この 10 個を使いこなせるようになると、次のステップ(groupby、merge、concat、pivot_table)が格段に理解しやすくなります。
実務では「まず状況把握(head / info / describe)」→「基礎操作(抽出・並べ替え)」→「整形(drop / fillna)」の順で手を動かすと効率が良いです。
✅ まとめ:DataFrameはPandas学習の「土台」
本記事では、pandas dataframe の基本構造・作り方・Seriesとの違い・[] と [[]] の使い分け、最初に押さえておきたい基本操作までを整理しました。
- DataFrameは「ラベル付きの2次元表」であり、Pandas学習の中心
- 行・列・インデックス・データ型のイメージを持つことが重要
- 最初は10個の基本操作だけ押さえればOK(あとは必要に応じて深堀り)
DataFrame のイメージが持てるようになれば、あとは loc/iloc・条件抽出・欠損値処理・groupby・merge/concat などを少しずつ練習していくだけです。 次の「関連記事」から、興味のあるものを選んで進んでみてください。
関連記事:Pandasデータ分析の次のステップ
- head()/tail()で先頭・末尾を確認する
- info()/describe()で構造と統計量を確認する
- locでラベル指定の行・列を抽出する
- ilocで番号指定の行・列を抽出する
- locとilocの違い・使い分け
- 条件抽出・フィルタリングの基本
- sortで並び替えをする
- concatでDataFrameを連結する
- mergeでDataFrameを結合する
- isinで複数条件をまとめて抽出する
- 欠損値を見つける
- drop/dropna/drop_duplicatesで行・列・欠損・重複を削除する
- groupby/aggでグループごとに集計する
- Multiindexで階層型インデックスを作成・集計する
- pivot tableで集計する
【Pandas】
- ▶ MatplotlibでPandasデータを可視化する方法
【Matplotlib】
Zenn・Qiitaでも要点まとめています
記事の要点だけをサクッと復習したい場合は、Zenn・Qiita にまとめたショート版もどうぞ。
Q1. DataFrame と Excel の表は何が違いますか?
見た目は似ていますが、 DataFrameはプログラムから自由に操作できる表 です。 列ごとのデータ型を意識しながら、条件抽出・集計・結合・可視化などをコードで再現できます。 一度書いた処理は、別のデータセットにも簡単に再利用できる点が大きな違いです。
Q2. DataFrame を作ったあと、まず何を確認すればいいですか?
次の 4 つをセットで確認するのがおすすめです。
df.shape – 行数と列数
df.columns – 列名
df.dtypes – 各列のデータ型
df.head() – 先頭数行
これらを見ておくことで、「どんなデータがどれくらいあるのか」「文字列だと思っていた列が実は数値として扱われている」などの気づきを早期に得られます。 head()/tail()の使い方まとめ も併せてどうぞ。
Q3. DataFrameの行・列の抽出はどこで学べばいいですか?
行・列の抽出には loc (ラベルベース)と iloc (番号ベース)がよく使われます。 それぞれの基本的な使い方と、違い・使い分けは次の記事で詳しく解説しています。
▶locでラベル抽出
▶ilocで番号抽出
▶locとilocの違い・使い分け
Q4. 列名を変更したいときはどうすればいいですか?
列名の変更には rename() を使います。
df_renamed = df.rename(columns={‘Name’: ‘name’, ‘Age’: ‘age’})
元のDataFrameを直接書き換えたい場合は、 inplace=True を指定するか、上書き代入( df = df.rename(…) )を行います。
Q5. 数値の列が object 型(文字列)になってしまいました…
CSV読み込み時などに、数値の列が object 型になってしまうことがあります。 その場合は、 astype() や pd.to_numeric() で型変換します。
# ‘Age’ 列を数値型に変換(変換できない値は NaN にする例)
df[‘Age’] = pd.to_numeric(df[‘Age’], errors=’coerce’)
display(df.dtypes)
変換時にエラーが出る場合は、空文字や「-」など数値に変換できない値が混ざっていることが多いです。 pd.to_numeric(df[‘Age’], errors=’coerce’) でいったん NaN にし、その後 fillna や dropna で処理するのが定番パターンです。
Q6. DataFrameをExcelやCSVに保存するには?
DataFrameは to_csv() や to_excel() で簡単に保存できます。
# CSVとして保存(インデックスは保存しない例)
df.to_csv(‘output.csv’, index=False)
# Excelとして保存
df.to_excel(‘output.xlsx’, index=False)
Google Colab と Google Drive を組み合わせてファイルを読み書きする方法は、次の記事で詳しく解説しています。
▶ Google Colab CSV 読み込み&保存入門
Q7. DataFrameの処理が遅いときはどうすればいいですか?
for文で1行ずつ処理していると、Python側のループがボトルネックになります。 可能な限り 「列全体に対する演算(ベクトル化)」 や、 apply / map などの関数を使うと高速化しやすくなります。 どうしても重い場合は、行数・列数が大きすぎないか( df.shape )も確認しましょう。
Q8. DataFrameをコピーするときに注意することは?
df2 = df のように代入すると、 同じオブジェクトを指す別名 になります。 別の独立したDataFrameがほしい場合は、 df.copy() を使いましょう。
df2 = df.copy() # これで独立したコピーになる
コメント