
データ分析で困った!「NaN」というやっかいな存在
Pythonでデータ分析をしていると、データの中に「NaN」という文字を見かけることがありますよね。これは「Not a Number」の略で、データが欠損していることを示しています。
データ分析でよく見かけるNaN(欠損値)。一体なぜデータは欠損するのでしょうか? 主な原因をいくつか見てみましょう。
データ収集時の問題: アンケートの未回答、Webスクレイピング時のエラーなど。
データの結合・集計: 異なるデータソースを結合する際に、一部のデータが存在しない場合。特定の条件で集計した際に、該当するデータがない場合など。
人為的な入力ミス: データの入力時に誤って空欄にしてしまった場合。
データの取得方法: データベースの仕様やAPIの制限により、一部のデータが取得できない場合。
このように、欠損値の発生原因は様々です。この「NaN」は、データ分析において様々な問題を引き起こすことがあります。例えば、
- ある列の平均値を計算しようとしたら、結果が NaN になってしまった。
- グラフを描こうとしたら、一部のデータが表示されない。
- データを使った機械学習モデルの精度が上がらない。
なんて経験、ありませんか? 特にデータ分析を始めたばかりの頃は、「なんでこの列だけうまくいかないんだろう…」と悩むことも多いはずです。
でも安心してください! Pandasには、この「NaN」を見つけ出し、上手に扱うための便利な機能が用意されています。この記事では、その中でも特に役立つ isnull() と isnull().sum() というメソッドを徹底的に解説します。
▶️ isnullの公式ドキュメントも参考にしてください:
pandas DataFrame isnull Documentation
まずはサンプルデータを作成しましょう。
import pandas as pd
import seaborn as sns # サンプルデータのためにインポート
df = sns.load_dataset('titanic') # より現実的なサンプルデータ(タイタニックデータの一部を利用)。このデータセットはseabornライブラリに含まれています
df = df[['survived', 'pclass', 'sex', 'age', 'fare', 'embarked']].head(10) # 今回の解説に必要な列に絞り、一部欠損値を意図的に作成
df.loc[[1, 3], 'age'] = None # ageに欠損値をいくつか作成
df.loc[7, 'embarked'] = None # embarkedに欠損値をいくつか作成
df.loc[8, 'fare'] = None # fareに欠損値をいくつか作成
print("元のデータ(一部):")
df
| survived | pclass | sex | age | fare | embarked | |
|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 7.2500 | S |
| 1 | 1 | 1 | female | NaN | 71.2833 | C |
| 2 | 1 | 3 | female | 26.0 | 7.9250 | S |
| 3 | 1 | 1 | female | NaN | 53.1000 | S |
| 4 | 0 | 3 | male | 35.0 | 8.0500 | S |
| 5 | 0 | 3 | male | NaN | 8.4583 | Q |
| 6 | 0 | 1 | male | 54.0 | 51.8625 | S |
| 7 | 0 | 3 | male | 2.0 | 21.0750 | None |
| 8 | 1 | 3 | female | 27.0 | NaN | S |
| 9 | 1 | 2 | female | 14.0 | 30.0708 | C |
NaNを見つけるには、isnull()メソッドを使います。
データの中に NaN がどこにあるかを知りたい。そんな時に活躍するのが isnull() メソッドです。これは、DataFrameやSeriesの各要素が NaN かどうかを判定し、結果を True/False で返してくれます。
df1=df.copy() #df1はdfのコピーです。
df1.isnull()
| survived | pclass | sex | age | fare | embarked | |
|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False |
| 1 | False | False | False | True | False | False |
| 2 | False | False | False | False | False | False |
| 3 | False | False | False | True | False | False |
| 4 | False | False | False | False | False | False |
| 5 | False | False | False | True | False | False |
| 6 | False | False | False | False | False | False |
| 7 | False | False | False | False | False | True |
| 8 | False | False | False | False | True | False |
| 9 | False | False | False | False | False | False |
この結果を見ると、DataFrameのどこに NaN があるのかが一目でわかりますね。
一目でわかる!isnull().sum() で列ごとの欠損数をカウント
isnull() で欠損の位置はわかりましたが、データ全体で、あるいは列ごとに、合計でいくつ NaN があるのかを知りたい場合が多いはずです。そんな時に便利なのが isnull().sum() です。
df1.isnull().sum()
| 0 | |
|---|---|
| survived | 0 |
| pclass | 0 |
| sex | 0 |
| age | 3 |
| fare | 1 |
| embarked | 1 |
isnull()が返すTrue/Falseは、.sum()でTrue=1、False=0として集計されるため、各列の欠損数を確認できます。! これはデータの前処理で最初に確認しておきたい情報ですね。
一目でわかる!欠損値の分布を可視化する
isnull().sum() で各列の欠損数を知ることは、データ全体の欠損の量を把握する上で非常に重要です。しかし、データセット全体のどこに欠損値が集中しているのか、あるいは複数の列で同時に欠損が発生しやすいのかなどを視覚的に確認したい場合もあります。
このような時に役立つのが、ヒートマップを使った欠損値の可視化です。ここでは、seaborn ライブラリを使って DataFrame の欠損値をヒートマップとして表示する方法を紹介します。
まず、可視化に必要なライブラリをインポートします。seaborn と、グラフを描画するための matplotlib.pyplot を使用します
import matplotlib.pyplot as plt
import seaborn as sns
次に、df.isnull() の結果(DataFrameの各要素がNaNかどうかを示すTrue/FalseのDataFrame)を seaborn.heatmap() 関数に渡してヒートマップを描画します。
# 欠損値のヒートマップを描画
plt.figure(figsize=(10, 6)) # グラフのサイズを指定(任意)
sns.heatmap(df.isnull(), cmap='viridis', cbar=False) # df.isnull()の結果をヒートマップに、cmapで色、cbar=Falseでカラーバー非表示
plt.title('Missing Values Heatmap') # グラフのタイトルを設定
plt.show() # グラフを表示
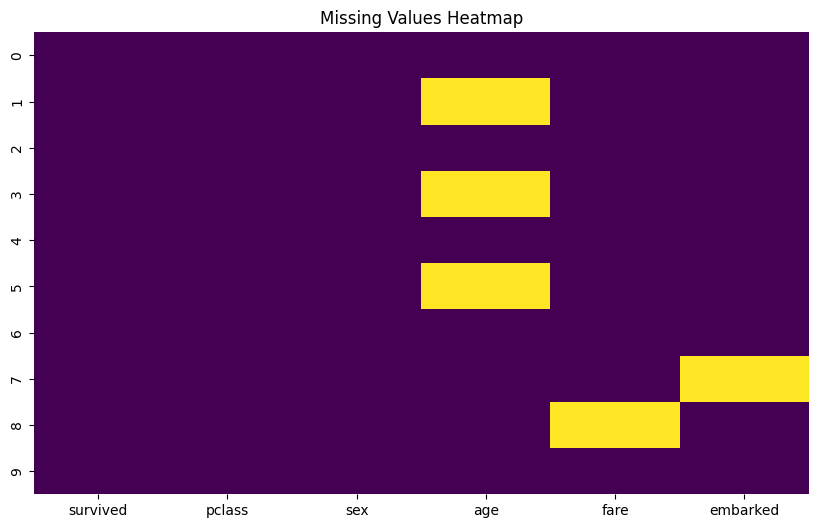
| <Figure size 1000×600 with 1 Axes> |
このヒートマップでは、色が濃いセルが欠損値(NaN)がある場所を示しています。
例えば、上記のサンプルデータでこのヒートマップを描画すると、age 列にいくつか欠損がある行、そして embarked 列と fare 列にもそれぞれ欠損がある行がどこにあるのかを、全体像として把握できます。特定の行に複数の欠損が集まっているかも視覚的に確認できます。
このようにヒートマップを使うことで、isnull().sum() で把握した数値情報に加えて、欠損値がデータセット内でどのように分布しているのか、直感的に理解できるようになります。これは、次のステップである欠損値の処理方法(削除するか、補完するか、どのように補完するかなど)を検討する上で、非常に役立つ情報となります。
(オプション) missingno ライブラリを使った可視化
より高度な欠損値の可視化を行いたい場合は、missingno というライブラリが便利です。これは欠損値のパターン分析に特化しており、以下のようなヒートマップを描画できます。このヒートマップは、異なる列間で欠損値が同時に発生する相関関係を示します。
必要であれば、以下のコマンドでインストールできます。
!pip install missingno==0.5.2
インストール後、以下のように使用します。
import missingno as msno
# missingnoを使った欠損値の相関ヒートマップ
plt.figure(figsize=(10, 8)) # グラフのサイズを指定(任意)
msno.heatmap(df, cmap="viridis", fontsize=16)
plt.title('Missing Values Correlation Heatmap') # グラフのタイトルを設定
plt.show() # グラフを表示
| <Figure size 1000×800 with 0 Axes> |
| <Figure size 2000×1200 with 2 Axes> |
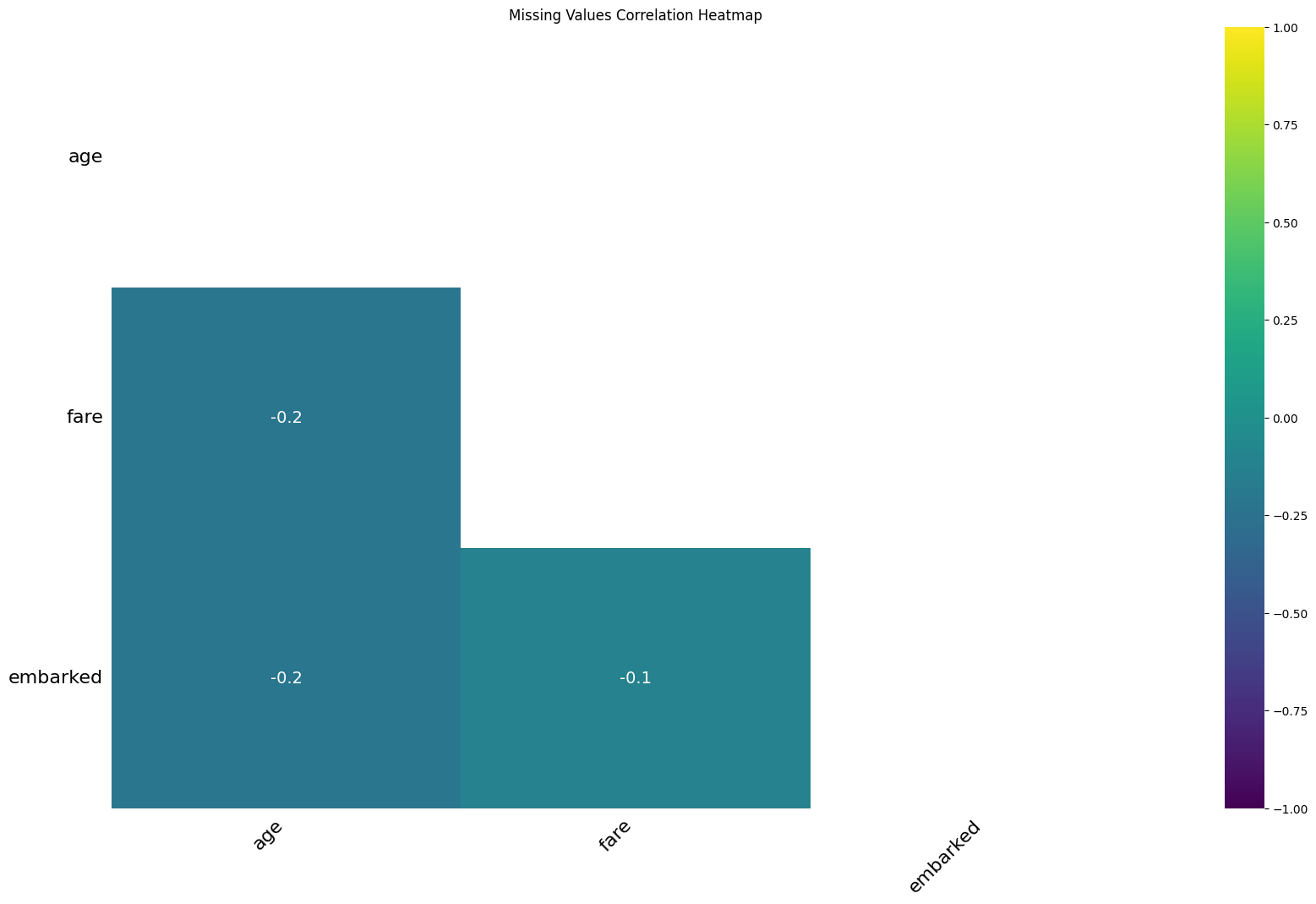
missingno.heatmap の結果は、マトリックス形式で表示され、対角線以外のセルは対応する2つの列で欠損値が同時に発生する相関関係を示します。この相関は -1 から 1 の間の値を取ります。
値が1に近いほど: その2つの列の欠損は、同時に発生しやすい傾向にあります。例えば、ある列が欠損している行では、別の列も高確率で欠損しているといったパターンが見られます。これは、データ収集時に両方の情報が同時に取得できなかった、あるいは特定の条件で両方のデータが欠損しやすいといった共通の原因がある可能性を示唆します。
値が0に近いほど: その2つの列の欠損には、あまり相関がありません。一方の列の欠損が、もう一方の列の欠損と関連しているとは考えにくい場合です。それぞれの列で独立して欠損が発生している可能性があります。
値が-1に近いほど: その2つの列の欠損は、同時に発生しにくい、つまり排他的な関係にある傾向があります。一方の列に欠損がある場合、もう一方の列にはデータが存在する可能性が高いといったパターンです。ただし、欠損値の相関において負の相関が強く出るケースは比較的少ないかもしれません。
missingno.heatmap をどのように分析に活かすか?
このヒートマップは、データセット全体の欠損パターンの全体像を掴むのに非常に役立ちます。
特定の列の欠損が他の列と強く相関しているかを確認する: もし特定の列の欠損が他の複数の列と強く相関している場合、それらの列の欠損は同じ原因に起因している可能性があり、まとめて処理を検討する必要があるかもしれません。
欠損パターンの理解を深める: なぜ特定の列で同時に欠損が発生しやすいのか、その背景にある可能性(データ収集方法、データの構造など)を考察するヒントになります。
この相関ヒートマップは、isnull().sum()で得られる各列の欠損数に加え、「欠損値がどのように組み合わさって発生しているか」という、より深い理解を提供してくれます。これは、次にどの欠損値処理方法(削除、補完、あるいは欠損を考慮したモデルの選択など)を選択すべきかを判断する上で重要な情報となります。
応用編:見つけた欠損値をどう扱う?
isnull() や isnull().sum() で欠損の状況を把握したら、次に考えたいのが「欠損値が含まれるデータをどう扱うか」です。欠損値の扱い方にはいくつかのアプローチがあります。
欠損値を含む行や列を抽出・削除する
まず、欠損値を含むデータを「確認したい」あるいは「思い切って削除したい」という場合があります。
例えば、欠損値を含む行だけを抽出して確認したい場合は以下のように書きます
df2=df.copy() #df2はdfのコピーです。
df2[df2.isnull().any(axis=1)]
| survived | pclass | sex | age | fare | embarked | |
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | female | NaN | 71.2833 | C |
| 3 | 1 | 1 | female | NaN | 53.1000 | S |
| 5 | 0 | 3 | male | NaN | 8.4583 | Q |
| 7 | 0 | 3 | male | 2.0 | 21.0750 | None |
| 8 | 1 | 3 | female | 27.0 | NaN | S |
また、欠損値を含む行や列を削除したい場合は dropna() メソッドを使います。
df2.dropna()
| survived | pclass | sex | age | fare | embarked | |
|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 7.2500 | S |
| 2 | 1 | 3 | female | 26.0 | 7.9250 | S |
| 4 | 0 | 3 | male | 35.0 | 8.0500 | S |
| 6 | 0 | 1 | male | 54.0 | 51.8625 | S |
| 9 | 1 | 2 | female | 14.0 | 30.0708 | C |
欠損値を他の値で埋める(補完)
欠損値を削除してしまうとデータ量が減ってしまう場合、代わりに何らかの値で欠損値を「埋める」(補完するとも言います)という方法があります。これには Pandas の fillna() メソッドがよく使われます。
fillna() を使うことで、欠損値を様々な方法で埋めることができますが、どの方法で補完するのが適切かは、データの性質、欠損値の種類(数値かカテゴリか)、欠損の割合、そして分析の目的に応じて慎重に検討する必要があります。
安易な補完は、データの解釈やモデルの精度に悪影響を及ぼす可能性があることを覚えておきましょう。
以下にいくつか例を見てみましょう。それぞれの方法の「どのような場合に使うか」という点も意識して見ていきましょう。
この方法の注意点:
固定値で埋めるのはシンプルですが、データの分布を歪めてしまう可能性があります。例えば、テストの点数を0で埋めると、全体の平均点が実際よりも大きく下がってしまうなどが考えられます。安易な固定値での補完は避けるべき場合が多いです。
どのような場合に使うか:
欠損値自体に特定の意味がある場合(例: アンケートで「回答なし」を0と扱う)など限定的な場合に使用を検討します。安易な固定値での補完は、データの分布を歪めてしまう可能性が高いため、避けるべき場合が多いです。
特定の固定値で埋める
# 例:アンケートデータで「回答なし」を0として処理する場合
df_survey = pd.DataFrame({
'question1': [5, 4, None, 5],
'question2': ['Yes', None, 'No', 'Yes']
})
print("固定値埋め前のデータ:")
display(df_survey)
# question1の欠損値を0で埋める
df_survey['question1'].fillna(0,inplace=True)
print("\n固定値(0)で埋めた後のデータ:")
display(df_survey)
固定値を埋める前のデータ:
| question1 | question2 | |
|---|---|---|
| 0 | 5.0 | Yes |
| 1 | 4.0 | None |
| 2 | NaN | No |
| 3 | 5.0 | Yes |
固定値(0)で埋めた後のデータ:
| question1 | question2 | |
|---|---|---|
| 0 | 5.0 | Yes |
| 1 | 4.0 | None |
| 2 | 0.0 | No |
| 3 | 5.0 | Yes |
補足: fillna() メソッドは、デフォルトでは欠損値を埋めた新しいDataFrame(またはSeries)を返します。そのため、上のコードのように df_survey['question1'].fillna(0) とだけ書いた場合、元の df3 自体は変更されません。
ただし、inplace=True を使うと元のオブジェクトが直接変更されるため、意図しない変更を防ぐために、新しい変数に代入する方法 (df_survey['question1']=df_survey['question1'].fillna(0,inplace=True)) を推奨する場合もあります。どちらの方法を使うかは状況に合わせて判断しましょう。
平均値や中央値で埋める
数値データの場合、その列の平均値や中央値で欠損値を埋めることもよく行われます。
どのような場合に使うか:
数値データで、欠損がランダムに発生していると考えられる場合:例として、身長や体重などの計測データで、たまたま記録が漏れてしまったような場合。
データの分布を大きく変えずに補完したい場合:特に、欠損値の数が比較的少なく、データの偏りが小さい場合に適しています。
外れ値の影響を受けたくない場合: データの分布に外れ値が多い場合: 平均値よりも中央値で補完する方が、外れ値に引っ張られずにデータの中心傾向をより適切に表現できます。
この方法の注意点:
- メリット: 欠損値をその列の代表値で補完するため、データの分布への影響を比較的抑えられます。特に、欠損値の数が少ない場合や、データが正規分布に近い場合に有効です。
- デメリット: 外れ値が多いデータの場合、平均値は外れ値に引っ張られてしまうため、中央値で補完する方が適切なことがあります。また、この方法で補完された値は実際の観測値ではないため、モデルの精度に影響を与える可能性があります。
- 適用シーン: データの分布を大きく変えずに補完したい場合や、欠損値がランダムに発生していると考えられる場合に有効です。
# 例:商品の売上データで、一部の日付の売上データが欠損している場合
df_sales = pd.DataFrame({
'date': pd.to_datetime(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05']),
'sales': [1000, 1500, None, 1200, 1800]
})
print("平均値・中央値で埋める前のデータ:")
display(df_sales)
# 売上の中央値で欠損値を埋める
median_sales = df_sales['sales'].median()
print(f"\n売上の中央値: {median_sales}")
df_sales['sales'] = df_sales['sales'].fillna(median_sales)
print("中央値で埋めた後のデータ:")
display(df_sales)
平均値・中央値で埋める前のデータ
| date | sales | |
|---|---|---|
| 0 | 2023-01-01 | 1000.0 |
| 1 | 2023-01-02 | 1500.0 |
| 2 | 2023-01-03 | NaN |
| 3 | 2023-01-04 | 1200.0 |
| 4 | 2023-01-05 | 1800.0 |
売上の中央値:1350.0
中央値で埋めた後のデータ
| date | sales | |
|---|---|---|
| 0 | 2023-01-01 | 1000.0 |
| 1 | 2023-01-02 | 1500.0 |
| 2 | 2023-01-03 | 1350.0 |
| 3 | 2023-01-04 | 1200.0 |
| 4 | 2023-01-05 | 1800.0 |
最頻値で埋める
カテゴリデータの欠損値を埋める際によく使われます。その列で最も頻繁に出現する値で欠損値を補完します。
どのような場合に使うか:
カテゴリデータで、欠損がランダムに発生していると考えられる場合: 例として、商品のカテゴリや顧客の性別などのデータで、入力漏れやエラーで欠損している場合。
最も可能性の高い値で補完したい場合: そのカテゴリにおいて最も一般的な値で補完することで、データの歪みを最小限に抑えたい場合。
# 例:顧客データの性別で、一部が欠損している場合
df_customers = pd.DataFrame({
'customer_id': [1, 2, 3, 4, 5],
'gender': ['Male', 'Female', None, 'Male', 'Female']
})
print("最頻値で埋める前のデータ:")
display(df_customers)
# 性別の最頻値で欠損値を埋める
most_frequent_gender = df_customers['gender'].mode()[0]
print(f"\n性別の最頻値: {most_frequent_gender}")
df_customers['gender'] = df_customers['gender'].fillna(most_frequent_gender)
print("最頻値で埋めた後のデータ:")
display(df_customers)
最頻値で埋める前のデータ:
| customer_id | gender | |
|---|---|---|
| 0 | 1 | Male |
| 1 | 2 | Female |
| 2 | 3 | None |
| 3 | 4 | Male |
| 4 | 5 | Female |
性別の最頻値:Female
最頻値で埋める前のデータ:
| customer_id | gender | |
|---|---|---|
| 0 | 1 | Male |
| 1 | 2 | Female |
| 2 | 3 | Female |
| 3 | 4 | Male |
| 4 | 5 | Female |
直前の値や直後の値で埋める
時系列データなど、データの並びに意味がある場合は、直前の値 (ffill) や直後の値 (bfill) で埋める方法も有効です。
どのような場合に使うか:
時系列データのように順序に意味があるデータで、欠損が短期間である場合: 例として、株価、気温、センサーデータなどの連続的なデータで、一時的にデータ取得ができなかった場合。
データの連続性を保ちたい場合: 欠損の前後のデータと関連性が強いと考えられる場合。
この方法の注意点:
- メリット: 時系列データのように順序に意味があるデータの場合、直前や直後の値で補完することで、データの連続性を保つことができます。
- デメリット: 欠損期間が長い場合、同じ値で連続して補完されてしまい、実際のデータの変化を捉えられない可能性があります。また、
ffillやbfillは、データの最初や最後の欠損値を処理できない場合があります(ffillは最初の欠損、bfillは最後の欠損を埋められません)。 - 適用シーン: 株価、気温、売上データなどの時系列データで、欠損が短期間である場合に特に有効です。
# 例:時系列データの気温で、一部の日付のデータが欠損している場合
df_temp = pd.DataFrame({
'date': pd.to_datetime(['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05']),
'temperature': [5.2, 6.1, None, 5.8, 6.5]
})
print("ffill/bfill 埋め前のデータ:")
display(df_temp)
# 直前の値で欠損値を埋める (ffill)
print("\n直前の値 (ffill) で埋めた後のデータ:")
display(df_temp.fillna(method='ffill'))
# 直後の値で欠損値を埋める (bfill)
print("\n直後の値 (bfill) で埋めた後のデータ:")
display(df_temp.fillna(method='bfill'))
ffill/bfill 埋め前のデータ
| date | temperature | |
|---|---|---|
| 0 | 2023-01-01 | 5.2 |
| 1 | 2023-01-02 | 6.1 |
| 2 | 2023-01-03 | NaN |
| 3 | 2023-01-04 | 5.8 |
| 4 | 2023-01-05 | 6.5 |
直前の値(ffill)で埋めた後のデータ:
| date | temperature | |
|---|---|---|
| 0 | 2023-01-01 | 5.2 |
| 1 | 2023-01-02 | 6.1 |
| 2 | 2023-01-03 | 6.1 |
| 3 | 2023-01-04 | 5.8 |
| 4 | 2023-01-05 | 6.5 |
直後の値(bfill)で埋めた後のデータ:
| date | temperature | |
|---|---|---|
| 0 | 2023-01-01 | 5.2 |
| 1 | 2023-01-02 | 6.1 |
| 2 | 2023-01-03 | 5.8 |
| 3 | 2023-01-04 | 5.8 |
| 4 | 2023-01-05 | 6.5 |
欠損値が多い場合の代替策も検討
dropna()で欠損値を含む行や列を削除したり、fillna()で他の値で埋めたりする方法を見てきました。しかし、データによっては特定の列に非常に多くの欠損値が含まれている場合があります。例えば、ある列のデータの8割以上が欠損しているといったケースです。
このような場合、安易に補完してもデータの持つ本来の情報が失われてしまったり、補完された値が分析結果を歪めてしまう可能性があります。欠損値が極端に多い列については、そもそもその列を分析や機械学習のモデル構築から除外するという選択肢も検討すべきです。 その列が持つ情報量が、欠損によるデメリットを上回らないと判断できる場合です。
また、機械学習のアルゴリズムの中には、欠損値をそのまま扱えるものも存在します(例: LightGBM, XGBoostなどの一部の勾配ブースティング系アルゴリズム)。データセットの特性や使用するモデルに応じて、このようなアルゴリズムを選択することも、欠損値処理の一つのアプローチとなります。
どの方法が最適かは、データセットのサイズ、欠損値の割合、欠損値のパターン、データの種類、そして最終的な分析やモデリングの目的に応じて総合的に判断する必要があります。
この記事で紹介した isnull() や isnull().sum()、そして可視化を通じて、まずはご自身のデータセットの欠損状況をしっかりと把握することが、適切な処理方法を選択するための第一歩となります。
まとめ:isnull(), isnull().sum() をマスターし、欠損値と賢く付き合おう!
今回は、Pandasで欠損値(NaN)を扱うための基本である isnull() と isnull().sum()、そして見つかった欠損値をどのように扱うかの応用的な方法について解説しました。
isnull(): データの中の NaN の位置を確認する。
isnull().sum(): 列ごとの NaN の数を簡単にカウントする。欠損の全体像を把握する最初のステップとして重要!
欠損値の扱い方:
- 削除する (dropna()): 欠損値を含む行や列を思い切って取り除く。データ量が減る可能性がある。
他の値で埋める (fillna()): 特定の値、平均値、中央値、最頻値、直前/直後の値などで補完する。どの値で埋めるかはデータの性質や分析目的に応じて慎重に検討が必要。安易な補完は結果を歪める可能性も!
欠損値が多い場合の代替策: 列の除外、欠損値を扱えるモデルの使用なども選択肢として考える。
これらのメソッドを使いこなすことで、データ分析における欠損値というやっかいな問題に効率的に立ち向かえるようになります。特に、データの前処理や機械学習モデルの構築において、欠損値の適切な処理は不可欠です。
まずはあなたのデータセットで
1. df.isnull().sum() で欠損値の状況を確認してみましょう。
2. 欠損値の割合や種類(数値かカテゴリか)を見て、削除するか補完するかを検討しましょう。
3. 補完する場合は、どの方法が適切か(平均値?最頻値?ffill?など)を考えて実行してみましょう。
データ分析の精度を高めるためには、欠損値との賢い付き合い方が欠かせません。この記事が、その最初の一歩となり、あなたのデータ分析の役に立てば幸いです。