
ビジネスデータ分析の鍵:Pandas groupby() と集計でデータから価値を引き出す!
ビジネスの現場では、膨大なデータの中から意味のある情報を見つけ出し、意思決定に活かすことが不可欠です。「合計売上は?」「どの顧客層が最も貢献しているか?」「ウェブサイトのどのページがよく見られているか?」… これらの問いに答えるためには、「特定のグループごとにデータをまとめる」という集計作業が欠かせません。
Pandas の強力な groupby() 機能を使えば、このような複雑な集計も Python コードで簡単かつ柔軟に行うことができます。カテゴリ別売上、ユーザー別アクセスなど、具体的なビジネスデータの例を通して、Pandas を使ったデータ集計・分析の基本から応用までを分かりやすく解説します。
この記事を読むことで、以下のことができるようになります:
- Pandas の
groupby()を使ってデータを効率的にグループ化する。 sum(),mean(),count(),nunique()といった基本的な集計を適用する。agg()を使って、カラムごとに異なる、あるいは複数の集計を一度に行う。- 実務データを集計・分析し、そこからビジネス的な洞察を得る。
▶️ 公式ドキュメントも参考にしてください:
- pandas DataFrame.groupby Documentation
- pandas GroupBy.agg Documentation
- pandas DataFrame.mean Documentation
- pandas DataFrame.sum Documentation
サンプルデータの作成
まずは「カテゴリ別売上集計」の例として、架空の売上データを作成します。
import pandas as pd
# サンプル売上データ
data = {
'category': ['A', 'B', 'A', 'C', 'B', 'A', 'C', 'B'],
'item': ['apple', 'banana', 'orange', 'apple', 'orange', 'banana', 'apple', 'banana'],
'price': [100, 200, 150, 120, 180, 210, 130, 190],
'quantity': [2, 1, 3, 1, 2, 1, 2, 1]
}
df_sales = pd.DataFrame(data)
print("元の売上データ:")
display(df_sales)
元の売上データ:
| category | item | price | quantity | |
|---|---|---|---|---|
| 0 | A | apple | 100 | 2 |
| 1 | B | banana | 200 | 1 |
| 2 | A | orange | 150 | 3 |
| 3 | C | apple | 120 | 1 |
| 4 | B | orange | 180 | 2 |
| 5 | A | banana | 210 | 1 |
| 6 | C | apple | 130 | 2 |
| 7 | B | banana | 190 | 1 |
📌 基本:groupby()によるデータのグループ化
このセクションでは、データ集計の第一歩となる groupby() メソッドの基本的な使い方を学びます。groupby() は、指定した一つ以上の列の値に基づいてデータをグループに分割する機能です。このグループ化されたオブジェクトに対して、後続の集計処理を適用します。
データフレームをグループ化することで、各グループに対して個別に集計処理を適用する準備が整います。
# category列でグループ化
grouped = df_sales.groupby('category')
print(grouped)
この状態ではまだ集計は行われていません。続いて集計メソッドを適用します。
📊 単一集計:sum() / mean() / count() / nunique()
groupby()でデータをグループ化した後、各グループに対して集計処理を行います。Pandasでは、よく使う「合計」「平均」「カウント」「ユニーク数のカウント」といった単一の集計は、専用のショートカットメソッドで簡単に計算可能です。
sum(): グループ内の合計値を計算します。mean(): グループ内の平均値を計算します。count(): グループ内の非欠損値の数をカウントします。nunique(): グループ内のユニークな要素の数をカウントします。
これらのメソッドを使うことで、各グループの基本的な要約統計量を素早く把握できます。
# sum
sales_sum = grouped[['price', 'quantity']].sum()
print("カテゴリ別 合計値:")
display(sales_sum)
# mean
sales_mean = grouped[['price', 'quantity']].mean()
print("カテゴリ別 平均値:")
display(sales_mean)
# count
print("カテゴリ別 項目数 (count):")
display(grouped.count())
# nunique
print("カテゴリ別 ユニークアイテム数 (nunique):")
display(grouped['item'].nunique())
print("カテゴリ別 ユニークな価格数 (nunique):")
display(grouped['price'].nunique())
カテゴリ別 合計値:
| price | quantity | |
|---|---|---|
| category | ||
| A | 460 | 6 |
| B | 570 | 4 |
| C | 250 | 3 |
| price | quantity | |
|---|---|---|
| category | ||
| A | 153.333333 | 2.000000 |
| B | 190.000000 | 1.333333 |
| C | 125.000000 | 1.500000 |
カテゴリ別 項目数(count):
| item | price | quantity | |
|---|---|---|---|
| category | |||
| A | 3 | 3 | 3 |
| B | 3 | 3 | 3 |
| C | 2 | 2 | 2 |
| item | |
|---|---|
| category | |
| A | 3 |
| B | 2 |
| C | 1 |
カテゴリ別 ユニークな価格数(nunique):
| price | |
|---|---|
| category | |
| A | 3 |
| B | 3 |
| C | 2 |
(⚠️注意) グループ化されたデータフレームに対して grouped.sum() や grouped.mean() のような集計関数を適用する際、文字列型のデータが含まれているとエラーが発生することがあります。例えば、grouped.mean()は数値データにのみ有効であるため、数値データである price や quantity の列を指定して、grouped[[‘price’, ‘quantity’]]を実行します。なお、複数列を扱うため、[[ ]]にする必要があります。
# 下記の平均を実行すると、item列が文字列データのためエラーが出ます。
sales_mean = grouped.mean()
print("カテゴリ別 平均値:")
display(sales_mean)
🔧 応用:agg()で複数集計を一度に
agg() メソッドは、groupby() と組み合わせて使うことで、より柔軟な集計を可能にします。agg()を使うと、カラムごとに異なる集計関数を一度に適用したり、同じカラムに対して複数の集計関数を適用したりできます。これは、データフレーム全体の要約統計量を一度に計算したい場合に非常に便利です。Pandas に組み込まれている集計関数だけでなく、NumPy の関数や、独自のカスタム関数を使うことも可能です。
agg() を使いこなすことで、複雑な集計ニーズにも柔軟に対応できるようになります。
# 複数集計例1:quantityの合計、priceの平均・最大・最小
result1 = grouped.agg({
'quantity': 'sum',
'price': ['mean', 'max', 'min']
})
print("カテゴリ別 複数集計1:")
display(result1)
カテゴリ別 複数集計1:
| quantity | price | |||
|---|---|---|---|---|
| sum | mean | max | min | |
| category | ||||
| A | 6 | 153.333333 | 210 | 100 |
| B | 4 | 190.000000 | 200 | 180 |
| C | 3 | 125.000000 | 130 | 120 |
# 複数集計2: quantityの合計と平均、priceの平均と中央値
result2 = grouped.agg({
'quantity': ['sum', 'mean'],
'price': ['mean', 'median']
})
print("カテゴリ別 複数集計2:")
display(result2)
カテゴリ別 複数集計2:
| quantity | price | |||
|---|---|---|---|---|
| sum | mean | mean | median | |
| category | ||||
| A | 6 | 2.000000 | 153.333333 | 150.0 |
| B | 4 | 1.333333 | 190.000000 | 190.0 |
| C | 3 | 1.500000 | 125.000000 | 125.0 |
実務例①:カテゴリ別売上データの分析
ここでは、架空の売上データを使って、カテゴリ別の売上金額や商品の多様性について分析を行います。ビジネスの現場で最も頻繁に行われる分析の一つです。
分析のポイント: * 売上金額 = price × quantity を計算する。 * カテゴリ別に売上金額の合計を集計する。 * カテゴリ別に商品の種類(ユニーク項目数)や価格帯の多様性(ユニーク価格数)を集計する。 * これらの集計結果から、各カテゴリの特徴や改善点を探る。
# 売上金額列(revenue)を追加
df_sales['revenue'] = df_sales['price'] * df_sales['quantity']
print("売上金額列追加:")
display(df_sales)
# revenueの合計をカテゴリ別に集計
cat_rev = df_sales.groupby('category')['revenue'].sum()
print("カテゴリ別 売上合計:")
display(cat_rev)
# category列を通常の列に戻す
cat_rev = cat_rev.reset_index()
print("カテゴリ別 売上合計:")
display(cat_rev)
売上金額列追加:
| category | item | price | quantity | revenue | |
|---|---|---|---|---|---|
| 0 | A | apple | 100 | 2 | 200 |
| 1 | B | banana | 200 | 1 | 200 |
| 2 | A | orange | 150 | 3 | 450 |
| 3 | C | apple | 120 | 1 | 120 |
| 4 | B | orange | 180 | 2 | 360 |
| 5 | A | banana | 210 | 1 | 210 |
| 6 | C | apple | 130 | 2 | 260 |
| 7 | B | banana | 190 | 1 | 190 |
カテゴリ別 売上合計:
| revenue | |
|---|---|
| category | |
| A | 860 |
| B | 750 |
| C | 380 |
カテゴリ別 売上合計:
| category | revenue | |
|---|---|---|
| 0 | A | 860 |
| 1 | B | 750 |
| 2 | C | 380 |
分析結果:カテゴリ別売上合計
カテゴリ別の売上合計を見てみると、カテゴリ A が最も売上が高く 860 円、次いでカテゴリ B が 750 円、カテゴリ C が 380 円となっています(下図参照)。これは、カテゴリ A と B がより多くの商品を提供しているか、あるいは高価な商品を扱っている可能性を示唆しています。カテゴリ C は他のカテゴリに比べて売上が低い傾向にあることが分かります。
!pip install japanize-matplotlib # Google Colabなどで簡単に日本語表示を可能にするライブラリ
import japanize_matplotlib
# カテゴリ別売上合計を棒グラフで可視化
plt.figure(figsize=(8, 5))
plt.bar(cat_rev['category'], cat_rev['revenue'], color=['skyblue', 'lightcoral', 'lightgreen'])
plt.title('カテゴリ別 売上合計')
plt.xlabel('カテゴリ')
plt.ylabel('売上合計 (円)')
plt.grid(axis='y', linestyle='--')
plt.show()

分析結果:カテゴリ別商品の多様性と価格帯
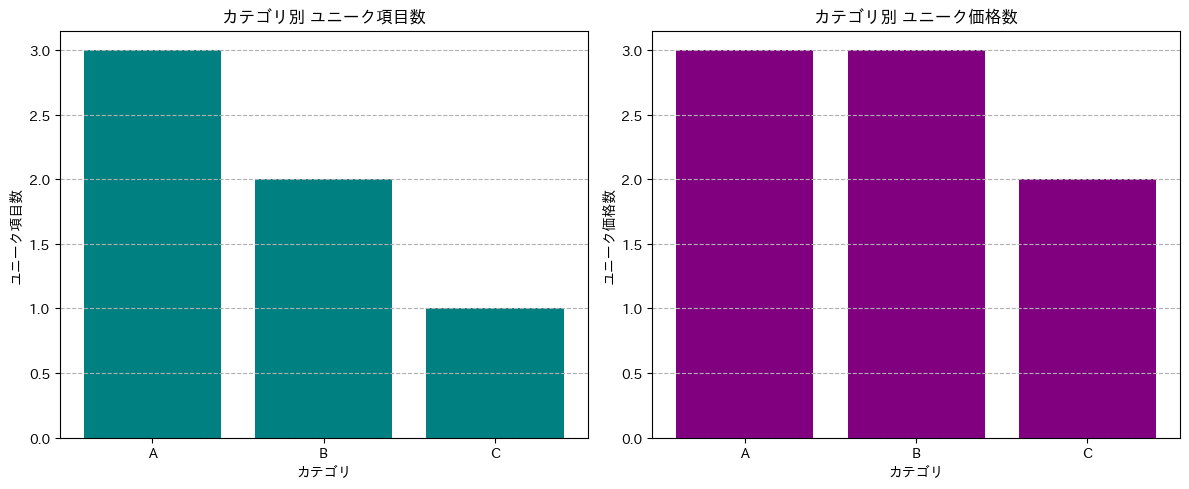
次に、カテゴリごとの商品の多様性(ユニーク項目数)と価格帯の多様性(ユニーク価格数)を見てみましょう。
カテゴリ別のユニーク項目数とユニーク価格数を見ると、カテゴリ A はユニーク項目数が 3 つ、ユニーク価格数が 3 つとなっており、比較的多くの種類の商品を、多様な価格帯で扱っていることが分かります(下図参照)。カテゴリ B はユニーク項目数が 2 つ、ユニーク価格数が 3 つとなっており、カテゴリ A と同様に多様な価格帯で商品を扱っていますが、項目数はやや少ないです。一方、カテゴリ C はユニーク項目数が 1 つ、ユニーク価格数が 2 つとなっており、提供している商品の種類が少なく、価格帯も限定的であることが示唆されます。
import matplotlib.pyplot as plt
import pandas as pd
# サンプル売上データ (df_salesの再作成)
data = {
'category': ['A', 'B', 'A', 'C', 'B', 'A', 'C', 'B'],
'item': ['apple', 'banana', 'orange', 'apple', 'orange', 'banana', 'apple', 'banana'],
'price': [100, 200, 150, 120, 180, 210, 130, 190],
'quantity': [2, 1, 3, 1, 2, 1, 2, 1]
}
df_sales = pd.DataFrame(data)
# カテゴリ別ユニーク項目数と価格数を再度計算
grouped = df_sales.groupby('category')
unique_item_counts = grouped['item'].nunique()
unique_price_counts = grouped['price'].nunique()
# カテゴリ別ユニーク項目数と価格数を可視化
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# ユニーク項目数
axes[0].bar(unique_item_counts.index, unique_item_counts.values, color='teal')
axes[0].set_title('カテゴリ別 ユニーク項目数')
axes[0].set_xlabel('カテゴリ')
axes[0].set_ylabel('ユニーク項目数')
axes[0].grid(axis='y', linestyle='--')
# ユニーク価格数
axes[1].bar(unique_price_counts.index, unique_price_counts.values, color='purple')
axes[1].set_title('カテゴリ別 ユニーク価格数')
axes[1].set_xlabel('カテゴリ')
axes[1].set_ylabel('ユニーク価格数')
axes[1].grid(axis='y', linestyle='--')
plt.tight_layout()
plt.show()
実務例①のまとめ
カテゴリ別の売上、商品の種類、価格帯の分析から、各カテゴリの強みや課題が見えてきました。カテゴリ A と B は多様な商品を扱っており売上も高い一方、カテゴリ C は売上が低く、商品ラインナップや価格戦略の見直しが必要かもしれません。
実務例②:ユーザー別アクセスデータの分析
次に、ウェブサイトのアクセスログデータを使って、ユーザーごとの行動を分析する例を見てみましょう。ユーザーのアクセス回数、ユニークな閲覧ページ数、サイト滞在時間などを集計することで、ユーザーのエンゲージメントやサイトへの関心度を測ることができます。
分析のポイント: * ユーザーごとにアクセス回数をカウントする。 * 各ユーザーがアクセスしたユニークなページ数をカウントする。 * ユーザーごとのサイト滞在時間(セッション時間)を計算する(簡易版)。 * これらの集計結果から、ユーザーの行動パターンやエンゲージメントレベルを把握する。
# サンプルアクセスログ
data2 = {
'user_id': [101, 102, 101, 103, 102, 101],
'page': ['A','B','A','A','C','B'],
'timestamp': pd.date_range('2025-01-01', periods=6, freq='H')
}
df_log = pd.DataFrame(data2)
print("元のアクセスログ:")
display(df_log)
# ユーザーごとのアクセス回数をカウント
access_count = df_log.groupby('user_id').size().reset_index(name='count')
print("ユーザー別 アクセス回数:")
display(access_count)
# 各ユーザーがアクセスしたユニークなページ数をカウント
unique_pages_per_user = df_log.groupby('user_id')['page'].nunique()
print("ユーザー別 ユニークなページ数:")
display(unique_pages_per_user)
元のアクセスログ:
| user_id | page | timestamp | |
|---|---|---|---|
| 0 | 101 | A | 2025-01-01 00:00:00 |
| 1 | 102 | B | 2025-01-01 01:00:00 |
| 2 | 101 | A | 2025-01-01 02:00:00 |
| 3 | 103 | A | 2025-01-01 03:00:00 |
| 4 | 102 | C | 2025-01-01 04:00:00 |
| 5 | 101 | B | 2025-01-01 05:00:00 |
ユーザー別 アクセス回数:
| user_id | count | |
|---|---|---|
| 0 | 101 | 3 |
| 1 | 102 | 2 |
| 2 | 103 | 1 |
ユーザー別 ユニークなページ数:
| page | |
|---|---|
| user_id | |
| 101 | 2 |
| 102 | 2 |
| 103 | 1 |
コードの解説
コードの解説
- サンプルアクセスログデータの作成:
- data2 = { … }: ユーザー ID、アクセスしたページ、タイムスタンプを含む辞書を作成しています。これがアクセスログの元データとなります。
- ‘timestamp’: pd.date_range(‘2025-01-01′, periods=6, freq=’H’): ここで Pandas の機能を使って、2025 年 1 月 1 日から 1 時間おきに 6 つのタイムスタンプ(日時データ)を自動的に生成しています。`freq=’H’`は「1 時間ごと」を意味します。
- Pandas DataFrame の作成:
- df_log = pd.DataFrame(data2): 上記で作成した辞書`data2`を使って、Pandas の DataFrame `df_log` を作成しています。これにより、表形式のデータとして扱いやすくなります。
- 元のアクセスログの表示:
- print(“元のアクセスログ:”): 見出しを表示します。
- display(df_log): 作成した DataFrame `df_log` の内容を表示します。
- ユーザーごとのアクセス回数のカウント:
- df_log.groupby(‘user_id’): DataFrame を ‘user_id’ 列の値でグループ化します。これにより、同じユーザー ID を持つ行がまとめて扱えるようになります。
- .size(): グループ化された各グループ(各ユーザー)に含まれる行数、つまりそのユーザーのアクセス回数をカウントします。
- .reset_index(name=’count’): `size()`の結果はデフォルトでは Series 形式で、ユーザー ID がインデックスになっています。これを DataFrame に変換し、カウント数の列に ‘count’ という名前を付けています。
- access_count = …: 結果を `access_count` という新しい DataFrame に格納しています。
- print(“ユーザー別 アクセス回数:”): 見出しを表示します。
- display(access_count): ユーザー別アクセス回数が格納された DataFrame `access_count` を表示します。
- 各ユーザーがアクセスしたユニークなページ数のカウント:
- df_log.groupby(‘user_id’): 再度、DataFrame を ‘user_id’ 列でグループ化します。
- [‘page’]: グループ化された DataFrame から、’page’ 列を選択しています。
- .nunique(): 各ユーザーグループの ‘page’ 列に含まれる値の中で、ユニーク(重複しない)な値の数をカウントします。これにより、各ユーザーが何種類のページを見たかが分かります。
- unique_pages_per_user = …: 結果を `unique_pages_per_user` という Series に格納しています。
- print(“ユーザー別 ユニークなページ数:”): 見出しを表示します。
- display(unique_pages_per_user): ユーザー別ユニークページ数が格納された Series `unique_pages_per_user` を表示します。
ユーザー別セッション時間集計
タイムスタンプを使って、ユーザーごとの滞在時間やセッション時間(簡易版)を計算します。(※サンプルデータがシンプルなので簡易的なものになります)
# 'user_id'でグループ化し、timestampの最大値と最小値を計算
session_times = df_log.groupby('user_id')['timestamp'].agg(['min', 'max'])
# 簡易的なセッション時間を計算 (最大値 - 最小値)
session_times['duration'] = session_times['max'] - session_times['min']
print("ユーザー別 簡易セッション時間:")
display(session_times)
ユーザー別 簡易セッション時間::
| min | max | duration | |
|---|---|---|---|
| user_id | |||
| 101 | 2025-01-01 00:00:00 | 2025-01-01 05:00:00 | 0 days 05:00:00 |
| 102 | 2025-01-01 01:00:00 | 2025-01-01 04:00:00 | 0 days 03:00:00 |
| 103 | 2025-01-01 03:00:00 | 2025-01-01 03:00:00 | 0 days 00:00:00 |
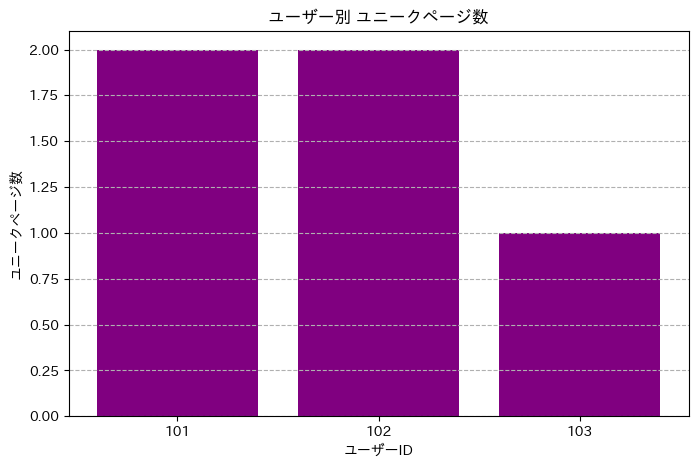
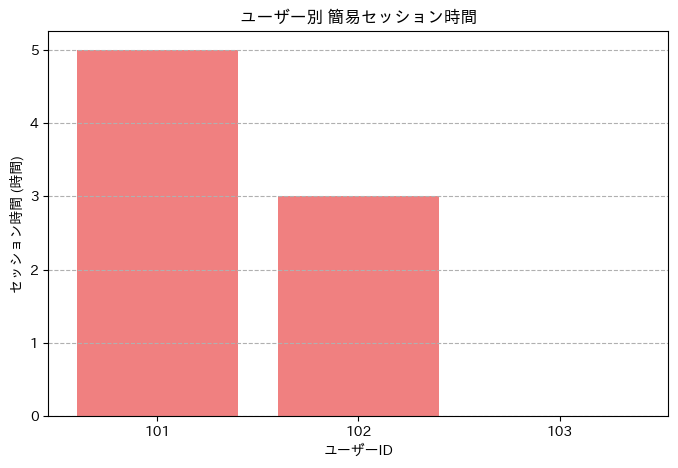
分析結果:ユーザー別アクセスデータ
ユーザーごとのアクセス回数、ユニークページ数、簡易セッション時間の集計結果から、以下の点が分かります。
- ユーザー 101: アクセス回数が最も多く(3 回)、ユニークページ数も 2 つと複数ページを閲覧しています。セッション時間も 5 時間と最も長いです。これは、ユーザー 101 がサイトに対して最も活発で、複数のコンテンツに興味を持っている可能性を示唆しています(下図参照)。
- ユーザー 102: アクセス回数は 2 回、ユニークページ数も 2 つです。セッション時間は 3 時間です。ユーザー 101 ほどではありませんが、複数のページを閲覧しており、一定のエンゲージメントがあると考えられます。
- ユーザー 103: アクセス回数は 1 回、ユニークページ数も 1 つです。セッション時間も 0 時間となっています(アクセスが 1 回のみのため)。これは、ユーザー 103 が特定のページに一度だけアクセスしただけで、現時点ではサイトへの関心が低いか、目的の情報にすぐにたどり着いた可能性が考えられます。
これらの結果から、ユーザーの行動パターンに違いがあることが分かりました。アクセス回数が多いユーザーは、より多くのページを閲覧し、サイトに長く滞在する傾向があるようです(下図参照)。
ここでいう「エンゲージメント」とは、ユーザーがウェブサイトやサービスにどれだけ積極的に関与しているか、興味を持っているかを示す指標です。アクセス回数が多い、色々なページを見ている、滞在時間が長いといった行動は、エンゲージメントが高いと解釈できます。
import matplotlib.pyplot as plt
# ユーザー別アクセス回数を棒グラフで可視化
plt.figure(figsize=(8, 5))
plt.bar(access_count['user_id'].astype(str), access_count['count'], color='teal')
plt.title('ユーザー別 アクセス回数')
plt.xlabel('ユーザーID')
plt.ylabel('アクセス回数')
plt.grid(axis='y', linestyle='--')
plt.show()

# ユーザー別ユニークページ数を棒グラフで可視化
plt.figure(figsize=(8, 5))
plt.bar(unique_pages_per_user.index.astype(str), unique_pages_per_user.values, color='purple')
plt.title('ユーザー別 ユニークページ数')
plt.xlabel('ユーザーID')
plt.ylabel('ユニークページ数')
plt.grid(axis='y', linestyle='--')
plt.show()
# ユーザー別簡易セッション時間を棒グラフで可視化
# durationを時間単位に変換
session_times['duration_hours'] = session_times['duration'].dt.total_seconds() / 3600
plt.figure(figsize=(8, 5))
plt.bar(session_times.index.astype(str), session_times['duration_hours'], color='lightcoral')
plt.title('ユーザー別 簡易セッション時間')
plt.xlabel('ユーザーID')
plt.ylabel('セッション時間 (時間)')
plt.grid(axis='y', linestyle='--')
plt.show()
実務例②のまとめ
ユーザー行動の分析から、ユーザーによってサイトへの関心度や利用方法が異なることが明らかになりました。特にアクセス回数が少なく滞在時間も短いユーザーに対して、サイトへの再訪やエンゲージメントを高めるための施策を検討することが重要です。
まとめ
今回は、Pandas の groupby() および agg(), sum(), mean(), count(), nunique() といった集計関数を使ったデータのグループ化と要約について学びました。
groupby()を使用して、指定したキー列に基づいてデータを効率的にグループ化できることを確認しました。sum(),mean(),count(),nunique()といった基本的な集計関数を使って、各グループの合計、平均、要素数、ユニーク数を簡単に計算できることを学びました。数値データ以外の列に対して集計関数を適用する際には注意が必要であることも確認しました。agg()を使うことで、単一または複数の列に対して、複数の集計関数を一度に適用できる柔軟な集計方法を習得しました。- 実務例として、「カテゴリ別売上集計」と「ユーザー別アクセス数集計」を通して、これらの集計方法がビジネスデータの分析にどのように役立つか具体的なイメージを持つことができました。売上金額の計算、ユーザーのアクセス回数やユニークページ数、簡易的なセッション時間の集計と、そこから得られる示唆について考察を行いました。
- 集計結果を棒グラフで可視化することで、データの傾向やユーザー行動のパターンをより直感的に理解できることを示しました。
これらの Pandas の強力な集計機能を使いこなすことで、ビジネスデータの分析やレポート作成が効率的に行えるようになります。
コメント