このカテゴリでは、Pandasを使ったデータ抽出やフィルタリング、欠損値処理、重複データの削除など、分析前の前処理に関する操作を解説します。loc・iloc・isin・dropなどの具体的なサンプルコードを用いて、実務での活用方法を学びます。
 抽出・前処理
抽出・前処理 pandas between()の使い方|数値・日付を範囲で抽出する方法
pandasのbetween()で数値や日付を範囲抽出する方法を初心者向けに解説。判定から行抽出までの流れ、inclusive、欠損値、query()やcut()との違いも整理します。パーマリンク案
 抽出・前処理
抽出・前処理 pandas select_dtypes()の使い方|データ型で列を選ぶ方法を初心者向けに解説
pandasのselect_dtypes()を使って、数値列・文字列列・日付列などをデータ型で選ぶ方法を初心者向けに解説します。dtypesで型を確認し、to_numeric()やto_datetime()で型を整えてから、必要な列だけを抽出する流れまでわかります。
 抽出・前処理
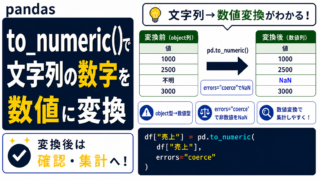
抽出・前処理 pandas to_numeric()の使い方|文字列の数字を数値に変換する方法
pandasのto_numeric()で文字列の数字を数値に変換する方法を初心者向けに解説。object型で計算できない原因、errors="coerce"でNaNにする使い方、astype()との違い、カンマ・円付き金額の前処理まで具体例で紹介します。
 抽出・前処理
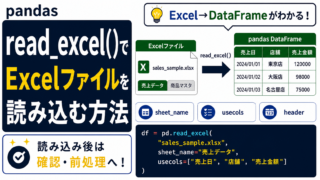
抽出・前処理 pandas read_excel()の使い方|Excelファイル読み込み・sheet_name・usecolsを解説
pandasのread_excel()でExcelファイルを読み込む方法を初心者向けに解説。sheet_nameでシート指定、usecolsで列指定、header・skiprowsで見出し行を調整する方法、Colabでの読み込み、CSV化の考え方まで紹介します。
 抽出・前処理
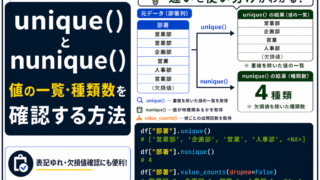
抽出・前処理 pandas unique()とnunique()の使い方|値の一覧・種類数・value_counts()との違いを解説
pandasのunique()とnunique()の違いを初心者向けに解説。値の一覧を確認するunique()、種類数を数えるnunique()、value_counts()との使い分け、欠損値や表記ゆれ確認の注意点まで具体例で紹介します。