Pandasで前処理をしていると、次のような場面で迷うことがあります。
- 60点以上の点数だけ残し、60点未満は欠損値として扱いたい
- 売上がマイナスになっている不自然な値だけ、0やNaNにしたい
- 年齢が120歳を超えるような確認が必要な値だけ、欠損値にしたい
replace()、loc、where()、mask()のどれを使えばよいかわからない
最初に結論を言うと、where()は「条件を満たす値を残す」ために使い、mask()は「条件を満たす値を置き換える」ために使います。
言い換えると、次のように考えると分かりやすいです。
| 使いたい場面 | 使うメソッド |
|---|---|
| 条件を満たす値を残したい | where() |
| 条件を満たす値を置き換えたい | mask() |
| 特定の値そのものを置き換えたい | replace() |
| 欠損値だけを埋めたい | fillna() |
| 条件に合う行を取り出したい | 条件抽出・loc |
この記事では、Google Colabでそのまま試せる小さなDataFrameを使いながら、where()とmask()の違い、使いどころ、よくあるミスを初心者向けに整理します。
- この記事でわかること
- Pandas前処理の中での位置づけ
- where()とmask()の判断基準
- サンプルデータを用意する
- where()の基本:条件を満たす値を残す
- where()で条件に合わない値を別の値に置き換える
- mask()の基本:条件を満たす値を置き換える
- where()とmask()の違いを同じデータで比較する
- 複数条件でwhere()を使う場合
- 補足:DataFrame全体にもwhere()・mask()は使える
- where()・mask()・replace()・fillna()・locの使い分け
- locでの条件代入との違い
- 新しい列として結果を残すと確認しやすい
- よくあるミス1:代入しないと元のDataFrameは変わらない
- よくあるミス2:条件式の向きが逆になる
- 条件に合わない値をNaNにしたあとの流れ
- np.where()には軽く触れる程度でよい
- データ分析の流れではどこで使うか
- まとめ
- 次に読みたい関連記事
この記事でわかること
この記事では、次の内容を学びます。
where()の基本的な使い方mask()の基本的な使い方where()とmask()の違い- 条件に合わない値を
NaNにする方法 NaNにしたときに整数列が小数表示になる理由- 条件に応じて別の値に置き換える方法
loc、replace()、fillna()、np.where()との使い分け- 初心者が間違えやすい条件式の向き
Pandas前処理の中での位置づけ
where()とmask()は、DataFrameを確認したあとに、条件に応じて値を整える前処理で役立ちます。
たとえば、次のような流れです。
info()やdescribe()でデータの型・欠損値・統計量を確認するunique()やvalue_counts()で値の中身を確認するreplace()で表記ゆれを直すwhere()やmask()で条件に合わない値・確認が必要な値を整理するfillna()で欠損値を補うgroupby()やグラフで集計・可視化する
つまり、where()とmask()は、集計や可視化の前に、条件に応じて値を整えるための道具です。
where()とmask()の判断基準
まず、where()とmask()の違いを先に押さえます。
| メソッド | 考え方 | 例 |
|---|---|---|
where(条件) |
条件を満たす値を残す | 60点以上だけ残す |
mask(条件) |
条件を満たす値を置き換える | 60点未満をNaNにする |
特に初心者が混乱しやすいのは、条件に合う値をどうしたいのかです。
- 条件に合う値を残したい →
where() - 条件に合う値を消したい・置き換えたい →
mask()
この記事では、まず同じサンプルデータを使って、where()とmask()の動きを確認していきます。
サンプルデータを用意する
ここでは、テスト点数、売上、年齢を持つ小さなDataFrameを使います。
売上の-500は、今回の例では「本来はマイナスにならないはずの入力ミス」として扱います。
年齢の135も、今回の例では「確認が必要な値」として扱います。
import pandas as pd
df = pd.DataFrame({
"名前": ["田中", "佐藤", "鈴木", "高橋", "伊藤", "山本"],
"点数": [82, 55, 91, 47, 60, 73],
"売上": [12000, -500, 18500, 0, 9200, 15000],
"年齢": [24, 31, 135, 28, 42, 19]
})
df| 名前 | 点数 | 売上 | 年齢 | |
|---|---|---|---|---|
| 0 | 田中 | 82 | 12000 | 24 |
| 1 | 佐藤 | 55 | -500 | 31 |
| 2 | 鈴木 | 91 | 18500 | 135 |
| 3 | 高橋 | 47 | 0 | 28 |
| 4 | 伊藤 | 60 | 9200 | 42 |
| 5 | 山本 | 73 | 15000 | 19 |
このDataFrameでは、次のような前処理を考えます。
| 列 | 確認したいこと | 処理例 |
|---|---|---|
| 点数 | 60点以上だけ残したい | 60点未満をNaNにする |
| 売上 | マイナスの売上を整理したい | 負の値を0またはNaNにする |
| 年齢 | 120歳を超える値を確認対象にしたい | 120歳超をNaNにする |
実務でも、CSVやExcelを読み込んだあとに、このような「条件に応じた値の整理」が必要になることがあります。
where()の基本:条件を満たす値を残す
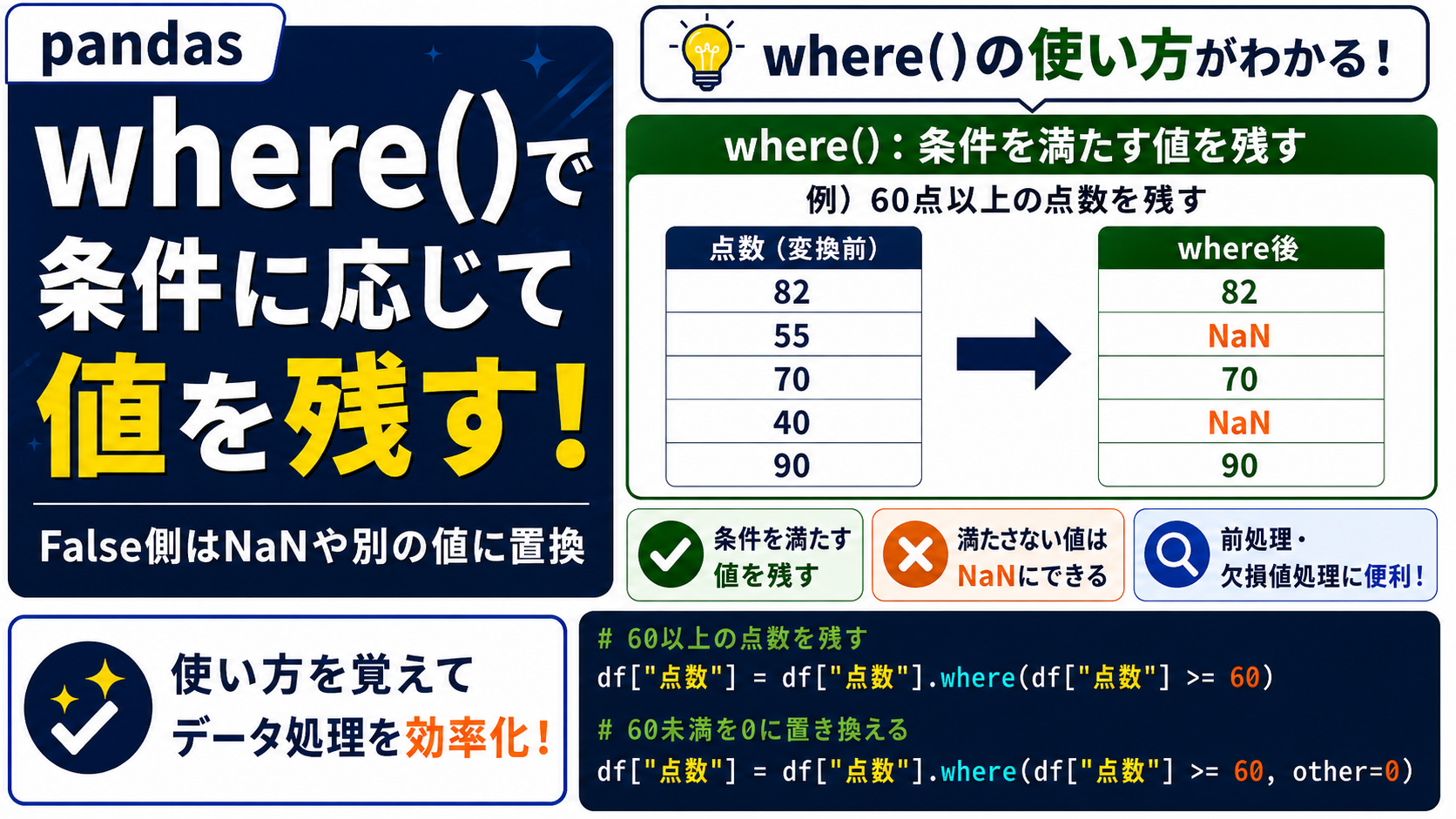
where()は、条件を満たす値を残し、条件を満たさない値を置き換えるメソッドです。
基本形は次のように考えます。
Series.where(条件, other=置き換える値)
otherを指定しない場合、条件を満たさない値はNaNになります。
Series.where(条件)
ここでは、点数が60点以上の値だけを残し、60点未満をNaNにしてみます。
df["点数_where"] = df["点数"].where(df["点数"] >= 60)
df[["名前", "点数", "点数_where"]]| 名前 | 点数 | 点数_where | |
|---|---|---|---|
| 0 | 田中 | 82 | 82.0 |
| 1 | 佐藤 | 55 | NaN |
| 2 | 鈴木 | 91 | 91.0 |
| 3 | 高橋 | 47 | NaN |
| 4 | 伊藤 | 60 | 60.0 |
| 5 | 山本 | 73 | 73.0 |
上のコードでは、df["点数"] >= 60という条件を満たす値だけが残ります。
| 元の点数 | 条件 | 結果 |
|---|---|---|
| 82 | 60点以上 | 82 |
| 55 | 60点未満 | NaN |
| 91 | 60点以上 | 91 |
| 47 | 60点未満 | NaN |
| 60 | 60点以上 | 60 |
| 73 | 60点以上 | 73 |
ここで大切なのは、where()は「条件に合う値を置き換える」のではなく、条件に合う値を残すという点です。
補足:NaNが入ると小数表示になることがある
where()やmask()でNaNを作ると、整数だった列が82.0のように小数で表示されることがあります。
これは、NaNが欠損値を表すため、整数だけの列にNaNが混ざると、Pandasが列全体を小数型として扱うことがあるためです。
そのため、結果が82.0のように表示されても、処理が間違っているとは限りません。まずは、どの値が残り、どの値がNaNになったかを確認しましょう。
where()で条件に合わない値を別の値に置き換える
where()では、otherを指定すると、条件を満たさない値を別の値に置き換えられます。
Series.where(残したい条件, other=条件に合わないときの値)
ここでは、売上が0以上ならそのまま残し、0未満の売上を0に置き換えます。
df["売上_where_0"] = df["売上"].where(df["売上"] >= 0, other=0)
df[["名前", "売上", "売上_where_0"]]| 名前 | 売上 | 売上_where_0 | |
|---|---|---|---|
| 0 | 田中 | 12000 | 12000 |
| 1 | 佐藤 | -500 | 0 |
| 2 | 鈴木 | 18500 | 18500 |
| 3 | 高橋 | 0 | 0 |
| 4 | 伊藤 | 9200 | 9200 |
| 5 | 山本 | 15000 | 15000 |
この例では、売上が0以上の値はそのまま残り、-500だけが0に置き換わりました。
| 処理前の売上 | 条件 | 処理後 |
|---|---|---|
| 12000 | 0以上 | 12000 |
| -500 | 0未満 | 0 |
| 18500 | 0以上 | 18500 |
| 0 | 0以上 | 0 |
| 9200 | 0以上 | 9200 |
| 15000 | 0以上 | 15000 |
0は今回のデータでは「売上がなかった」という意味のある値として残しています。
一方、-500は「本来はマイナスにならない想定の売上」として、確認・修正対象にしています。
mask()の基本:条件を満たす値を置き換える
mask()は、where()とは逆に、条件を満たす値を置き換えるメソッドです。
基本形は次のように考えます。
Series.mask(条件, other=置き換える値)
otherを指定しない場合、条件を満たす値はNaNになります。
Series.mask(条件)
ここでは、年齢が120歳を超える値を確認対象として、NaNにします。
df["年齢_mask"] = df["年齢"].mask(df["年齢"] > 120)
df[["名前", "年齢", "年齢_mask"]]| 名前 | 年齢 | 年齢_mask | |
|---|---|---|---|
| 0 | 田中 | 24 | 24.0 |
| 1 | 佐藤 | 31 | 31.0 |
| 2 | 鈴木 | 135 | NaN |
| 3 | 高橋 | 28 | 28.0 |
| 4 | 伊藤 | 42 | 42.0 |
| 5 | 山本 | 19 | 19.0 |
この例では、年齢 > 120という条件を満たす135だけがNaNになりました。
| 元の年齢 | 条件 | 結果 |
|---|---|---|
| 24 | 120以下 | 24 |
| 31 | 120以下 | 31 |
| 135 | 120超 | NaN |
| 28 | 120以下 | 28 |
| 42 | 120以下 | 42 |
| 19 | 120以下 | 19 |
mask()は、条件に合う値を隠す・置き換えるイメージで使うと理解しやすいです。
where()とmask()の違いを同じデータで比較する
where()とmask()は、条件の向きを逆にすると同じ結果を作れることがあります。
たとえば、次の2つはどちらも「60点未満をNaNにする」処理です。
where(df["点数"] >= 60):60点以上を残すmask(df["点数"] < 60):60点未満を置き換える
同じデータで比較してみましょう。
compare = pd.DataFrame({
"名前": df["名前"],
"元の点数": df["点数"],
"where_60点以上を残す": df["点数"].where(df["点数"] >= 60),
"mask_60点未満をNaN": df["点数"].mask(df["点数"] < 60)
})
compare| 名前 | 元の点数 | where_60点以上を残す | mask_60点未満をNaN | |
|---|---|---|---|---|
| 0 | 田中 | 82 | 82.0 | 82.0 |
| 1 | 佐藤 | 55 | NaN | NaN |
| 2 | 鈴木 | 91 | 91.0 | 91.0 |
| 3 | 高橋 | 47 | NaN | NaN |
| 4 | 伊藤 | 60 | 60.0 | 60.0 |
| 5 | 山本 | 73 | 73.0 | 73.0 |
結果を見ると、where()とmask()で同じような結果になっています。
ただし、考え方は逆です。
| 書き方 | 条件の意味 | 何が起きるか |
|---|---|---|
where(df["点数"] >= 60) |
60点以上なら残す | 条件を満たさない60点未満がNaN |
mask(df["点数"] < 60) |
60点未満なら置き換える | 条件を満たす60点未満がNaN |
迷ったときは、次のように判断してください。
- 残したい条件を書きたい →
where() - 置き換えたい条件を書きたい →
mask()
複数条件でwhere()を使う場合
where()やmask()では、複数条件も指定できます。
複数条件を書くときは、次の点に注意します。
- それぞれの条件を
()で囲む - AND条件は
&でつなぐ - OR条件は
|でつなぐ
ここでは、点数が60点以上かつ90点以下の値だけを残してみます。
df["点数_60から90"] = df["点数"].where((df["点数"] >= 60) & (df["点数"] <= 90))
df[["名前", "点数", "点数_60から90"]]| 名前 | 点数 | 点数_60から90 | |
|---|---|---|---|
| 0 | 田中 | 82 | 82.0 |
| 1 | 佐藤 | 55 | NaN |
| 2 | 鈴木 | 91 | NaN |
| 3 | 高橋 | 47 | NaN |
| 4 | 伊藤 | 60 | 60.0 |
| 5 | 山本 | 73 | 73.0 |
この例では、60点以上かつ90点以下の値だけが残ります。
55や47は60点未満なのでNaNになり、91は90点を超えているためNaNになります。
複数条件は便利ですが、初心者のうちは条件式が長くなりやすいです。
まずは単一条件でwhere()とmask()の考え方を理解し、そのあと複数条件に進むと分かりやすくなります。
補足:DataFrame全体にもwhere()・mask()は使える
ここまでの例では、df["点数"]のように1つの列に対してwhere()やmask()を使いました。
実は、DataFrame全体に対しても使えます。
ただし、初心者のうちは、まず1つの列ごとに処理するほうが結果を確認しやすいです。
ここでは、数値列だけを取り出して、0以上の値を残し、0未満の値をNaNにしてみます。
numeric_df = df[["点数", "売上", "年齢"]]
numeric_df.where(numeric_df >= 0)| 点数 | 売上 | 年齢 | |
|---|---|---|---|
| 0 | 82 | 12000.0 | 24 |
| 1 | 55 | NaN | 31 |
| 2 | 91 | 18500.0 | 135 |
| 3 | 47 | 0.0 | 28 |
| 4 | 60 | 9200.0 | 42 |
| 5 | 73 | 15000.0 | 19 |
このように、DataFrame.where()を使うと、DataFrame内の各値に対して条件を確認できます。
同じ考え方で、DataFrame.mask()もDataFrame全体に使えます。ただし、初心者のうちは、まず1列ずつ処理して結果を確認するほうが安全です。
ただし、実際の記事や学習では、最初からDataFrame全体に使うよりも、
df["列名"].where(条件)
のように、対象の列を決めてから使うほうがミスに気づきやすいです。
where()・mask()・replace()・fillna()・locの使い分け
where()やmask()で迷う理由は、似たような処理をするメソッドが多いからです。
ここでは、初心者が特に迷いやすいメソッドを整理します。
| やりたいこと | 向いている方法 | 例 |
|---|---|---|
| 条件を満たす値を残したい | where() |
60点以上だけ残す |
| 条件を満たす値を置き換えたい | mask() |
120歳超をNaNにする |
| 特定の値そのものを置き換えたい | replace() |
"未入力"をNaNにする |
| すでにある欠損値を埋めたい | fillna() |
NaNを0で埋める |
| 条件に合う行を取り出したい | 条件抽出・loc |
売上が10000以上の行を抽出する |
| 条件に合う場所へ代入したい | loc |
売上が0未満の行だけ0を代入する |
| 条件に応じて新しい列を作りたい | np.where()、assign()、loc |
合格・不合格列を作る |
この記事では、中心をwhere()とmask()に絞ります。
replace()は値そのものの置換、fillna()は欠損値を埋める処理、locは行・列を指定する処理として分けて考えると整理しやすくなります。
locでの条件代入との違い
locを使っても、条件に合う行だけ値を変更できます。
たとえば、売上が0未満の値を0にするなら、次のように書けます。
df_loc = df.copy()
df_loc.loc[df_loc["売上"] < 0, "売上"] = 0
df_loc[["名前", "売上"]]| 名前 | 売上 | |
|---|---|---|
| 0 | 田中 | 12000 |
| 1 | 佐藤 | 0 |
| 2 | 鈴木 | 18500 |
| 3 | 高橋 | 0 |
| 4 | 伊藤 | 9200 |
| 5 | 山本 | 15000 |
locは、条件に合う行と列を指定して、そこへ直接代入するイメージです。
一方、where()は「条件を満たす値を残し、それ以外を置き換えた結果を作る」イメージです。
df_where = df.copy()
df_where["売上"] = df_where["売上"].where(df_where["売上"] >= 0, other=0)
df_where[["名前", "売上"]]| 名前 | 売上 | |
|---|---|---|
| 0 | 田中 | 12000 |
| 1 | 佐藤 | 0 |
| 2 | 鈴木 | 18500 |
| 3 | 高橋 | 0 |
| 4 | 伊藤 | 9200 |
| 5 | 山本 | 15000 |
どちらも同じ結果にできますが、初心者のうちは次のように考えるとよいです。
| 方法 | 向いている場面 |
|---|---|
loc |
条件に合う行・列を明示して代入したい |
where() |
条件を満たす値を残し、それ以外をまとめて置き換えたい |
mask() |
条件を満たす値をまとめて置き換えたい |
この記事の主役はwhere()とmask()なので、locの詳細は別記事で学ぶのがおすすめです。
新しい列として結果を残すと確認しやすい
初心者のうちは、いきなり元の列を上書きするより、新しい列として結果を残すほうが確認しやすいです。
たとえば、売上の元データを残したまま、確認用の列を作ると、処理前後を並べて比較できます。
df_check = df.copy()
df_check["売上_修正案"] = df_check["売上"].where(df_check["売上"] >= 0, other=0)
df_check["年齢_確認用"] = df_check["年齢"].mask(df_check["年齢"] > 120)
df_check[["名前", "売上", "売上_修正案", "年齢", "年齢_確認用"]]| 名前 | 売上 | 売上_修正案 | 年齢 | 年齢_確認用 | |
|---|---|---|---|---|---|
| 0 | 田中 | 12000 | 12000 | 24 | 24.0 |
| 1 | 佐藤 | -500 | 0 | 31 | 31.0 |
| 2 | 鈴木 | 18500 | 18500 | 135 | NaN |
| 3 | 高橋 | 0 | 0 | 28 | 28.0 |
| 4 | 伊藤 | 9200 | 9200 | 42 | 42.0 |
| 5 | 山本 | 15000 | 15000 | 19 | 19.0 |
このように、元の列と処理後の列を並べると、どの値が変わったのかを確認しやすくなります。
特に、公開データや実務データでは、いきなり上書きすると元の状態が分からなくなることがあります。
最初は新しい列に結果を保存し、問題なければ上書きする流れがおすすめです。
よくあるミス1:代入しないと元のDataFrameは変わらない
where()やmask()は、実行しただけでは元のDataFrameを自動で書き換えません。
次のコードでは、where()の結果を表示しているだけなので、元のdf["売上"]は変わりません。
df["売上"].where(df["売上"] >= 0, other=0)
df[["名前", "売上"]]| 名前 | 売上 | |
|---|---|---|
| 0 | 田中 | 12000 |
| 1 | 佐藤 | -500 |
| 2 | 鈴木 | 18500 |
| 3 | 高橋 | 0 |
| 4 | 伊藤 | 9200 |
| 5 | 山本 | 15000 |
元のDataFrameを変更したい場合は、次のように代入します。
df_update = df.copy()
df_update["売上"] = df_update["売上"].where(df_update["売上"] >= 0, other=0)
df_update[["名前", "売上"]]| 名前 | 売上 | |
|---|---|---|
| 0 | 田中 | 12000 |
| 1 | 佐藤 | 0 |
| 2 | 鈴木 | 18500 |
| 3 | 高橋 | 0 |
| 4 | 伊藤 | 9200 |
| 5 | 山本 | 15000 |
where()やmask()で処理した結果を残したい場合は、新しい列に入れるか、元の列に代入する必要があります。
よくあるミス2:条件式の向きが逆になる
where()とmask()で一番多いミスは、条件式の向きを逆にしてしまうことです。
たとえば、「60点以上だけ残したい」のに、次のように書くと意図と逆になります。
wrong = pd.DataFrame({
"名前": df["名前"],
"点数": df["点数"],
"意図と逆になりやすい例": df["点数"].where(df["点数"] < 60)
})
wrong| 名前 | 点数 | 意図と逆になりやすい例 | |
|---|---|---|---|
| 0 | 田中 | 82 | NaN |
| 1 | 佐藤 | 55 | 55.0 |
| 2 | 鈴木 | 91 | NaN |
| 3 | 高橋 | 47 | 47.0 |
| 4 | 伊藤 | 60 | NaN |
| 5 | 山本 | 73 | NaN |
上の例では、df["点数"] < 60という条件を書いているため、60点未満の値が残っています。
「60点以上だけ残したい」なら、条件は次のように書きます。
correct = pd.DataFrame({
"名前": df["名前"],
"点数": df["点数"],
"60点以上だけ残す": df["点数"].where(df["点数"] >= 60)
})
correct| 名前 | 点数 | 60点以上だけ残す | |
|---|---|---|---|
| 0 | 田中 | 82 | 82.0 |
| 1 | 佐藤 | 55 | NaN |
| 2 | 鈴木 | 91 | 91.0 |
| 3 | 高橋 | 47 | NaN |
| 4 | 伊藤 | 60 | 60.0 |
| 5 | 山本 | 73 | 73.0 |
where()では、残したい条件を書くと覚えると、条件式の向きを間違えにくくなります。
逆に、mask()では、置き換えたい条件を書くと考えると分かりやすいです。
条件に合わない値をNaNにしたあとの流れ
where()やmask()で値をNaNにしたあと、そのまま終わりではありません。
NaNにしたあとは、目的に応じて次の処理につながります。
| 次にしたいこと | 使う方法 |
|---|---|
| 欠損値の数を確認したい | isnull().sum() |
| 欠損値を0や平均値で埋めたい | fillna() |
| 欠損値を含む行を削除したい | dropna() |
| 集計したい | groupby()、value_counts() |
| 分布を確認したい | ヒストグラム、箱ひげ図 |
ここでは、年齢が120歳を超える値をNaNにしたあと、欠損値の数を確認してみます。
age_checked = df["年齢"].mask(df["年齢"] > 120)
age_checked.isnull().sum()np.int64(1)
このように、where()やmask()は「欠損値を作る」ことがあります。
そのため、後続のfillna()やdropna()、集計・可視化とセットで考えると、データ分析の流れがつかみやすくなります。
np.where()には軽く触れる程度でよい
条件に応じて値を変える方法として、np.where()もよく見かけます。
ただし、初心者が最初に学ぶ場合は、まずpandasのwhere()とmask()で、残す条件・置き換える条件の考え方を理解するのがおすすめです。
np.where()は、たとえば「合格」「不合格」のような新しい列を作るときに便利です。
import numpy as np
df_np = df.copy()
df_np["判定"] = np.where(df_np["点数"] >= 60, "合格", "再確認")
df_np[["名前", "点数", "判定"]]| 名前 | 点数 | 判定 | |
|---|---|---|---|
| 0 | 田中 | 82 | 合格 |
| 1 | 佐藤 | 55 | 再確認 |
| 2 | 鈴木 | 91 | 合格 |
| 3 | 高橋 | 47 | 再確認 |
| 4 | 伊藤 | 60 | 合格 |
| 5 | 山本 | 73 | 合格 |
ここでは、np.where()の詳細には深入りしません。
この記事では、次のように整理しておけば十分です。
| 方法 | まず覚える使いどころ |
|---|---|
where() |
条件を満たす値を残す |
mask() |
条件を満たす値を置き換える |
np.where() |
条件に応じて新しい配列・列を作る |
新しい列の作り方を詳しく学びたい場合は、条件付き列追加の記事と合わせて学ぶと理解しやすくなります。
データ分析の流れではどこで使うか
where()とmask()は、単独で覚えるよりも、データ分析の流れの中で考えると使いどころが見えやすくなります。
たとえば、次のような流れです。
- CSVやExcelを読み込む
head()で先頭を確認するinfo()やdescribe()で型・欠損値・統計量を確認するunique()やvalue_counts()で不自然な値を見つけるreplace()で表記ゆれを直すwhere()やmask()で条件に合わない値を整理するfillna()で欠損値を補うgroupby()やグラフで集計・可視化する
つまり、where()とmask()は、値を確認したあと、集計や可視化に進む前の前処理として使うと自然です。
特に、外れ値や不自然な値をそのまま集計すると、平均値やグラフが読みにくくなることがあります。
その前に、どの値を残し、どの値を確認対象にするかを整理するのが大切です。
まとめ
この記事では、pandasのwhere()とmask()の使い方を解説しました。
ポイントは次のとおりです。
| ポイント | 内容 |
|---|---|
where() | 条件を満たす値を残す |
mask() | 条件を満たす値を置き換える |
other | 条件に合わない場合、または条件に合う場合の置き換え値を指定する |
| 条件式の考え方 | where()は残したい条件、mask()は置き換えたい条件を書く |
replace()との違い | replace()は特定の値そのものを置き換える |
fillna()との違い | fillna()はすでにある欠損値を埋める |
locとの違い | locは条件に合う行・列を指定して代入する |
np.where()との違い | 条件に応じて新しい列を作るときに使われやすい |
NaNにしたとき | 整数列が82.0のように小数表示になることがある |
where()とmask()は、条件に応じて値を残す・置き換えるための前処理で役立ちます。
最初は難しく感じるかもしれませんが、次の2つだけ覚えておけば大丈夫です。
- 残したい条件を書くなら
where() - 置き換えたい条件を書くなら
mask()
この考え方を押さえると、条件に応じた値の整理がかなり分かりやすくなります。
次に読みたい関連記事
今回の記事とあわせて読むと、Pandasの前処理の流れがつかみやすくなります。
where()とmask()の違いは何ですか?
where()は、条件を満たす値を残し、条件を満たさない値を置き換えます。mask()は逆に、条件を満たす値を置き換えます。
迷ったときは、where()は「残したい条件」、mask()は「置き換えたい条件」を書くと考えると分かりやすいです。
where()とreplace()はどう使い分けますか?
replace()は、特定の値そのものを置き換えるときに向いています。
たとえば、"未入力"をNaNにしたい場合はreplace()が分かりやすいです。
一方、60点未満や0未満のように、条件式で判断したい場合はwhere()やmask()が向いています。
where()とlocで条件代入する方法は何が違いますか?
locは、条件に合う行と列を指定して代入する方法です。where()は、条件を満たす値を残し、条件を満たさない値を置き換えた結果を作る方法です。
どちらでも同じ結果を作れる場面はあります。
初心者のうちは、行・列を指定して変更したいならloc、値を条件に応じて残す・置き換えるならwhere()やmask()と考えると整理しやすいです。
where()で元のDataFrameが変わらないのはなぜですか?
where()を実行しただけでは、元のDataFrameは自動で書き換わりません。
処理結果を残したい場合は、次のように代入します。df["列名"] = df["列名"].where(条件, other=置き換える値)
元データを残したい場合は、新しい列に保存すると確認しやすいです。
条件に合わない値をNaNにするにはどうすればよいですか?
where()でotherを指定しなければ、条件を満たさない値はNaNになります。df["点数"].where(df["点数"] >= 60)
この例では、60点以上はそのまま残り、60点未満はNaNになります。
np.where()とpandasのwhere()はどちらを使えばよいですか?
まずは、pandasのwhere()とmask()で考え方を理解するのがおすすめです。
・条件を満たす値を残したい → where()
・条件を満たす値を置き換えたい → mask()
・条件に応じて新しい列を作りたい → np.where()も候補np.where()は便利ですが、この記事では詳しい使い方には深入りしません。
複数条件でもwhere()は使えますか?
使えます。
複数条件を使う場合は、各条件を()で囲み、AND条件は&でつなぎます。df["点数"].where((df["点数"] >= 60) & (df["点数"] <= 90))
ただし、複数条件は初心者が混乱しやすいため、最初は単一条件でwhere()とmask()の考え方を理解するのがおすすめです。
fillna()とは何が違いますか?
fillna()は、すでにあるNaNを0や平均値などで埋めるメソッドです。
一方、where()やmask()は、条件に応じて値をNaNにしたり、別の値に置き換えたりできます。
流れとしては、where()やmask()で確認が必要な値をNaNにし、そのあと必要に応じてfillna()で補う、という使い方があります。
コメント