
CSVを読み込んだあと、月別の売上や科目別の点数が横に並んでいて、集計しにくいと感じることがあります。
たとえば、次のような表です。
| 社員名 | 1月 | 2月 | 3月 |
|---|---|---|---|
| 佐藤 | 120000 | 135000 | 128000 |
| 鈴木 | 98000 | 110000 | 105000 |
このような表は、人間が見るにはわかりやすいです。
しかし、Pandasで月ごとに集計したり、グラフ化したりする場合は、次のように「月」と「売上」を列として持つ形のほうが扱いやすくなります。
| 社員名 | 月 | 売上 |
|---|---|---|
| 佐藤 | 1月 | 120000 |
| 佐藤 | 2月 | 135000 |
| 佐藤 | 3月 | 128000 |
このように、横に広がった列を縦長にまとめるときに使うのが、Pandasの melt() です。
この記事では、melt() の基本、id_vars と value_vars の使い分け、groupby() やグラフ化へつなげる流れを、初心者向けに順番に解説します。
- この記事でわかること
- melt()はどんな場面で使うのか
- 横持ちデータと縦持ちデータの違い
- サンプルデータを用意する
- 基本形:melt()で横持ちを縦持ちに変換する
- melt()後に行数が増える理由
- 補足:元のindexを残したいときはignore_index=False
- id_varsの意味:そのまま残す列
- value_varsの意味:縦にまとめる列
- var_nameとvalue_nameで列名をわかりやすくする
- value_varsを省略した場合の注意点
- 科目別点数データでもmelt()を使う
- melt()した後にgroupby()で集計する
- melt()した後にvalue_counts()で件数を確認する
- melt()した後に棒グラフで可視化する
- melt()とpivot()・pivot_table()の違い
- melt()とconcat()・merge()の違い
- melt()と他のメソッドを迷ったときの使い分け
- よくあるミスと注意点
- 前処理の流れの中でmelt()を使うタイミング
- 軽く知っておきたい関連メソッド
- まとめ
- 次に読みたい関連記事
この記事でわかること
melt()が何をするメソッドか- 横持ちデータと縦持ちデータの違い
id_varsとvalue_varsの使い分けvar_nameとvalue_nameで列名を整える方法melt()後に行数が増える理由value_varsを省略するときの注意点melt()後にgroupby()や棒グラフへつなげる流れ
この記事のゴールは、横に広がったDataFrameを、集計・可視化しやすい縦持ちデータに変換できるようになることです。
発展的な内容や環境差が出やすい内容は、本文の後半で補足として扱います。
melt()はどんな場面で使うのか
melt() は、次のように「同じ種類の情報が複数の列に分かれている」ときに役立ちます。
| データの例 | 横に並んでいる列 | melt後に作りたい列 |
|---|---|---|
| 月別売上 | 1月, 2月, 3月 |
月, 売上 |
| 科目別点数 | 国語, 数学, 英語 |
科目, 点数 |
| 商品別数量 | ノートPC, マウス, キーボード |
商品, 数量 |
横持ちデータは人間が見る表としては便利です。
一方で、Pandasで集計・条件抽出・グラフ化をする場合は、項目名と値が列として分かれている縦持ちデータのほうが扱いやすいことがあります。
迷ったときは、次のように判断すると整理しやすいです。
| 状況 | melt()を使う? | 理由 |
|---|---|---|
1月, 2月, 3月 のように同じ種類の列が横に並んでいる |
使う | 月 列と 売上 列にまとめると集計しやすい |
国語, 数学, 英語 のように科目が列になっている |
使う | 科目 列と 点数 列にまとめられる |
すでに 月 列と 売上 列がある |
使わない | すでに縦持ちなので変換不要 |
| 表として見やすく表示したいだけ | 無理に使わない | 横持ちのほうが見やすい場合もある |
| 列名を変えたいだけ | 使わない | rename() のほうが目的に合う |
つまり、melt() は「横に並んだ同じ種類の列を、1つの項目列と1つの値列にまとめたい」ときに使います。
横持ちデータと縦持ちデータの違い
melt() を理解するには、まず横持ちデータと縦持ちデータの違いを押さえるとわかりやすいです。
| 形式 | 特徴 | 向いている場面 |
|---|---|---|
| 横持ちデータ | 月・科目・商品などが列として横に並ぶ | 表として眺める、比較表として見る |
| 縦持ちデータ | 月・科目・商品などを1つの列にまとめる | 集計、条件抽出、グラフ化 |
melt() は、横持ちデータを縦持ちデータに変換するためのメソッドです。
ポイントは、列名として横に並んでいた情報を、1つの列の値として縦に並べ直すことです。
図解:横に並んだ月別列を縦にまとめる
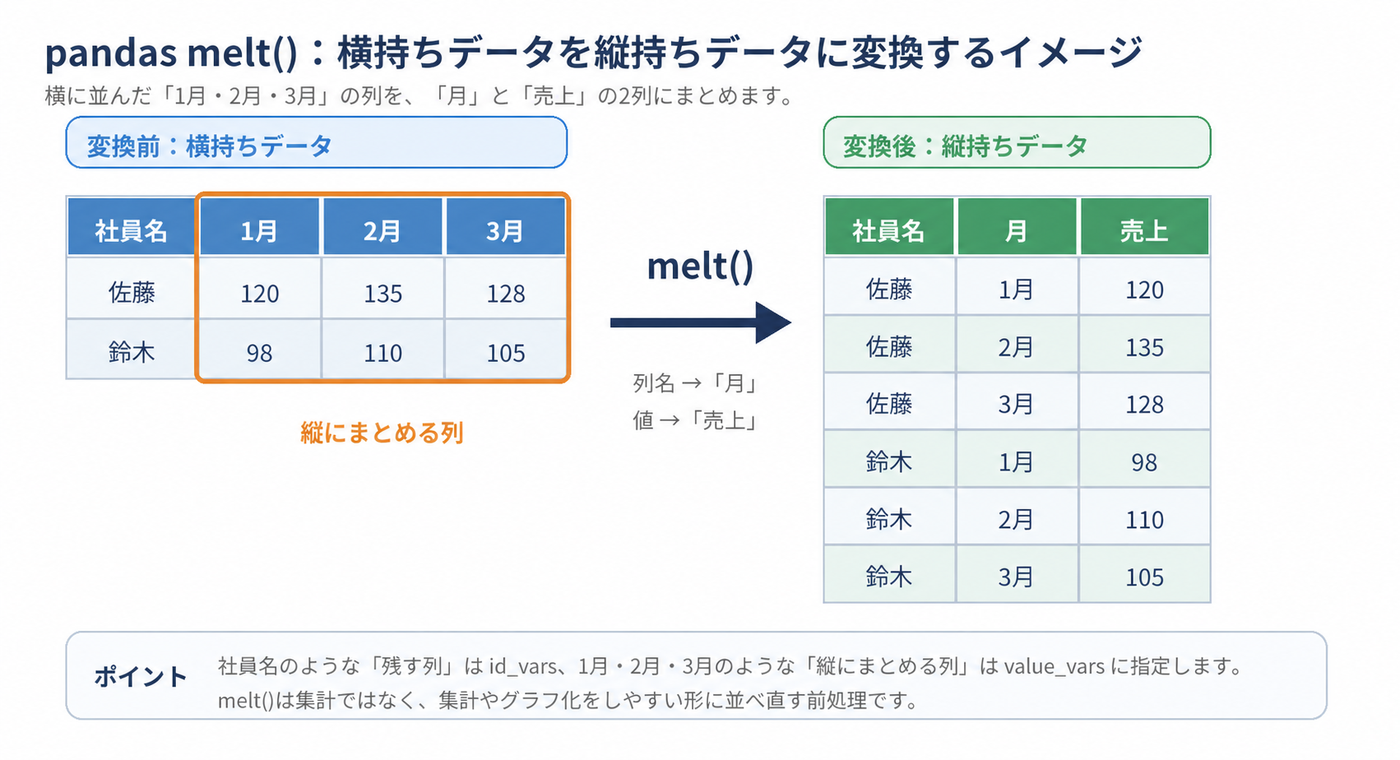
図のように、1月、2月、3月 のように横に並んだ列を、月 列と 売上 列にまとめます。
このとき、社員名 のように残したい列は id_vars に指定します。
一方で、1月、2月、3月 のように縦へまとめたい列は value_vars に指定します。
melt() は売上を合計する処理ではありません。集計やグラフ化をしやすい形に並べ直す前処理です。
サンプルデータを用意する
ここでは、社員ごとの月別売上データを使います。
1月、2月、3月 が横に並んでいるため、月別に集計したいときには少し扱いにくい形です。
import pandas as pd
df = pd.DataFrame({
"社員ID": ["E001", "E002", "E003"],
"社員名": ["佐藤", "鈴木", "田中"],
"部署": ["営業部", "営業部", "企画部"],
"1月": [120000, 98000, 150000],
"2月": [135000, 110000, 142000],
"3月": [128000, 105000, 160000]
})
df| 社員ID | 社員名 | 部署 | 1月 | 2月 | 3月 | |
|---|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 120000 | 135000 | 128000 |
| 1 | E002 | 鈴木 | 営業部 | 98000 | 110000 | 105000 |
| 2 | E003 | 田中 | 企画部 | 150000 | 142000 | 160000 |
このデータでは、社員ID、社員名、部署 は社員を説明する列です。
一方で、1月、2月、3月 は、月別の売上を表す列です。
今回目指す形は、次のとおりです。
| 変換前 | 変換後 |
|---|---|
社員ID, 社員名, 部署, 1月, 2月, 3月 |
社員ID, 社員名, 部署, 月, 売上 |
つまり、社員を説明する列は残し、月別売上の列だけを縦にまとめます。
基本形:melt()で横持ちを縦持ちに変換する
melt() の基本形は次のとおりです。
df.melt(
id_vars=[残す列],
value_vars=[縦にまとめる列],
var_name="項目列の名前",
value_name="値列の名前"
)
今回の場合は、社員情報を残し、月別売上の列を縦にまとめます。
| 引数 | 今回の指定 | 意味 |
|---|---|---|
id_vars |
社員ID, 社員名, 部署 |
そのまま残す列 |
value_vars |
1月, 2月, 3月 |
縦にまとめる列 |
var_name |
月 |
元の列名を入れる列名 |
value_name |
売上 |
元の値を入れる列名 |
melt()は3つに分けて考えると迷いにくい
melt() では、最初に次の3つを決めると迷いにくくなります。
| 決めること | 指定する引数 | 今回の例 |
|---|---|---|
| そのまま残す列はどれか | id_vars |
社員ID, 社員名, 部署 |
| 縦にまとめる列はどれか | value_vars |
1月, 2月, 3月 |
| melt後の列名を何にするか | var_name, value_name |
月, 売上 |
初心者が一番迷いやすいのは、id_vars と value_vars の分け方です。
まずは「社員名や部署のように説明として残す列」と「1月・2月・3月のように縦へまとめる列」を分けて考えると、コードを書きやすくなります。
sales_long = df.melt(
id_vars=["社員ID", "社員名", "部署"],
value_vars=["1月", "2月", "3月"],
var_name="月",
value_name="売上"
)
sales_long| 社員ID | 社員名 | 部署 | 月 | 売上 | |
|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 1月 | 120000 |
| 1 | E002 | 鈴木 | 営業部 | 1月 | 98000 |
| 2 | E003 | 田中 | 企画部 | 1月 | 150000 |
| 3 | E001 | 佐藤 | 営業部 | 2月 | 135000 |
| 4 | E002 | 鈴木 | 営業部 | 2月 | 110000 |
| 5 | E003 | 田中 | 企画部 | 2月 | 142000 |
| 6 | E001 | 佐藤 | 営業部 | 3月 | 128000 |
| 7 | E002 | 鈴木 | 営業部 | 3月 | 105000 |
| 8 | E003 | 田中 | 企画部 | 3月 | 160000 |
1月、2月、3月 の列が、月 列にまとまりました。
それぞれの金額は、売上 列に入っています。
| 元の列 | melt後 |
|---|---|
社員ID, 社員名, 部署 |
そのまま残る |
1月, 2月, 3月 |
月 列に入る |
| 各月の売上金額 | 売上 列に入る |
melt() では、まず「残す列」と「縦にまとめる列」を分けるのがポイントです。
melt()後に行数が増える理由
melt() を初めて使うと、行数が増えることに驚くかもしれません。
今回のデータは、変換前は3人分なので3行です。
しかし、1人につき 1月、2月、3月 の3つの売上があるため、melt() 後は次のように行数が増えます。
| 変換前 | 変換後 |
|---|---|
| 3人 × 1行 = 3行 | 3人 × 3か月 = 9行 |
melt() は、データを消しているのではありません。
横に並んでいた値を、縦に並べ直しているため、行数が増えるのは自然な動きです。
print("変換前の行数:", len(df))
print("変換後の行数:", len(sales_long))変換前の行数: 3 変換後の行数: 9
このように、melt() 後は「元の行数 × 縦にまとめた列数」に近い行数になります。
今回であれば、3人 × 3か月なので9行です。
補足:元のindexを残したいときはignore_index=False
melt() は、通常は変換後に新しい連番indexを付けます。
多くの場合はそのままで問題ありません。
ただし、元の行番号やindexを確認しながら変換結果を見たいときは、ignore_index=False を指定できます。
初心者のうちは必須ではありませんが、melt() 後に「元のindexはどうなるのか」で迷ったときに知っておくと便利です。
df.melt(
id_vars=["社員ID", "社員名", "部署"],
value_vars=["1月", "2月", "3月"],
var_name="月",
value_name="売上",
ignore_index=False
)| 社員ID | 社員名 | 部署 | 月 | 売上 | |
|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 1月 | 120000 |
| 1 | E002 | 鈴木 | 営業部 | 1月 | 98000 |
| 2 | E003 | 田中 | 企画部 | 1月 | 150000 |
| 0 | E001 | 佐藤 | 営業部 | 2月 | 135000 |
| 1 | E002 | 鈴木 | 営業部 | 2月 | 110000 |
| 2 | E003 | 田中 | 企画部 | 2月 | 142000 |
| 0 | E001 | 佐藤 | 営業部 | 3月 | 128000 |
| 1 | E002 | 鈴木 | 営業部 | 3月 | 105000 |
| 2 | E003 | 田中 | 企画部 | 3月 | 160000 |
ignore_index=False を指定すると、変換前のindexが残ります。
今回の例では、元データの0行目、1行目、2行目が、それぞれ月の数だけ繰り返されます。
ただし、通常の分析では新しい連番indexで問題ないことが多いため、最初は省略して構いません。
id_varsの意味:そのまま残す列
id_vars には、melt後もそのまま残したい列を指定します。
今回の例では、次の列です。
社員ID社員名部署
初心者向けに言うと、id_vars は縦にまとめない列です。
| 列 | 指定先 | 理由 |
|---|---|---|
社員ID |
id_vars |
社員を識別するため |
社員名 |
id_vars |
誰の売上かを残すため |
部署 |
id_vars |
部署別集計に使えるため |
1月, 2月, 3月 |
value_vars |
縦にまとめたい月別売上だから |
id_vars に入れない列は、結果に残らないことがあります。
後で使いたい列は、id_vars に入れておきましょう。
df.melt(
id_vars=["社員名"],
value_vars=["1月", "2月", "3月"],
var_name="月",
value_name="売上"
)| 社員名 | 月 | 売上 | |
|---|---|---|---|
| 0 | 佐藤 | 1月 | 120000 |
| 1 | 鈴木 | 1月 | 98000 |
| 2 | 田中 | 1月 | 150000 |
| 3 | 佐藤 | 2月 | 135000 |
| 4 | 鈴木 | 2月 | 110000 |
| 5 | 田中 | 2月 | 142000 |
| 6 | 佐藤 | 3月 | 128000 |
| 7 | 鈴木 | 3月 | 105000 |
| 8 | 田中 | 3月 | 160000 |
この例では、社員名 だけを id_vars にしたため、社員ID と 部署 は結果に残りません。
あとで部署別に集計したいなら、部署 も id_vars に含める必要があります。
value_varsの意味:縦にまとめる列
value_vars には、縦にまとめたい列を指定します。
月別売上データなら、1月、2月、3月 が該当します。
| 引数 | 役割 | 今回の例 |
|---|---|---|
id_vars |
そのまま残す列 | 社員ID, 社員名, 部署 |
value_vars |
縦にまとめる列 | 1月, 2月, 3月 |
value_vars は、「この列たちを1つの項目列と値列にまとめたい」と指定する場所です。
df.melt(
id_vars=["社員ID", "社員名", "部署"],
value_vars=["1月", "3月"],
var_name="月",
value_name="売上"
)| 社員ID | 社員名 | 部署 | 月 | 売上 | |
|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 1月 | 120000 |
| 1 | E002 | 鈴木 | 営業部 | 1月 | 98000 |
| 2 | E003 | 田中 | 企画部 | 1月 | 150000 |
| 3 | E001 | 佐藤 | 営業部 | 3月 | 128000 |
| 4 | E002 | 鈴木 | 営業部 | 3月 | 105000 |
| 5 | E003 | 田中 | 企画部 | 3月 | 160000 |
この例では、value_vars に 1月 と 3月 だけを指定しています。
そのため、2月 は結果に含まれません。
分析対象にしたい列だけを選んで縦にまとめられるのが、value_vars の便利な点です。
var_nameとvalue_nameで列名をわかりやすくする
var_name と value_name を指定しない場合、melt後の列名は variable と value になります。
df.melt(
id_vars=["社員ID", "社員名", "部署"],
value_vars=["1月", "2月", "3月"]
)| 社員ID | 社員名 | 部署 | variable | value | |
|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 1月 | 120000 |
| 1 | E002 | 鈴木 | 営業部 | 1月 | 98000 |
| 2 | E003 | 田中 | 企画部 | 1月 | 150000 |
| 3 | E001 | 佐藤 | 営業部 | 2月 | 135000 |
| 4 | E002 | 鈴木 | 営業部 | 2月 | 110000 |
| 5 | E003 | 田中 | 企画部 | 2月 | 142000 |
| 6 | E001 | 佐藤 | 営業部 | 3月 | 128000 |
| 7 | E002 | 鈴木 | 営業部 | 3月 | 105000 |
| 8 | E003 | 田中 | 企画部 | 3月 | 160000 |
このままでも処理はできますが、variable と value だけでは、何を表している列なのかがわかりにくいです。
そこで、次のように指定します。
| 引数 | 意味 | 今回の指定 |
|---|---|---|
var_name |
元の列名を入れる列の名前 | 月 |
value_name |
元の値を入れる列の名前 | 売上 |
実務でも記事でも、var_name と value_name は指定しておくと読みやすくなります。
sales_long = df.melt(
id_vars=["社員ID", "社員名", "部署"],
value_vars=["1月", "2月", "3月"],
var_name="月",
value_name="売上"
)
sales_long| 社員ID | 社員名 | 部署 | 月 | 売上 | |
|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 1月 | 120000 |
| 1 | E002 | 鈴木 | 営業部 | 1月 | 98000 |
| 2 | E003 | 田中 | 企画部 | 1月 | 150000 |
| 3 | E001 | 佐藤 | 営業部 | 2月 | 135000 |
| 4 | E002 | 鈴木 | 営業部 | 2月 | 110000 |
| 5 | E003 | 田中 | 企画部 | 2月 | 142000 |
| 6 | E001 | 佐藤 | 営業部 | 3月 | 128000 |
| 7 | E002 | 鈴木 | 営業部 | 3月 | 105000 |
| 8 | E003 | 田中 | 企画部 | 3月 | 160000 |
variable と value ではなく、月 と 売上 という列名になりました。
あとで groupby("月") や sales_long["売上"] のように書くときも、意味が読み取りやすくなります。
value_nameは既存の列名と重ならない名前にする
value_name には、melt後の値列の名前を指定します。
この名前は、元のDataFrameにすでにある列名と重ならないようにするのが安全です。
たとえば、元データにすでに 売上 という列があるのに、value_name="売上" と指定すると、列名の重複やエラーの原因になることがあります。
今回のサンプルでは、元データに 売上 列はなく、1月、2月、3月 の値をまとめた列として新しく 売上 という名前を付けています。
| 状況 | おすすめ |
|---|---|
元データに 売上 列がない |
value_name="売上" でよい |
元データにすでに 売上 列がある |
value_name="月別売上" など別名にする |
細かい点ですが、実務データでは列名が増えやすいため、melt後の列名は元の列名と重ならないように確認しておきましょう。
value_varsを省略した場合の注意点
value_vars は省略できます。
ただし、省略すると、id_vars 以外の列がすべて縦にまとめられます。
df.melt(
id_vars=["社員ID", "社員名", "部署"],
var_name="月",
value_name="売上"
)| 社員ID | 社員名 | 部署 | 月 | 売上 | |
|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 1月 | 120000 |
| 1 | E002 | 鈴木 | 営業部 | 1月 | 98000 |
| 2 | E003 | 田中 | 企画部 | 1月 | 150000 |
| 3 | E001 | 佐藤 | 営業部 | 2月 | 135000 |
| 4 | E002 | 鈴木 | 営業部 | 2月 | 110000 |
| 5 | E003 | 田中 | 企画部 | 2月 | 142000 |
| 6 | E001 | 佐藤 | 営業部 | 3月 | 128000 |
| 7 | E002 | 鈴木 | 営業部 | 3月 | 105000 |
| 8 | E003 | 田中 | 企画部 | 3月 | 160000 |
今回のデータでは、id_vars 以外が 1月、2月、3月 だけなので問題ありません。
しかし、実際のCSVには 備考、登録日、メモ のような列が含まれることがあります。
その場合、value_vars を省略すると、意図しない列まで縦にまとめられる可能性があります。
初心者のうちは、value_vars を明示するほうが安全です。
value_varsを省略すると不要な列まで入る例
次のように、元データに 備考 列があるケースを考えます。
備考 は売上ではないため、本来は 月 や 売上 にまとめたくない列です。
df_extra = df.copy()
df_extra["備考"] = ["重点顧客", "通常", "確認中"]
df_extra| 社員ID | 社員名 | 部署 | 1月 | 2月 | 3月 | 備考 | |
|---|---|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 120000 | 135000 | 128000 | 重点顧客 |
| 1 | E002 | 鈴木 | 営業部 | 98000 | 110000 | 105000 | 通常 |
| 2 | E003 | 田中 | 企画部 | 150000 | 142000 | 160000 | 確認中 |
この状態で value_vars を省略すると、id_vars 以外の列がすべて縦にまとめられます。
つまり、1月、2月、3月 だけでなく、備考 まで 月 列に入ってしまいます。
df_extra.melt(
id_vars=["社員ID", "社員名", "部署"],
var_name="月",
value_name="売上"
)| 社員ID | 社員名 | 部署 | 月 | 売上 | |
|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 1月 | 120000 |
| 1 | E002 | 鈴木 | 営業部 | 1月 | 98000 |
| 2 | E003 | 田中 | 企画部 | 1月 | 150000 |
| 3 | E001 | 佐藤 | 営業部 | 2月 | 135000 |
| 4 | E002 | 鈴木 | 営業部 | 2月 | 110000 |
| 5 | E003 | 田中 | 企画部 | 2月 | 142000 |
| 6 | E001 | 佐藤 | 営業部 | 3月 | 128000 |
| 7 | E002 | 鈴木 | 営業部 | 3月 | 105000 |
| 8 | E003 | 田中 | 企画部 | 3月 | 160000 |
| 9 | E001 | 佐藤 | 営業部 | 備考 | 重点顧客 |
| 10 | E002 | 鈴木 | 営業部 | 備考 | 通常 |
| 11 | E003 | 田中 | 企画部 | 備考 | 確認中 |
備考 は売上ではないので、この結果は分析しにくい形です。
このようなミスを防ぐには、縦にまとめたい列を value_vars で明示します。
df_extra.melt(
id_vars=["社員ID", "社員名", "部署", "備考"],
value_vars=["1月", "2月", "3月"],
var_name="月",
value_name="売上"
)| 社員ID | 社員名 | 部署 | 備考 | 月 | 売上 | |
|---|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 重点顧客 | 1月 | 120000 |
| 1 | E002 | 鈴木 | 営業部 | 通常 | 1月 | 98000 |
| 2 | E003 | 田中 | 企画部 | 確認中 | 1月 | 150000 |
| 3 | E001 | 佐藤 | 営業部 | 重点顧客 | 2月 | 135000 |
| 4 | E002 | 鈴木 | 営業部 | 通常 | 2月 | 110000 |
| 5 | E003 | 田中 | 企画部 | 確認中 | 2月 | 142000 |
| 6 | E001 | 佐藤 | 営業部 | 重点顧客 | 3月 | 128000 |
| 7 | E002 | 鈴木 | 営業部 | 通常 | 3月 | 105000 |
| 8 | E003 | 田中 | 企画部 | 確認中 | 3月 | 160000 |
このように、value_vars を指定すると、売上に関係する月別列だけを縦にまとめられます。
実際のCSVでは、メモ列、登録日、区分、備考などが混ざっていることがあります。初心者のうちは、value_vars を省略せずに明示するほうが安全です。
科目別点数データでもmelt()を使う
月別売上だけでなく、科目別点数のようなデータでも melt() は使えます。
ここでは、国語、数学、英語 が横に並んだデータを、科目 列と 点数 列に変換します。
score_df = pd.DataFrame({
"生徒ID": ["S001", "S002", "S003"],
"氏名": ["山田", "田中", "伊藤"],
"クラス": ["A", "A", "B"],
"国語": [82, 75, 90],
"数学": [70, 88, 95],
"英語": [78, 84, 92]
})
score_df| 生徒ID | 氏名 | クラス | 国語 | 数学 | 英語 | |
|---|---|---|---|---|---|---|
| 0 | S001 | 山田 | A | 82 | 70 | 78 |
| 1 | S002 | 田中 | A | 75 | 88 | 84 |
| 2 | S003 | 伊藤 | B | 90 | 95 | 92 |
score_long = score_df.melt(
id_vars=["生徒ID", "氏名", "クラス"],
value_vars=["国語", "数学", "英語"],
var_name="科目",
value_name="点数"
)
score_long| 生徒ID | 氏名 | クラス | 科目 | 点数 | |
|---|---|---|---|---|---|
| 0 | S001 | 山田 | A | 国語 | 82 |
| 1 | S002 | 田中 | A | 国語 | 75 |
| 2 | S003 | 伊藤 | B | 国語 | 90 |
| 3 | S001 | 山田 | A | 数学 | 70 |
| 4 | S002 | 田中 | A | 数学 | 88 |
| 5 | S003 | 伊藤 | B | 数学 | 95 |
| 6 | S001 | 山田 | A | 英語 | 78 |
| 7 | S002 | 田中 | A | 英語 | 84 |
| 8 | S003 | 伊藤 | B | 英語 | 92 |
国語、数学、英語 が 科目 列にまとまり、点数は 点数 列に入りました。
この形にしておくと、科目ごとの平均点を出しやすくなります。
score_long.groupby("科目", as_index=False)["点数"].mean()| 科目 | 点数 | |
|---|---|---|
| 0 | 国語 | 82.333333 |
| 1 | 数学 | 84.333333 |
| 2 | 英語 | 84.666667 |
この例では、melt() で科目ごとに集計しやすい形へ変換し、その後に groupby() で平均点を計算しています。
melt()した後にgroupby()で集計する
melt() のメリットは、変換後に groupby() へつなげやすいことです。
先ほど作成した sales_long を使って、月ごとの売上合計を確認してみます。
monthly_sales = sales_long.groupby("月", as_index=False)["売上"].sum()
monthly_sales| 月 | 売上 | |
|---|---|---|
| 0 | 1月 | 368000 |
| 1 | 2月 | 387000 |
| 2 | 3月 | 393000 |
縦持ちにしておくと、月 という列を基準に集計できます。
| やりたいこと | 例 |
|---|---|
| 月ごとの売上合計 | groupby("月")["売上"].sum() |
| 部署ごとの売上合計 | groupby("部署")["売上"].sum() |
| 社員ごとの平均売上 | groupby("社員名")["売上"].mean() |
melt() は集計の前処理、groupby() は集計本体と考えると整理しやすいです。
melt()した後にvalue_counts()で件数を確認する
melt() 後のカテゴリ列は、value_counts() でも扱いやすくなります。
たとえば、科目別点数データで、科目ごとの行数を確認してみます。
score_long["科目"].value_counts()| count | |
|---|---|
| 科目 | |
| 国語 | 3 |
| 数学 | 3 |
| 英語 | 3 |
この例では、各生徒に3科目分のデータがあるため、各科目が同じ件数になります。
実務では、商品名、カテゴリ、月、地域などを縦持ちにしておくと、カテゴリごとの件数確認がしやすくなります。
melt()した後に棒グラフで可視化する
縦持ちデータに変換すると、Matplotlibの棒グラフにもつなげやすくなります。
ここでは、月ごとの売上合計を棒グラフで表示します。
Google Colabでは、日本語の軸ラベルやタイトルが文字化けする場合があります。この記事では melt() 後にグラフ化へ進む流れを確認することを目的にしているため、基本コードでは英語ラベルを使います。日本語で表示したい場合の対処法は、この後の補足で紹介します。
import matplotlib.pyplot as plt
monthly_sales = sales_long.groupby("月", as_index=False)["売上"].sum()
plt.figure(figsize=(6, 4))
plt.bar(monthly_sales["月"], monthly_sales["売上"])
plt.xlabel("Month")
plt.ylabel("Sales")
plt.title("Monthly Sales")
plt.show()/usr/local/lib/python3.12/dist-packages/IPython/core/pylabtools.py:151: UserWarning: Glyph 26376 (\N{CJK UNIFIED IDEOGRAPH-6708}) missing from font(s) DejaVu Sans.
fig.canvas.print_figure(bytes_io, **kw)

流れは次のとおりです。
- 横持ちデータを用意する
melt()で縦持ちデータに変換するgroupby()で月別に集計する- Matplotlibで棒グラフにする
melt() はグラフを描くメソッドではありません。
ただし、グラフ化しやすいデータの形を作る前処理として役立ちます。
補足:Colabでグラフの日本語ラベルが文字化けするとき
Google ColabでMatplotlibのグラフを描くと、日本語のタイトルや軸ラベルが文字化けすることがあります。
この記事では、まず melt() の流れを理解しやすくするため、基本のグラフでは英語ラベルを使いました。
日本語で表示したい場合は、次のように japanize-matplotlib を使う方法があります。
# Colabで日本語ラベルを使いたい場合
!pip -q install japanize-matplotlib
import matplotlib.pyplot as plt
import japanize_matplotlib
monthly_sales = sales_long.groupby("月", as_index=False)["売上"].sum()
plt.figure(figsize=(6, 4))
plt.bar(monthly_sales["月"], monthly_sales["売上"])
plt.xlabel("月")
plt.ylabel("売上")
plt.title("月別売上")
plt.show()この補足は、グラフの表示環境に関する内容です。
melt() の使い方そのものは、英語ラベルでも日本語ラベルでも変わりません。
melt()とpivot()・pivot_table()の違い
melt()、pivot()、pivot_table() は、どれもDataFrameの形を変える場面で出てきます。
違いは、変換する向きと集計の有無です。
| メソッド | 主な役割 | 変換の向き | 集計 |
|---|---|---|---|
melt() |
横に並んだ列を縦にまとめる | 横持ち → 縦持ち | しない |
pivot() |
縦長データを横に広げる | 縦持ち → 横持ち | しない |
pivot_table() |
集計しながら横に広げる | 縦持ち → 集計表 | する |
melt() と pivot() は、ざっくり言うと逆方向の処理です。
# melt()で作った縦持ちデータ
sales_long| 社員ID | 社員名 | 部署 | 月 | 売上 | |
|---|---|---|---|---|---|
| 0 | E001 | 佐藤 | 営業部 | 1月 | 120000 |
| 1 | E002 | 鈴木 | 営業部 | 1月 | 98000 |
| 2 | E003 | 田中 | 企画部 | 1月 | 150000 |
| 3 | E001 | 佐藤 | 営業部 | 2月 | 135000 |
| 4 | E002 | 鈴木 | 営業部 | 2月 | 110000 |
| 5 | E003 | 田中 | 企画部 | 2月 | 142000 |
| 6 | E001 | 佐藤 | 営業部 | 3月 | 128000 |
| 7 | E002 | 鈴木 | 営業部 | 3月 | 105000 |
| 8 | E003 | 田中 | 企画部 | 3月 | 160000 |
# 縦持ちデータを、社員名×月の横持ちデータに戻す例
sales_pivot = sales_long.pivot(
index="社員名",
columns="月",
values="売上"
)
sales_pivot| 月 | 1月 | 2月 | 3月 |
|---|---|---|---|
| 社員名 | |||
| 佐藤 | 120000 | 135000 | 128000 |
| 田中 | 150000 | 142000 | 160000 |
| 鈴木 | 98000 | 110000 | 105000 |
この記事では melt() を中心に扱っています。
pivot() や pivot_table() の詳しい使い方は、集計表を作る場面で学ぶと理解しやすいです。
melt()とconcat()・merge()の違い
melt() は、1つのDataFrameの形を変える処理です。
concat() や merge() は、複数のDataFrameを結合する処理です。
| メソッド | 目的 | 例 |
|---|---|---|
melt() |
1つのDataFrameの形を変える | 月別列を、月列と売上列に変換する |
concat() |
複数のDataFrameを上下・左右に結合する | 1月CSV、2月CSV、3月CSVを縦に結合する |
merge() |
キー列を使って別表を結合する | 売上データに社員マスタを結合する |
「列を縦にまとめたい」のか、「別のDataFrameをくっつけたい」のかで使い分けましょう。
melt()と他のメソッドを迷ったときの使い分け
melt() は便利ですが、すべてのデータ整形に使うメソッドではありません。
目的別に整理すると、次のようになります。
| やりたいこと | 使うメソッド | 例 |
|---|---|---|
| 横に並んだ月・科目・商品列を縦にまとめたい | melt() |
1月, 2月, 3月 → 月, 売上 |
| 縦持ちデータを横持ちの表に戻したい | pivot() |
月 列を 1月, 2月, 3月 の列に戻す |
| 集計しながら横持ちの表を作りたい | pivot_table() |
部署×月の売上合計表を作る |
| 複数のDataFrameを上下に結合したい | concat() |
1月CSV、2月CSV、3月CSVを縦に結合する |
| 別表の情報をキーで結合したい | merge() |
売上データに社員マスタを結合する |
| 列名だけを変更したい | rename() |
氏名 を 社員名 に変更する |
検索していると、melt()、pivot()、concat()、merge() がまとめて出てくることがあります。
しかし、melt() の役割はあくまで、1つのDataFrameの中で、横に並んだ列を縦にまとめることです。
「列を縦にまとめたいのか」「表を結合したいのか」「列名を変えたいだけなのか」を先に分けると、使うメソッドを選びやすくなります。
よくあるミスと注意点
melt() で初心者がつまずきやすい点を整理します。
| よくあるミス | 対策 |
|---|---|
melt() が集計する処理だと思う |
melt() は形を変えるだけ。集計は groupby() などで行う |
id_vars と value_vars を逆にする |
id_vars は残す列、value_vars は縦にまとめる列 |
variable と value の意味がわからない |
var_name と value_name を指定する |
value_vars を省略して意図しない列まで変換する |
初心者のうちは value_vars を明示する |
value_name を既存の列名と重ねてしまう |
元データにない列名を付ける |
melt() 後にindexが変わって驚く |
通常は新しいindexで問題ない。必要なら ignore_index=False を使う |
| 列名変更やDataFrame結合にもmelt()を使おうとする | 列名変更は rename()、結合は concat() / merge() を使う |
特に大事なのは、横持ちデータが悪いわけではないという点です。
表として見るだけなら、横持ちのままで問題ありません。
一方で、集計・条件抽出・グラフ化をしやすくしたい場合は、melt() で縦持ちにすることを検討するとよいです。
前処理の流れの中でmelt()を使うタイミング
melt() は、集計や可視化の直前に使うことが多いです。
流れとしては、次のように考えると自然です。
read_csv()でCSVを読み込むhead()やinfo()でデータを確認する- 欠損値、重複、型、列名を整える
- 横持ちデータなら
melt()で縦持ちに変換する groupby()やvalue_counts()で集計する- Matplotlibでグラフ化する
月別売上、科目別点数、商品別数量のように、同じ種類の項目が横に並んでいるデータでは、melt() を検討するとよいです。
補足:CSVで読み込んだデータにもmelt()は使える
実際の分析では、手入力のサンプルデータではなく、CSVファイルを読み込んだDataFrameに対して melt() を使うこともあります。
考え方は同じです。
- 残す列を
id_varsに指定する - 縦にまとめる列を
value_varsに指定する - 元の列名を入れる列名を
var_nameで決める - 値を入れる列名を
value_nameで決める
CSVを読み込んだ直後は、まず head() や info() で列名を確認してから、melt() を使うと安全です。
# 例:CSVを読み込んだあとにmelt()する場合
# df_csv = pd.read_csv("sales.csv")
# 実際には、CSVの列名に合わせて id_vars と value_vars を指定します。
# long_df = df_csv.melt(
# id_vars="商品名",
# value_vars=["1月", "2月", "3月"],
# var_name="月",
# value_name="販売数"
# )軽く知っておきたい関連メソッド
melt() に似た変形処理として、stack()、unstack()、wide_to_long() があります。
ただし、初心者のうちは、まず melt() の基本を理解すれば十分です。
| メソッド | ざっくりした役割 | この記事での扱い |
|---|---|---|
melt() |
横持ちを縦持ちに変換する | 中心 |
stack() / unstack() |
インデックスを使って形を変える | 軽く触れるだけ |
wide_to_long() |
規則的な列名をもとに縦長へ変換する | 発展 |
pivot() |
縦持ちを横持ちへ戻す | 比較対象 |
pivot_table() |
集計しながら横持ちへ変換する | 比較対象 |
最初からすべて覚える必要はありません。まずは、melt() を「横に増えた列を縦にまとめる基本メソッド」として理解しましょう。
まとめ
この記事では、Pandasの melt() を使って、横持ちデータを縦持ちデータへ変換する方法を解説しました。
ポイントは次のとおりです。
melt()は、横に広がった列を縦長にまとめるメソッドid_varsは、そのまま残す列value_varsは、縦にまとめる列var_nameは、元の列名を入れる列の名前value_nameは、元の値を入れる列の名前value_varsを省略すると、意図しない列まで縦にまとめることがあるmelt()後は、横に並んでいた値を縦に並べ直すため、行数が増えることがあるmelt()は集計ではなく、集計・可視化しやすい形へ整える前処理melt()とpivot()は、変換の向きが逆melt()後は、groupby()、value_counts()、Matplotlibにつなげやすい
月別売上、科目別点数、商品別数量のように、同じ種類の項目が横に並んでいる表では、melt() が役立ちます。
横持ちの表を見て「集計しにくい」「グラフにしにくい」と感じたら、まず melt() で縦持ちにできないかを考えてみましょう。
次に読みたい関連記事
Pandas DataFrame入門|作り方・基本操作をわかりやすく解説
DataFrameの行・列の基本構造を確認したい方におすすめです。Google Colab CSV 読み込み&保存入門|pandas で read_csv と to_csv を徹底解説
CSVを読み込んでから前処理する流れを確認したい方におすすめです。Pandas pivotとpivot_tableの違い|重複データ対応と集計方法
melt()と逆方向の変形であるpivot()/pivot_table()を学びたい方におすすめです。Pandas groupby×aggの使い方|基本の集計とaggの書き方を例で解説
melt()後に集計へ進みたい方におすすめです。pandas value_counts()の使い方|件数集計・割合表示・欠損値の数え方を解説
縦持ちにしたカテゴリ列の件数を数えたい方におすすめです。Matplotlib 棒グラフ入門:横棒・グループ化・積み上げまで解説
集計したデータを棒グラフで可視化したい方におすすめです。Pandas concat完全ガイド|複数CSVからDataFrameを縦横結合する方法
複数のDataFrameを結合する処理とmelt()の違いを整理したい方におすすめです。pandas mergeの使い方|DataFrame結合(inner, left, outer)の違いと実例
キー列を使って別表を結合する方法を学びたい方におすすめです。
pandas melt()は何をするメソッドですか?
melt() は、横に広がった列を縦長にまとめるメソッドです。
たとえば、1月、2月、3月 のような列を、月 列と 売上 列に変換できます。
melt()はどんなときに使いますか?
月別売上、科目別点数、商品別数量のように、同じ種類の情報が複数の列に分かれているときに使います。
集計、条件抽出、グラフ化をしやすい形に整えたい場合に向いています。
id_varsとvalue_varsの違いは何ですか?
id_vars は、そのまま残す列です。value_vars は、縦にまとめる列です。
月別売上データなら、社員名や部署は id_vars、1月、2月、3月 は value_vars に指定します。
value_varsを省略してもよいですか?
省略はできます。
ただし、id_vars 以外の列がすべて縦にまとめられるため、備考 や メモ など不要な列まで入ることがあります。
初心者のうちは、value_vars を明示するほうが安全です。
variable列とvalue列は何を意味しますか?
variable 列には、元の列名が入ります。value 列には、元のセルの値が入ります。var_name と value_name を指定すると、月、売上 のようにわかりやすい列名にできます。
melt()後に行数が増えるのはなぜですか?
横に並んでいた値を縦に並べ直すためです。
たとえば、3人分のデータに3か月分の列がある場合、melt() 後は3人×3か月で9行になります。
melt()とpivot()の違いは何ですか?
melt() は、横持ちデータを縦持ちデータに変換します。pivot() は、縦持ちデータを横持ちデータに変換します。
ざっくり言うと、逆方向の処理です。
melt()したあとにgroupby()やグラフ化はできますか?
できます。melt() で縦持ちにしたあと、groupby() で集計し、Matplotlibでグラフ化する流れはよく使います。
コメント