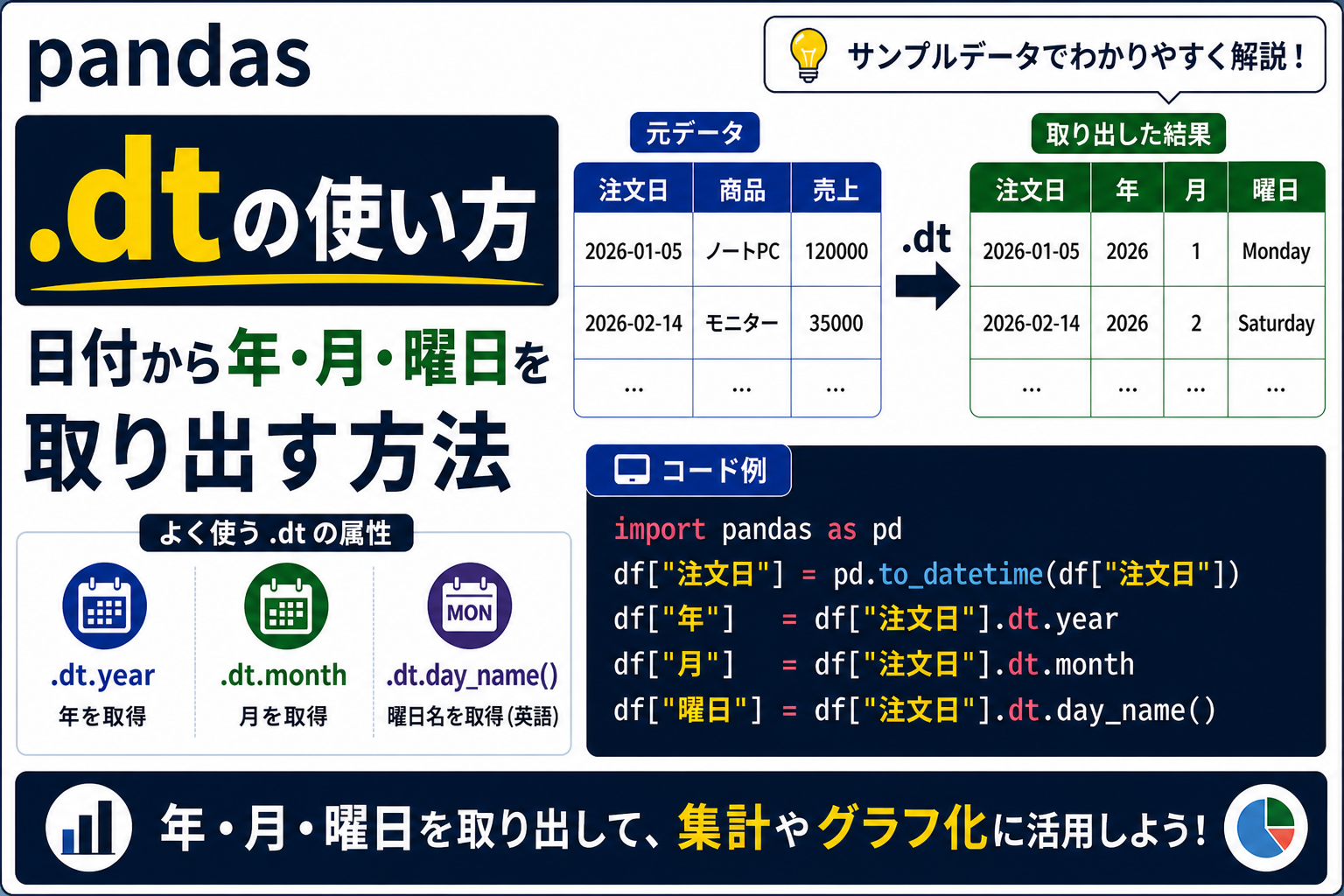
CSVを読み込んだあと、pd.to_datetime()で日付列を日付型に変換できても、次のように迷うことがあります。
- 月別に売上を集計したい
- 曜日ごとの傾向を見たい
- 日付から年だけ、月だけを取り出したい
df["注文日"].dt.yearのような.dtが何をしているのかわからない
結論からいうと、.dtは、日付型の列から「年・月・日・曜日」などを取り出すために使う書き方です。
たとえば、日付列から月を取り出して「月」列を作ると、月別集計がしやすくなります。曜日を取り出すと、曜日別の売上や注文数を確認しやすくなります。
この記事では、pandasの.dtの使い方を、日付列から年・月・曜日を取り出し、集計や可視化につなげる流れでやさしく解説します。
- まずはこの3行:日付から年・月・曜日を取り出す基本形
- この記事でわかること
- やりたいこと別:.dtの使い分け早見表
- .dtとは?日付列から年・月・曜日を取り出す書き方
- to_datetime()と.dtの違い
- この処理はどこで使う?日付変換の次に行う前処理
- サンプルデータを用意する
- まずは日付列の型を確認する
- .dtを使う前にto_datetime()で日付型に変換する
- .dt.yearで日付から年を取り出す
- .dt.monthで日付から月を取り出す
- .dt.dayで日付から日を取り出す
- .dt.day_name()で曜日名を取り出す
- .dt.weekdayで曜日番号を取り出す
- 処理前と処理後を比較する
- よく使う.dtの取り出し項目
- 年月単位で集計したいときはdt.strftime("%Y-%m")も使う
- 月別売上を集計する
- 曜日別売上を集計する
- 月別・曜日別に何を見たいかで使い分ける
- .dtでよくあるエラーと原因
- NaTがある列に.dtを使うとどうなるか
- .dtで作った列は新しい列として残すと分析しやすい
- 可視化につなげるときの考え方
- 軽く知っておくと便利な.dtの関連機能
- まとめ:.dtは日付を分析に使いやすくする前処理
- 次に読みたい関連記事
まずはこの3行:日付から年・月・曜日を取り出す基本形
急いで使い方だけ確認したい場合は、日付型に変換したあと、次のように書きます。
df["注文日"] = pd.to_datetime(df["注文日"], errors="coerce")
df["月"] = df["注文日"].dt.month
df["曜日"] = df["注文日"].dt.day_name()
この3行の意味は、次の通りです。
| 行 | 役割 |
|---|---|
pd.to_datetime() |
文字列の日付を、Pandasで扱える日付型に変換する |
.dt.month |
日付から月だけを取り出す |
.dt.day_name() |
日付から曜日名を取り出す |
年を取り出したい場合は、df["注文日"].dt.yearを使います。 この記事では、この基本形をもとに、年・月・日・曜日の取り出し方と、月別集計・曜日別集計へのつなげ方を順番に見ていきます。
この記事でわかること
このあと、次の内容を順番に見ていきます。
- pandasの
.dtとは何か .dtを使う前に日付型へ変換する理由.dt.yearで年を取り出す方法.dt.monthで月を取り出す方法.dt.dayで日を取り出す方法.dt.day_name()で曜日名を取り出す方法.dt.weekdayで曜日番号を取り出す方法- 英語の曜日名を日本語表示に整える基本
- 取り出した年・月・曜日を新しい列として追加する方法
- 月別集計・曜日別集計につなげる考え方
.dtでエラーになる原因と確認ポイント
この記事では、resample()を使った本格的な時系列分析や、タイムゾーン、移動平均、時系列予測までは深入りしません。まずは、日付列を分析しやすい形に分解する基本に絞って解説します。
やりたいこと別:.dtの使い分け早見表
日付データで迷ったときは、まず「何をしたいのか」から考えると選びやすくなります。
| やりたいこと | 使う書き方 | 使う場面 |
|---|---|---|
| 文字列の日付を日付型に変換したい | pd.to_datetime() |
CSVで読み込んだ日付列を整えるとき |
| 年を取り出したい | .dt.year |
年別集計をしたいとき |
| 月を取り出したい | .dt.month |
月別集計をしたいとき |
| 日を取り出したい | .dt.day |
日付の「日」だけ確認したいとき |
| 曜日名を取り出したい | .dt.day_name() |
曜日別の傾向を見たいとき |
| 曜日順に並べたい | .dt.weekday |
月曜から日曜の順に並べたいとき |
| 年月で集計したい | .dt.strftime("%Y-%m") |
複数年データで月別推移を見たいとき |
この表の中でも、この記事では特に使用頻度が高い、pd.to_datetime() → .dt.year / .dt.month / .dt.day_name() の流れを中心に解説します。
.dtとは?日付列から年・月・曜日を取り出す書き方
.dtは、Pandasで日付列から年・月・日・曜日などを取り出すときに使う書き方です。
専門的には「日付・時刻用のアクセサ」と呼ばれますが、最初から用語を覚える必要はありません。まずは、日付列から必要な情報を取り出すための入口と考えるとわかりやすいです。
たとえば、次のように使います。
| やりたいこと | 書き方の例 | 取り出せるもの |
|---|---|---|
| 年を取り出す | df["注文日"].dt.year |
2026などの年 |
| 月を取り出す | df["注文日"].dt.month |
1〜12の月 |
| 日を取り出す | df["注文日"].dt.day |
1〜31の日 |
| 曜日名を取り出す | df["注文日"].dt.day_name() |
Mondayなどの曜日名 |
| 曜日番号を取り出す | df["注文日"].dt.weekday |
月曜0〜日曜6の番号 |
ただし、ここで大切なのは、.dtは日付型の列に対して使うという点です。 見た目が日付の文字列でも、型がobjectのままだと.dtを使えないことがあります。
to_datetime()と.dtの違い
.dtを理解する前に、pd.to_datetime()との違いを整理しておきましょう。
| 比較項目 | pd.to_datetime() |
.dt |
|---|---|---|
| 主な役割 | 文字列などを日付型に変換する | 日付型の列から年・月・曜日などを取り出す |
| 使うタイミング | .dtを使う前 |
日付型に変換したあと |
| 例 | pd.to_datetime(df["注文日"]) |
df["注文日"].dt.month |
| 初心者が迷いやすい点 | 変換できない値があるとNaTになることがある |
日付型でない列には使えない |
つまり、流れとしては次のように考えるとわかりやすいです。
- まず、
pd.to_datetime()で日付列を日付型に変換する - そのあと、
.dt.yearや.dt.monthで年・月・曜日を取り出す
日付変換そのものを詳しく確認したい場合は、以下の記事を参考にしてください。
この処理はどこで使う?日付変換の次に行う前処理
ここまでで見たように、.dtはpd.to_datetime()で日付型に変換したあとのステップで使います。
CSV読み込み → DataFrame確認 → 日付型への変換 → .dtで年・月・曜日を取り出す → 集計 → 可視化
という流れで考えると、今回の.dtは、日付列を集計や可視化に使いやすくするための前処理にあたります。
CSVの読み込みは、以下の記事で詳しく解説しています。
DataFrameの基本や、型・欠損値の確認は以下の記事も参考になります。
サンプルデータを用意する
ここでは、ECサイトの注文データを想定します。コードが長くなりすぎないよう、6行だけの小さなデータで確認します。
列は、初心者が理解しやすいように次の3つだけにします。
注文日商品売上
注文日は、最初は文字列として入っている想定です。 CSVを読み込んだ直後も、日付列が文字列のままになっていることはよくあります。
import pandas as pd
注文日 = ["2026-01-05", "2026-01-10", "2026-02-03", "2026-02-14", "2026-03-08", "2026-03-12"]
商品 = ["ノートPC", "マウス", "キーボード", "モニター", "マウス", "キーボード"]
売上 = [120000, 3000, 8000, 35000, 3200, 8500]
df = pd.DataFrame({"注文日": 注文日,"商品": 商品,"売上": 売上})
df
| 注文日 | 商品 | 売上 | |
|---|---|---|---|
| 0 | 2026-01-05 | ノートPC | 120000 |
| 1 | 2026-01-10 | マウス | 3000 |
| 2 | 2026-02-03 | キーボード | 8000 |
| 3 | 2026-02-14 | モニター | 35000 |
| 4 | 2026-03-08 | マウス | 3200 |
| 5 | 2026-03-12 | キーボード | 8500 |
まずは日付列の型を確認する
.dtを使う前に、まず注文日列の型を確認します。
日付のように見えても、Pandas上では文字列として扱われていることがあります。 その場合、.dt.yearや.dt.monthをそのまま使うとエラーになる原因になります。
df.dtypes
| 注文日 | object |
| 商品 | object |
| 売上 | int64 |
上のコードを実行すると、注文日がobject型になっていることを確認できます。
object型は、ざっくり言うと文字列として扱われている状態です。 このままでは、日付の部品を取り出す.dtを使う準備ができていません。
.dtを使う前にto_datetime()で日付型に変換する
.dtを使うために、注文日列を日付型に変換します。
実務では、日付列の中に変換できない値が混ざることがあります。 そのため、ここでは安全にerrors="coerce"を指定しています。
errors="coerce"を付けると、変換できない値があった場合にNaTになります。NaTは、日付データにおける欠損値のようなものです。
df["注文日"] = pd.to_datetime(df["注文日"], errors="coerce")
df
| 注文日 | 商品 | 売上 | |
|---|---|---|---|
| 0 | 2026-01-05 | ノートPC | 120000 |
| 1 | 2026-01-10 | マウス | 3000 |
| 2 | 2026-02-03 | キーボード | 8000 |
| 3 | 2026-02-14 | モニター | 35000 |
| 4 | 2026-03-08 | マウス | 3200 |
| 5 | 2026-03-12 | キーボード | 8500 |
型も確認してみましょう。
df.dtypes
| 注文日 | datetime64[ns] |
| 商品 | object |
| 売上 | int64 |
注文日がdatetime64[ns]になっていれば、.dtを使う準備ができています。
ここまでが、.dtを使う前の大切な準備です。 日付型への変換を深く学びたい場合は、format=やNaT対処も含めて、以下の記事で確認できます。
.dt.yearで日付から年を取り出す
年だけを取り出したいときは、.dt.yearを使います。
たとえば、注文日から「何年の注文か」を新しい列にしたい場合に使えます。
df["年"] = df["注文日"].dt.year
df[["注文日", "年"]]
| 注文日 | 年 | |
|---|---|---|
| 0 | 2026-01-05 | 2026 |
| 1 | 2026-01-10 | 2026 |
| 2 | 2026-02-03 | 2026 |
| 3 | 2026-02-14 | 2026 |
| 4 | 2026-03-08 | 2026 |
| 5 | 2026-03-12 | 2026 |
注文日から、2026のような年だけを取り出せました。
ここで注意したいのは、NaTになっている行では、取り出した年も欠損になることです。 日付がない行から年を取り出すことはできないため、これは自然な結果です。
.dt.monthで日付から月を取り出す
月だけを取り出したいときは、.dt.monthを使います。
月別に売上を集計したい場合、まずは日付列から「月」列を作っておくとわかりやすくなります。
df["月"] = df["注文日"].dt.month
df[["注文日", "月"]]
| 注文日 | 月 | |
|---|---|---|
| 0 | 2026-01-05 | 1 |
| 1 | 2026-01-10 | 1 |
| 2 | 2026-02-03 | 2 |
| 3 | 2026-02-14 | 2 |
| 4 | 2026-03-08 | 3 |
| 5 | 2026-03-12 | 3 |
.dt.monthを使うと、1〜12の数値として月を取り出せます。
ただし、複数年のデータを扱う場合は注意が必要です。 .dt.monthだけで集計すると、たとえば「2025年1月」と「2026年1月」が同じ「1月」としてまとめられてしまいます。
複数年データで年月単位にしたい場合は、後ほど紹介するdt.strftime("%Y-%m")のように、年と月を組み合わせた列を作ると安全です。
.dt.dayで日付から日を取り出す
日付の「日」だけを取り出したいときは、.dt.dayを使います。
たとえば、月の前半・後半で傾向を見たい場合や、日単位の確認をしたい場合に使えます。
df["日"] = df["注文日"].dt.day
df[["注文日", "日"]]
| 注文日 | 日 | |
|---|---|---|
| 0 | 2026-01-05 | 5 |
| 1 | 2026-01-10 | 10 |
| 2 | 2026-02-03 | 3 |
| 3 | 2026-02-14 | 14 |
| 4 | 2026-03-08 | 8 |
| 5 | 2026-03-12 | 12 |
.dt.dayでは、1〜31の「日」を取り出せます。
ここでの「日」は日付の中の1日、2日、3日のような値です。 曜日を取り出す処理とは別なので、混同しないようにしましょう。
.dt.day_name()で曜日名を取り出す
曜日名を取り出したいときは、.dt.day_name()を使います。
曜日別に売上や注文数を見たいときに役立ちます。
df["曜日"] = df["注文日"].dt.day_name()
df[["注文日", "曜日"]]
| 注文日 | 曜日 | |
|---|---|---|
| 0 | 2026-01-05 | Monday |
| 1 | 2026-01-10 | Saturday |
| 2 | 2026-02-03 | Tuesday |
| 3 | 2026-02-14 | Saturday |
| 4 | 2026-03-08 | Sunday |
| 5 | 2026-03-12 | Thursday |
.dt.day_name()を使うと、MondayやTuesdayのように英語の曜日名が取り出されます。
英語の曜日名のままでも集計はできます。 ただし、ブログ記事やレポートで見せる場合は、日本語の曜日にしたいこともあります。
その場合は、.dt.day_name()で取り出した曜日名を、map()で日本語に置き換えるとわかりやすくなります。
weekday_map = {
"Monday": "月曜日",
"Tuesday": "火曜日",
"Wednesday": "水曜日",
"Thursday": "木曜日",
"Friday": "金曜日",
"Saturday": "土曜日",
"Sunday": "日曜日"
}
df["曜日_日本語"] = df["曜日"].map(weekday_map)
df[["注文日", "曜日", "曜日_日本語"]]
| 注文日 | 曜日 | 曜日_日本語 | |
|---|---|---|---|
| 0 | 2026-01-05 | Monday | 月曜日 |
| 1 | 2026-01-10 | Saturday | 土曜日 |
| 2 | 2026-02-03 | Tuesday | 火曜日 |
| 3 | 2026-02-14 | Saturday | 土曜日 |
| 4 | 2026-03-08 | Sunday | 日曜日 |
| 5 | 2026-03-12 | Thursday | 木曜日 |
ここでは、.dt.day_name()で取り出した英語の曜日名を、日本語の曜日名に置き換えました。
ただし、この記事では.dtの基本を優先するため、以降の集計例では、先に作った曜日列と曜日番号列を使って説明します。 曜日名の置き換え自体を詳しく学びたい場合は、map()やreplace()の記事とつなげて考えると理解しやすくなります。
.dt.weekdayで曜日番号を取り出す
曜日を番号で扱いたい場合は、.dt.weekdayを使います。
.dt.weekdayでは、曜日が次の番号で表されます。
| 曜日 | 番号 |
|---|---|
| 月曜日 | 0 |
| 火曜日 | 1 |
| 水曜日 | 2 |
| 木曜日 | 3 |
| 金曜日 | 4 |
| 土曜日 | 5 |
| 日曜日 | 6 |
曜日順に並べたいときは、曜日名だけでなく曜日番号も持っておくと便利です。
df["曜日番号"] = df["注文日"].dt.weekday
df[["注文日", "曜日", "曜日番号"]]
| 注文日 | 曜日 | 曜日番号 | |
|---|---|---|---|
| 0 | 2026-01-05 | Monday | 0 |
| 1 | 2026-01-10 | Saturday | 5 |
| 2 | 2026-02-03 | Tuesday | 1 |
| 3 | 2026-02-14 | Saturday | 5 |
| 4 | 2026-03-08 | Sunday | 6 |
| 5 | 2026-03-12 | Thursday | 3 |
曜日名だけで集計すると、表示順がアルファベット順になることがあります。 曜日番号を一緒に持っておくと、月曜から日曜の順に並べやすくなります。
処理前と処理後を比較する
ここまでで、注文日から年・月・日・曜日を取り出して、新しい列として追加しました。
処理前と処理後のイメージを比較すると、.dtの役割がわかりやすくなります。
| 状態 | 列の例 | できること |
|---|---|---|
| 処理前 | 注文日、商品、売上 | 日付はあるが、月別・曜日別の集計には使いにくい |
| 処理後 | 注文日、商品、売上、年、月、日、曜日、曜日番号 | 月別・曜日別の集計に使いやすい |
.dtは、元の日付列を消すためのものではありません。 日付列から分析しやすい列を作るためのものと考えると理解しやすいです。
df
| 注文日 | 商品 | 売上 | 年 | 月 | 日 | 曜日 | 曜日_日本語 | 曜日番号 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2026-01-05 | ノートPC | 120000 | 2026 | 1 | 5 | Monday | 月曜日 | 0 |
| 1 | 2026-01-10 | マウス | 3000 | 2026 | 1 | 10 | Saturday | 土曜日 | 5 |
| 2 | 2026-02-03 | キーボード | 8000 | 2026 | 2 | 3 | Tuesday | 火曜日 | 1 |
| 3 | 2026-02-14 | モニター | 35000 | 2026 | 2 | 14 | Saturday | 土曜日 | 5 |
| 4 | 2026-03-08 | マウス | 3200 | 2026 | 3 | 8 | Sunday | 日曜日 | 6 |
| 5 | 2026-03-12 | キーボード | 8500 | 2026 | 3 | 12 | Thursday | 木曜日 | 3 |
よく使う.dtの取り出し項目
.dtには多くの機能がありますが、初心者が最初に覚えるなら、まずは次の項目で十分です。
| 取り出したいもの | 書き方 | 用途の例 |
|---|---|---|
| 年 | .dt.year |
年別集計、年度確認 |
| 月 | .dt.month |
月別集計 |
| 日 | .dt.day |
日単位の確認 |
| 曜日名 | .dt.day_name() |
曜日別の傾向確認 |
| 曜日番号 | .dt.weekday |
曜日順に並べる |
| 四半期 | .dt.quarter |
1〜4四半期で見る |
| 日付部分 | .dt.date |
時刻を除いた日付を確認する |
.dt.quarterや.dt.dateも便利ですが、この記事では深掘りしません。 まずは、年・月・日・曜日を取り出せるようになることを優先しましょう。
年月単位で集計したいときはdt.strftime("%Y-%m")も使う
.dt.monthは、1〜12の月だけを取り出します。
そのため、複数年のデータで月別集計をするときは、2026-01のような年月列を作ると便利です。 このように表示形式を整えたいときは、.dt.strftime("%Y-%m")を使えます。
df["年月"] = df["注文日"].dt.strftime("%Y-%m")
df[["注文日", "年", "月", "年月"]]
| 注文日 | 年 | 月 | 年月 | |
|---|---|---|---|---|
| 0 | 2026-01-05 | 2026 | 1 | 2026-01 |
| 1 | 2026-01-10 | 2026 | 1 | 2026-01 |
| 2 | 2026-02-03 | 2026 | 2 | 2026-02 |
| 3 | 2026-02-14 | 2026 | 2 | 2026-02 |
| 4 | 2026-03-08 | 2026 | 3 | 2026-03 |
| 5 | 2026-03-12 | 2026 | 3 | 2026-03 |
dt.strftime("%Y-%m")を使うと、2026-01のような年月の文字列を作れます。
ここでは軽く紹介するだけにします。 表示形式を自由に整える処理は便利ですが、最初から細かく覚えすぎるより、まずは.dt.year、.dt.month、.dt.day_name()の基本を押さえるのがおすすめです。
月別売上を集計する
.dtで月や年月の列を作ると、groupby()で月別集計がしやすくなります。
ここでは、年月ごとに売上合計を集計してみます。
なお、今回のサンプルには、日付に変換できなかったNaTの行があります。 月別集計では、まずは初心者が読みやすいように、注文日が欠損していない行だけを対象にします。
monthly_sales = (
df.dropna(subset=["注文日"])
.groupby("年月", as_index=False)["売上"]
.sum()
)
monthly_sales
| 年月 | 売上 | |
|---|---|---|
| 0 | 2026-01 | 123000 |
| 1 | 2026-02 | 43000 |
| 2 | 2026-03 | 11700 |
年月ごとに売上を合計できました。
このように、.dtで取り出した値は、集計のキーとして使えます。 groupby()の基本を詳しく学びたい場合は、以下の記事も参考になります。
曜日別売上を集計する
次に、曜日別に売上を集計してみます。
曜日名だけだと並び順がわかりにくくなるため、ここでは曜日番号も使って並べます。
weekday_sales = (
df.dropna(subset=["注文日"])
.groupby(["曜日番号", "曜日"], as_index=False)["売上"]
.sum()
.sort_values("曜日番号")
)
weekday_sales
| 曜日番号 | 曜日 | 売上 | |
|---|---|---|---|
| 0 | 0 | Monday | 120000 |
| 1 | 1 | Tuesday | 8000 |
| 2 | 3 | Thursday | 8500 |
| 3 | 5 | Saturday | 38000 |
| 4 | 6 | Sunday | 3200 |
曜日ごとの売上合計を確認できました。
曜日名だけでなく曜日番号も作っておくと、月曜から日曜の順に並べやすくなります。 曜日別の件数だけを確認したい場合は、value_counts()を使う方法もあります。
df.dropna(subset=["注文日"])["曜日"].value_counts()
| count | |
|---|---|
| Saturday | 2 |
| Monday | 1 |
| Tuesday | 1 |
| Sunday | 1 |
| Thursday | 1 |
value_counts()は、曜日ごとの件数を数えたいときに便利です。
ここでも、日付がない行は曜日を判断できないため、dropna(subset=["注文日"])で除外してから数えています。
- 合計や平均を出したい →
groupby() - 件数を数えたい →
value_counts()
このように使い分けると、日付データを分析に使いやすくなります。
value_counts()について詳しく知りたい場合は、以下の記事も参考になります。
月別・曜日別に何を見たいかで使い分ける
.dtで日付を分解するときは、「何を見たいのか」から逆算すると迷いにくくなります。
| 見たいこと | 使う列・処理の例 | 次につなげる処理 |
|---|---|---|
| 年ごとの売上を見たい | .dt.yearで年列を作る |
groupby("年") |
| 月ごとの売上を見たい | .dt.monthまたは年月列を作る |
groupby("月")またはgroupby("年月") |
| 曜日ごとの傾向を見たい | .dt.day_name()や.dt.weekdayを使う |
曜日別のgroupby() |
| 件数だけを見たい | 月列・曜日列を作る | value_counts() |
| グラフにしたい | 集計結果を作る | Matplotlibの棒グラフ・折れ線グラフ |
.dtは最終目的ではなく、集計や可視化をしやすくするための前処理です。
.dtでよくあるエラーと原因
.dtで初心者がつまずきやすいのは、日付型に変換する前に使ってしまうケースです。
たとえば、次のように文字列のまま.dt.yearを使うと、エラーになります。
df_error = pd.DataFrame({
"注文日": ["2026-01-01", "2026-01-02"]
})
try:
df_error["注文日"].dt.year
except Exception as e:
print(type(e).__name__)
print(e)
AttributeError Can only use .dt accessor with datetimelike values
このエラーは、注文日列がまだ日付型ではないことが原因です。
対処法は、次の流れです。
df.dtypesやdf.info()で型を確認するpd.to_datetime()で日付型へ変換する- そのあとに
.dt.yearや.dt.monthを使う
型の確認方法は、以下の記事でも詳しく解説しています。
NaTがある列に.dtを使うとどうなるか
日付に変換できない値があると、pd.to_datetime()でNaTになることがあります。
ここでは、本文のメインデータとは別に、未入力を含む小さなデータで確認します。
df_nat = pd.DataFrame({
"注文日": ["2026-01-05", "未入力"]
})
df_nat["注文日"] = pd.to_datetime(df_nat["注文日"], errors="coerce")
df_nat["年"] = df_nat["注文日"].dt.year
df_nat["月"] = df_nat["注文日"].dt.month
df_nat["曜日"] = df_nat["注文日"].dt.day_name()
df_nat
| 注文日 | 年 | 月 | 曜日 | |
|---|---|---|---|---|
| 0 | 2026-01-05 | 2026 | 1 | Monday |
| 1 | NaT | NaT | NaT | NaT |
未入力は日付に変換できないため、NaTになりました。
NaTの行では、年・月・曜日も欠損になります。 日付がない行から、年や曜日を取り出すことはできないためです。
NaTが多い場合は、まず日付列の欠損や変換できない値を確認することが大切です。 欠損値の確認や処理は、以下の記事ともつながります。
.dtで作った列は新しい列として残すと分析しやすい
.dt.yearや.dt.monthで取り出した値は、その場で見るだけでなく、新しい列として残しておくと便利です。
たとえば、次のような列があると、後から集計や抽出をしやすくなります。
| 追加する列 | 使いどころ |
|---|---|
| 年 | 年別の比較 |
| 月 | 月別の傾向確認 |
| 年月 | 複数年データの月別推移 |
| 曜日 | 曜日別の傾向確認 |
| 曜日番号 | 曜日順に並べる |
新しい列の追加そのものを詳しく知りたい場合は、以下の記事も参考になります。
- [pandasで新しい列を追加する方法|df['列名']・assign・条件付き列追加を初心者向けに解説](https://pythondatalab.com/pandas-add-column/)
可視化につなげるときの考え方
.dtで月や曜日を取り出したら、そのままグラフ化するのではなく、まず集計表を作ると流れが整理しやすくなります。
たとえば、次のような流れです。
注文日を日付型に変換する.dtで年月や曜日列を作るgroupby()で月別・曜日別に集計する- Matplotlibで棒グラフや折れ線グラフにする
この記事では可視化の細かい設定までは扱いません。 グラフ化を学びたい場合は、以下の記事へ進むと理解がつながります。
軽く知っておくと便利な.dtの関連機能
最後に、発展的ですが、名前だけ知っておくと便利な機能を軽く紹介します。
| 機能 | できること | この記事での扱い |
|---|---|---|
.dt.strftime() |
日付の表示形式を整える | 年月列の作成で軽く使用 |
.dt.quarter |
四半期を取り出す | 名前だけ知っておけばOK |
.dt.date |
日付部分だけ取り出す | 必要になったら調べる |
resample() |
時系列データを期間ごとに集計する | 別記事向けの発展内容 |
最初から全部を覚える必要はありません。 まずは、.dt.year、.dt.month、.dt.day_name()を使って、日付列を分析しやすい列に分けられるようになることを優先しましょう。
まとめ:.dtは日付を分析に使いやすくする前処理
この記事では、pandasの.dtアクセサを使って、日付から年・月・日・曜日を取り出す方法を解説しました。
ポイントを整理します。
.dtは、日付型の列から年・月・曜日などを取り出すために使う.dtを使う前に、pd.to_datetime()で日付型へ変換する.dt.yearで年を取り出せる.dt.monthで月を取り出せる.dt.dayで日を取り出せる.dt.day_name()で曜日名を取り出せる.dt.weekdayで曜日番号を取り出せる- 複数年データの月別集計では、
dt.strftime("%Y-%m")で年月列を作ると便利 - 取り出した値は、新しい列として追加すると集計や可視化に使いやすい
.dtでエラーになるときは、まず日付列の型を確認する
.dtは、日付データ分析のゴールではありません。 日付列を、集計や可視化に使える形へ整えるための前処理です。
日付型への変換はto_datetime()、集計はgroupby()やvalue_counts()、グラフ化はMatplotlibへ進むと、データ分析の流れが自然につながります。
次に読みたい関連記事
今回の記事とあわせて読むと、Pandasの日付データ分析の流れが理解しやすくなります。
基礎・CSV読み込み
型確認・日付変換
- Pandas info()とdescribe()の違い|欠損値・型・統計量の見方を例で解説
- pandas to_datetime()の使い方|文字列の日付変換とformat・NaT対処を初心者向けに解説
列追加・集計
- pandasで新しい列を追加する方法|df[‘列名’]・assign・条件付き列追加を初心者向けに解説
- pandas map()の使い方|辞書で値を変換・新しい列を作る方法を初心者向けに解説
- pandas replace()の使い方|値の置換・表記ゆれ・欠損値変換を解説
- Pandas groupby×aggの使い方|基本の集計とaggの書き方を例で解説
- pandas value_counts()の使い方|件数集計・割合表示・欠損値の数え方を解説
- pandas 並び替え(sort)入門|sort_values・sort_indexの違いと複数列ソート
可視化
pandasの.dtとは何ですか?
.dtは、日付型の列から年・月・日・曜日などを取り出すための書き方です。
たとえば、df["注文日"].dt.yearで年、df["注文日"].dt.monthで月を取り出せます。
.dtを使うとエラーになるのはなぜですか?
多くの場合、対象の列が日付型ではなくobject型の文字列になっていることが原因です。 まずdf.dtypesやdf.info()で型を確認し、必要に応じてpd.to_datetime()で日付型に変換してから.dtを使います。
to_datetime()と.dtは何が違いますか?
to_datetime()は、文字列などを日付型に変換するために使います。 .dtは、日付型に変換したあと、その日付から年・月・曜日などを取り出すために使います。
日付から年や月だけを取り出すにはどうすればよいですか?
年だけを取り出す場合は、df["注文日"].dt.yearを使います。 月だけを取り出す場合は、df["注文日"].dt.monthを使います。
取り出した年や月を分析に使いたい場合は、df["年"] = df["注文日"].dt.year、df["月"] = df["注文日"].dt.monthのように新しい列として追加すると便利です。
日付から曜日を取得するにはどうすればよいですか?
曜日名を取り出したい場合は、df["注文日"].dt.day_name()を使います。 曜日順に並べたい場合は、df["注文日"].dt.weekdayで曜日番号も作っておくと便利です。.dt.day_name()で取り出した曜日名は英語になるため、日本語で見せたい場合は、map()で「Monday → 月曜日」のように置き換える方法があります。
.dt.weekdayと.dt.day_name()は何が違いますか?
.dt.day_name()は、MondayやTuesdayのような曜日名を返します。 .dt.weekdayは、月曜日を0、日曜日を6とする曜日番号を返します。 見やすく表示したいなら曜日名、曜日順に並べたいなら曜日番号が便利です。
月別集計をするには、.dt.monthだけでよいですか?
同じ年のデータだけなら、.dt.monthで月列を作って集計してもわかりやすいです。 ただし、複数年のデータでは、2025年1月と2026年1月が同じ1月として混ざる可能性があります。 その場合は、dt.strftime("%Y-%m")で年月列を作ると安全です。
NaTがある列に.dtを使っても大丈夫ですか?
NaTがある列にも.dtを使える場合があります。 ただし、NaTの行では、年・月・曜日などの結果も欠損になります。 集計に使うときは、必要に応じてdropna(subset=["注文日"])で日付がない行を除外してから集計すると、結果を読みやすくできます。
コメント