
年齢、売上金額、点数のような数値データは、そのまま集計すると細かくなりすぎることがあります。
たとえば、年齢を1歳ごとに集計するよりも、10代・20代・30代のように分けた方が、全体の傾向を見やすい場面があります。売上金額も、1円単位で見るより、低価格・中価格・高価格のように価格帯で見た方が、分析しやすいことがあります。
このように、連続した数値を分析しやすい区間に分けたいときに使うのが、Pandasのpd.cut()です。
先に結論を言うと、pd.cut()は数値を「年代」「価格帯」「ランク」のようなカテゴリに分け、集計や可視化につなげるための前処理です。
たとえば、次のように考えると使いどころが分かりやすくなります。
| 元の数値列 | pd.cut()で作る列 |
その後にできること |
|---|---|---|
| 年齢 | 年代 | 年代別に人数や平均値を見る |
| 点数 | 点数ランク | ランク別に人数を数える |
| 購入金額 | 価格帯 | 価格帯ごとに集計する |
pd.cut()は、数値をただ文字列に変える関数ではありません。細かい数値を、分析で使いやすいまとまりに変える関数です。
- この記事でわかること
- Pandas DataFrame入門シリーズの中での位置づけ
- pd.cut()とは何か
- pd.cut()の主な引数一覧
- サンプルデータを作成する
- 年齢を年代に分ける基本例
- binsとlabelsの対応関係
- bins=3のように区間数だけ指定することもできる
- 自動分割の境界値を確認したいときはretbins=True
- 区間表示の小数が長いときはprecisionで見やすくできる
- 処理前→処理後で見るcut()の結果
- value_counts()でカテゴリごとの件数を数える
- pd.cut()で区間分けした結果を棒グラフで可視化する
- groupby()でカテゴリ別に集計する
- 点数をランクに分ける例
- 売上金額・購入金額を価格帯に分ける例
- cut()・qcut()・np.where()の使い分け
- 境界値・NaN・よくあるミス
- ヒストグラムのbinsとpd.cut()のbinsは同じですか?
- データ分析の流れの中でのpd.cut()の位置づけ
- まとめ:pd.cut()は数値を集計しやすいカテゴリに変える前処理
- 関連記事:次に読むと理解しやすい記事
- カテゴリから探す
- pandasのcut()は何をする関数ですか?
- binsとlabelsは何を指定するものですか?
- labelsの数はいくつにすればよいですか?
- bins=3とは何ですか?
- include_lowest=Trueはいつ使いますか?
- pd.cut()でNaNが出るのはなぜですか?
- 境界値の20や30はどちらの区間に入りますか?
- right=Falseはいつ使いますか?
- retbins=Trueはいつ使いますか?
- precisionは何を指定するものですか?
- cut()とqcut()の違いは何ですか?
- np.where()とcut()はどう使い分けますか?
- cut()で作ったカテゴリをvalue_counts()やgroupby()で使えますか?
- cut()で作ったカテゴリをグラフで確認できますか?
- ヒストグラムのbinsとpd.cut()のbinsは同じですか?
この記事でわかること
この記事では、pandas cut()の使い方を、初心者が迷いやすいポイントに絞って解説します。
pd.cut()がどんな場面で役立つかbinsとlabelsの意味bins=3のように、区間数だけ指定して分ける方法bins=3で区間表示に端数が出る理由pd.cut()でよく使う主な引数一覧retbins=Trueで自動分割された境界値を確認する方法precisionで区間表示を見やすくするときの注意点include_lowest=Trueやright=Falseで境界値を調整する方法cut()、qcut()、np.where()の使い分けpd.cut()で作ったカテゴリを棒グラフで確認する方法NaNが出る理由と確認ポイント
最初に結論を言うと、pd.cut()は数値を分析しやすいカテゴリに変える前処理です。
年齢、点数、購入金額のような数値を、年代・ランク・価格帯として集計したいときに役立ちます。
Pandas DataFrame入門シリーズの中での位置づけ
このテーマは、Pandasの前処理と集計をつなぐ内容です。
まずhead()、info()、describe()でデータを確認し、必要に応じてastype()やfillna()で整えます。その後、年齢や売上のような数値列をpd.cut()でカテゴリ化すると、value_counts()やgroupby()で集計しやすくなります。
つまり、pd.cut()は次のような流れの中で使うと理解しやすいです。
DataFrameの確認 → 型・欠損値の確認 → 数値列を区間分け → 件数集計・グループ集計 → 可視化
pd.cut()とは何か
pd.cut()は、数値データを指定した区間ごとに分けるための関数です。
たとえば、次のような使い方ができます。
| 元の数値 | pd.cut()で作るカテゴリ |
|---|---|
| 18 | 10代以下 |
| 25 | 20代 |
| 34 | 30代 |
| 47 | 40代 |
| 62 | 50代以上 |
このように、細かい数値をそのまま使うのではなく、分析しやすいまとまりに変換するのがpd.cut()の役割です。
最初に判断基準を整理すると、次のようになります。
| やりたいこと | 向いている方法 |
|---|---|
| 数値を決まった範囲で分けたい | pd.cut() |
| データ数がなるべく均等になるように分けたい | pd.qcut() |
| 2択の条件分岐をしたい | np.where() |
| 条件に合う行だけ値を入れたい | loc |
| 作ったカテゴリの件数を数えたい | value_counts() |
| 作ったカテゴリごとに平均や合計を出したい | groupby() |
この記事では、特に「年齢を年代に分ける」「点数をランクに分ける」「価格帯ごとに集計する」といった、初心者が実際に使いやすい例に絞って解説します。
pd.cut()の主な引数一覧
pd.cut()にはいくつかの引数がありますが、初心者が最初にすべてを暗記する必要はありません。
まずは、binsで区切り位置を決め、labelsで分かりやすい名前を付けると覚えると十分です。
そのうえで、境界値や自動分割で迷ったときに、right、include_lowest、retbins、precisionを確認します。
| 引数 | 意味 | 初心者がまず見るポイント |
|---|---|---|
x |
区間分けする数値データ | DataFrameの列を指定することが多い |
bins |
区切り位置、または区間数 | 最重要。[0, 19, 29]のようなリストや、3のような区間数を指定できる |
labels |
区間につける名前 | 「10代以下」「20代」など、読者に伝わる名前にする |
right |
右側の境界を含めるか | 初期設定はTrue。境界値で迷うときに確認する |
include_lowest |
最初の区間の下限を含めるか | 0点、0円、最小値を含めたいときに役立つ |
retbins |
実際に使われた境界値を返すか | bins=3のような自動分割で、境界値を確認したいときに使う |
precision |
区間ラベルに表示される境界値の桁数 | 自動分割の区間表示が長いときに見やすくする。元データを丸める指定ではない |
この記事では、まず実務で使いやすいbinsとlabelsを中心に説明します。
その後で、必要に応じてright、include_lowest、retbins、precisionも確認します。
サンプルデータを作成する
まずは、Google Colabでそのまま実行できる小さなDataFrameを作ります。
今回は、名前、年齢、点数、購入金額を持つデータを使います。
年齢は年代分け、点数はランク分け、購入金額は価格帯分けに使います。
import pandas as pd
import numpy as np
df = pd.DataFrame({
"名前": ["佐藤", "田中", "鈴木", "高橋", "伊藤", "渡辺", "山本", "中村", "小林", "加藤"],
"年齢": [18, 20, 24, 29, 30, 35, 42, 49, 55, 68],
"点数": [45, 62, 78, 88, 91, 55, 73, 69, 82, 96],
"購入金額": [800, 1500, 2400, 3200, 4800, 5200, 7600, 9100, 12000, 15000]
})
df| 名前 | 年齢 | 点数 | 購入金額 | |
|---|---|---|---|---|
| 0 | 佐藤 | 18 | 45 | 800 |
| 1 | 田中 | 20 | 62 | 1500 |
| 2 | 鈴木 | 24 | 78 | 2400 |
| 3 | 高橋 | 29 | 88 | 3200 |
| 4 | 伊藤 | 30 | 91 | 4800 |
| 5 | 渡辺 | 35 | 55 | 5200 |
| 6 | 山本 | 42 | 73 | 7600 |
| 7 | 中村 | 49 | 69 | 9100 |
| 8 | 小林 | 55 | 82 | 12000 |
| 9 | 加藤 | 68 | 96 | 15000 |
このデータには、次の3つの数値列があります。
| 列名 | この記事での使い方 |
|---|---|
| 年齢 | 年代に分ける |
| 点数 | ランクに分ける |
| 購入金額 | 価格帯に分ける |
数値列の型や欠損値を先に確認したい場合は、info()やdescribe()を使います。
型変換が必要な場合は、astype()で整えてからcut()を使うと安全です。
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 名前 10 non-null object
1 年齢 10 non-null int64
2 点数 10 non-null int64
3 購入金額 10 non-null int64
dtypes: int64(3), object(1)
memory usage: 452.0+ bytesdf.describe()| 年齢 | 点数 | 購入金額 | |
|---|---|---|---|
| count | 10.000000 | 10.000000 | 10.000000 |
| mean | 37.000000 | 73.900000 | 6160.000000 |
| std | 16.295875 | 16.400881 | 4703.237656 |
| min | 18.000000 | 45.000000 | 800.000000 |
| 25% | 25.250000 | 63.750000 | 2600.000000 |
| 50% | 32.500000 | 75.500000 | 5000.000000 |
| 75% | 47.250000 | 86.500000 | 8725.000000 |
| max | 68.000000 | 96.000000 | 15000.000000 |
年齢を年代に分ける基本例
まずは、pd.cut()で年齢を年代に分けます。
基本形は次のように考えます。
pd.cut(分けたい数値列, bins=区切り位置, labels=区間名)
ここでは、年齢を次のように分けます。
| 年齢の範囲 | ラベル |
|---|---|
| 0〜19歳 | 10代以下 |
| 20〜29歳 | 20代 |
| 30〜39歳 | 30代 |
| 40〜49歳 | 40代 |
| 50〜100歳 | 50代以上 |
このように「自分で決めた範囲」で分けたいときに、pd.cut()が役立ちます。
age_bins = [0, 19, 29, 39, 49, 100]
age_labels = ["10代以下", "20代", "30代", "40代", "50代以上"]
df["年代"] = pd.cut(
df["年齢"],
bins=age_bins,
labels=age_labels,
include_lowest=True
)
df[["名前", "年齢", "年代"]]| 名前 | 年齢 | 年代 | |
|---|---|---|---|
| 0 | 佐藤 | 18 | 10代以下 |
| 1 | 田中 | 20 | 20代 |
| 2 | 鈴木 | 24 | 20代 |
| 3 | 高橋 | 29 | 20代 |
| 4 | 伊藤 | 30 | 30代 |
| 5 | 渡辺 | 35 | 30代 |
| 6 | 山本 | 42 | 40代 |
| 7 | 中村 | 49 | 40代 |
| 8 | 小林 | 55 | 50代以上 |
| 9 | 加藤 | 68 | 50代以上 |
年齢列をもとに、年代列が新しく作られました。
ここでは、最初の区間の下限も含めるためにinclude_lowest=Trueを指定しています。今回のサンプルでは0歳はありませんが、実データでは最小値が区間から外れてNaNになるのを防ぎやすくなります。
ここで大切なのは、pd.cut()が「新しい列を作る関数」そのものではないことです。
実際には、pd.cut()で作った結果を、df["年代"] = ...のようにDataFrameへ保存しています。
新しい列を追加する基本を詳しく確認したい場合は、df['列名']やassign()を扱う記事とあわせて読むと理解しやすくなります。
binsとlabelsの対応関係
pd.cut()で初心者が迷いやすいのが、binsとlabelsの数です。
binsは区切り位置、labelsは区間につける名前です。
binsの数とlabelsの数は同じではありません。
たとえば、次のように指定した場合を考えます。
bins = [0, 19, 29, 39, 49, 100]
labels = ["10代以下", "20代", "30代", "40代", "50代以上"]
対応関係は次のようになります。
binsで作られる区間 |
labels |
|---|---|
| 0以上19以下 | 10代以下 |
| 19より大きく29以下 | 20代 |
| 29より大きく39以下 | 30代 |
| 39より大きく49以下 | 40代 |
| 49より大きく100以下 | 50代以上 |
区切り点が6個あると、区間は5個できます。
そのため、labelsも5個必要です。
今回のように最初の区間の下限も含めたい場合は、include_lowest=Trueを指定しておくと安全です。たとえば、0歳や0点のような最小値を区間に含めたいときに役立ちます。
bins=3のように区間数だけ指定することもできる
binsには、区切り位置のリストだけでなく、区間の数を指定することもできます。
たとえば、次のように書くと、点数列を3つの区間に分けられます。
pd.cut(df["点数"], bins=3)
この書き方では、Pandasがデータの最小値と最大値をもとに、ほぼ同じ幅の区間を自動で作ります。
まず大まかに分布を分けて確認したいときには便利です。
ただし、自動分割では「60点以上は合格」「80点以上は高得点」のような意味のある基準になるとは限りません。
そのため、読者やチームに説明する列を作る場合は、自分でbins=[0, 59, 79, 100]のように区切り位置を指定し、labelsで名前を付ける方が分かりやすいです。
df["点数_3分割"] = pd.cut(df["点数"], bins=3)
df[["名前", "点数", "点数_3分割"]]| 名前 | 点数 | 点数_3分割 | |
|---|---|---|---|
| 0 | 佐藤 | 45 | (44.949, 62.0] |
| 1 | 田中 | 62 | (44.949, 62.0] |
| 2 | 鈴木 | 78 | (62.0, 79.0] |
| 3 | 高橋 | 88 | (79.0, 96.0] |
| 4 | 伊藤 | 91 | (79.0, 96.0] |
| 5 | 渡辺 | 55 | (44.949, 62.0] |
| 6 | 山本 | 73 | (62.0, 79.0] |
| 7 | 中村 | 69 | (62.0, 79.0] |
| 8 | 小林 | 82 | (79.0, 96.0] |
| 9 | 加藤 | 96 | (79.0, 96.0] |
bins=3では、Pandasが最小値から最大値までをもとに、ほぼ同じ幅の区間へ分けます。
このとき、最小値や最大値をきちんと含めるために、区間の端が少し調整されることがあります。
そのため、表示される区間名が (44.949, 62.0] のように端数を含む形になり、初心者には少し読みづらく見える場合があります。
ここで大事なのは、bins=3は自動でざっくり3分割する指定だということです。
「要復習」「標準」「高得点」のように意味を持たせたい場合は、labelsを指定して分かりやすい名前を付けると読みやすくなります。
自動分割の境界値を確認したいときはretbins=True
bins=3のように区間数だけを指定した場合、Pandasが自動で区切り位置を決めます。
ただ、表示される区間だけを見ても、実際にどこで区切られているのか分かりにくいことがあります。
特に、区間表示に小数が出ている場合は、「なぜこの数字になったのか」が気になりやすいです。
その場合は、retbins=Trueを使うと、実際に使われた境界値を確認できます。
score_categories, score_bins = pd.cut(
df["点数"],
bins=3,
retbins=True
)
score_binsarray([44.949, 62. , 79. , 96. ])retbins=Trueを指定すると、カテゴリ分けの結果と、実際に使われた境界値が返ります。
初心者のうちは必須ではありません。
ただし、bins=3のような自動分割を使ったときに、どこで区切られたのかを確認したい場合に便利です。
記事やレポートで結果を説明するなら、自動分割のまま使うより、境界値を確認したうえでbins=[0, 59, 79, 100]のように明示的な基準へ直す方が伝わりやすい場合もあります。
区間表示の小数が長いときはprecisionで見やすくできる
bins=3のような自動分割では、区間が小数で表示されることがあります。
たとえば、(44.949, 62.0]のような表示は、初心者には少し読みにくいかもしれません。
このようなときは、precisionで区間ラベルに表示される境界値の桁数を調整できます。
ただし、precisionは元データの点数を丸める指定ではありません。
あくまで、pd.cut()で作られる区間表示を見やすくするための指定だと考えると分かりやすいです。
分析の基準を明確にしたい場合は、precisionで見た目を整えるよりも、bins=[0, 59, 79, 100]のように自分で区切り位置を決め、labels=["要復習", "標準", "高得点"]のように名前を付ける方が実務では伝わりやすくなります。
pd.cut(df["点数"], bins=3, precision=1)| 点数 | |
|---|---|
| 0 | (44.9, 62.0] |
| 1 | (44.9, 62.0] |
| 2 | (62.0, 79.0] |
| 3 | (79.0, 96.0] |
| 4 | (79.0, 96.0] |
| 5 | (44.9, 62.0] |
| 6 | (62.0, 79.0] |
| 7 | (62.0, 79.0] |
| 8 | (79.0, 96.0] |
| 9 | (79.0, 96.0] |
上の例では、区間表示が少し短くなります。
ただし、precisionを指定しても、元の点数列そのものが丸められるわけではありません。
また、「何点から何点までをどのランクにするか」という分析上の基準を決める指定でもありません。
そのため、初心者のうちは次のように使い分けると安全です。
| やりたいこと | 使う指定 |
|---|---|
| 自動分割の表示を少し見やすくしたい | precision |
| 点数ランクや価格帯の基準を明確にしたい | binsをリストで指定する |
| 読者に分かりやすい区間名を付けたい | labelsを指定する |
処理前→処理後で見るcut()の結果
pd.cut()の役割は、処理前と処理後で見ると分かりやすいです。
| 処理前 | 処理後 |
|---|---|
| 年齢だけがある | 年齢から年代列が作られる |
| 18 | 10代以下 |
| 24 | 20代 |
| 35 | 30代 |
| 49 | 40代 |
| 68 | 50代以上 |
コードでも、処理前と処理後を並べて確認してみます。
before_after = pd.DataFrame({
"処理前_年齢": df["年齢"],
"処理後_年代": df["年代"]
})
before_after| 処理前_年齢 | 処理後_年代 | |
|---|---|---|
| 0 | 18 | 10代以下 |
| 1 | 20 | 20代 |
| 2 | 24 | 20代 |
| 3 | 29 | 20代 |
| 4 | 30 | 30代 |
| 5 | 35 | 30代 |
| 6 | 42 | 40代 |
| 7 | 49 | 40代 |
| 8 | 55 | 50代以上 |
| 9 | 68 | 50代以上 |
pd.cut()を使うと、数値列をそのまま残しつつ、分析用のカテゴリ列を追加できます。
年齢の数値そのものを消してしまうのではなく、年齢列と年代列の両方を残すと、あとから確認しやすくなります。
value_counts()でカテゴリごとの件数を数える
pd.cut()で年代列を作ったら、次に知りたくなるのは「各年代に何人いるか」です。
このときは、value_counts()を使います。
ここでの主役はpd.cut()で作ったカテゴリ列です。
value_counts()はカテゴリを作る関数ではなく、作ったカテゴリの件数を数える関数です。
df["年代"].value_counts(sort=False)| count | |
|---|---|
| 年代 | |
| 10代以下 | 1 |
| 20代 | 3 |
| 30代 | 2 |
| 40代 | 2 |
| 50代以上 | 2 |
sort=Falseを指定すると、カテゴリの順番に近い形で表示されます。
年代別の件数を見たい場合は、次のような流れになります。
pd.cut()で年代列を作るvalue_counts()で年代ごとの件数を数える
件数集計そのものを詳しく学びたい場合は、value_counts()の記事に進むと理解しやすいです。
pd.cut()で区間分けした結果を棒グラフで可視化する
value_counts()で件数を確認できたら、棒グラフにすると「どの区間にデータが多いのか」をさらに確認しやすくなります。
ここで大切なのは、グラフが主役ではなく、pd.cut()で作ったカテゴリ列を確認するための補助として使うことです。
今回は、年代ごとの人数を棒グラフで見てみます。
なお、ColabやWordPressの表示環境によって日本語が文字化けすることを避けるため、グラフ用の横軸ラベルだけ英数字に置き換えています。元の年代列は日本語のままです。
import matplotlib.pyplot as plt
# pd.cut()で作った「年代」列を集計
age_counts = df["年代"].value_counts(sort=False)
# グラフ表示用に、横軸ラベルだけ英数字へ置き換える
age_counts_for_plot = age_counts.copy()
age_counts_for_plot.index = ["under_19", "20s", "30s", "40s", "50_plus"]
ax = age_counts_for_plot.plot(kind="bar")
ax.set_title("Count by age group")
ax.set_xlabel("Age group")
ax.set_ylabel("Count")
plt.tight_layout()
plt.show()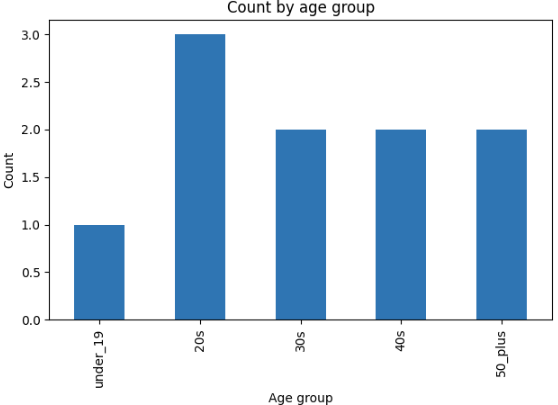
棒グラフにすると、pd.cut()で作ったカテゴリごとの人数を視覚的に確認できます。
表だけでも件数は分かりますが、グラフにすると「どの区間が多いのか」「少ない区間はどこか」が一目で分かりやすくなります。
ただし、この記事の主役はMatplotlibではありません。
まずは、pd.cut()でカテゴリ列を作り、value_counts()で件数を確認し、必要に応じて棒グラフで見やすくする、という流れで考えると十分です。
groupby()でカテゴリ別に集計する
pd.cut()で作ったカテゴリ列は、groupby()にも使えます。
たとえば、年代ごとに平均点や平均購入金額を見たい場合です。
df.groupby("年代", observed=True).agg(
平均点=("点数", "mean"),
平均購入金額=("購入金額", "mean"),
人数=("名前", "count")
)| 平均点 | 平均購入金額 | 人数 | |
|---|---|---|---|
| 年代 | |||
| 10代以下 | 45.0 | 800.000000 | 1 |
| 20代 | 76.0 | 2366.666667 | 3 |
| 30代 | 73.0 | 5000.000000 | 2 |
| 40代 | 71.0 | 8350.000000 | 2 |
| 50代以上 | 89.0 | 13500.000000 | 2 |
年代ごとに、平均点・平均購入金額・人数を集計できました。
このように、pd.cut()は集計の前準備として使うと便利です。
groupby()そのものが主役ではなく、ここでは集計しやすいカテゴリを先に作ることがポイントです。
ここでは、groupby()にobserved=Trueを指定しています。これは、カテゴリ列を集計するときに、実際にデータに存在するカテゴリを中心に表示するための指定です。初心者のうちは、pd.cut()で作ったカテゴリ列をgroupby()する場合は、この形で確認すれば大丈夫です。
点数をランクに分ける例
次に、点数をランクに分けてみます。
ここでは、点数を次の3つに分けます。
| 点数の範囲 | ランク |
|---|---|
| 0〜59点 | 要復習 |
| 60〜79点 | 標準 |
| 80〜100点 | 高得点 |
点数のように、一定の基準でランク分けしたい場合にもpd.cut()が使えます。
ここでは下限の0点も「要復習」に含めたいので、include_lowest=Trueを指定します。
この指定を入れておくと、binsの最初の値と同じデータがNaNになりにくくなります。
score_bins = [0, 59, 79, 100]
score_labels = ["要復習", "標準", "高得点"]
df["点数ランク"] = pd.cut(
df["点数"],
bins=score_bins,
labels=score_labels,
include_lowest=True
)
df[["名前", "点数", "点数ランク"]]| 名前 | 点数 | 点数ランク | |
|---|---|---|---|
| 0 | 佐藤 | 45 | 要復習 |
| 1 | 田中 | 62 | 標準 |
| 2 | 鈴木 | 78 | 標準 |
| 3 | 高橋 | 88 | 高得点 |
| 4 | 伊藤 | 91 | 高得点 |
| 5 | 渡辺 | 55 | 要復習 |
| 6 | 山本 | 73 | 標準 |
| 7 | 中村 | 69 | 標準 |
| 8 | 小林 | 82 | 高得点 |
| 9 | 加藤 | 96 | 高得点 |
点数をランクに分けると、1点ごとの差ではなく、全体の傾向を見やすくなります。
たとえば、どのランクの人数が多いかを確認できます。
df["点数ランク"].value_counts(sort=False)| count | |
|---|---|
| 点数ランク | |
| 要復習 | 2 |
| 標準 | 4 |
| 高得点 | 4 |
売上金額・購入金額を価格帯に分ける例
購入金額や売上金額も、pd.cut()と相性がよい列です。
ここでは、購入金額を次のように価格帯に分けます。
| 購入金額の範囲 | 価格帯 |
|---|---|
| 0〜2,000円 | 低価格 |
| 2,001〜5,000円 | 中価格 |
| 5,001〜10,000円 | 高価格 |
| 10,001〜20,000円 | かなり高い |
金額をそのまま1円単位で集計するより、価格帯で見る方が傾向をつかみやすいことがあります。
購入金額でも、0円を下限として含めたい場合はinclude_lowest=Trueを指定しておくと安全です。
特に「0〜2,000円」のように表で説明している場合は、コード側も下限を含める形にそろえると読み手が迷いにくくなります。
price_bins = [0, 2000, 5000, 10000, 20000]
price_labels = ["低価格", "中価格", "高価格", "かなり高い"]
df["価格帯"] = pd.cut(
df["購入金額"],
bins=price_bins,
labels=price_labels,
include_lowest=True
)
df[["名前", "購入金額", "価格帯"]]| 名前 | 購入金額 | 価格帯 | |
|---|---|---|---|
| 0 | 佐藤 | 800 | 低価格 |
| 1 | 田中 | 1500 | 低価格 |
| 2 | 鈴木 | 2400 | 中価格 |
| 3 | 高橋 | 3200 | 中価格 |
| 4 | 伊藤 | 4800 | 中価格 |
| 5 | 渡辺 | 5200 | 高価格 |
| 6 | 山本 | 7600 | 高価格 |
| 7 | 中村 | 9100 | 高価格 |
| 8 | 小林 | 12000 | かなり高い |
| 9 | 加藤 | 15000 | かなり高い |
作成した価格帯列を使うと、価格帯ごとの人数や平均点などを確認できます。
df.groupby("価格帯", observed=True).agg(
人数=("名前", "count"),
平均点=("点数", "mean"),
平均年齢=("年齢", "mean")
)| 人数 | 平均点 | 平均年齢 | |
|---|---|---|---|
| 価格帯 | |||
| 低価格 | 2 | 53.500000 | 19.000000 |
| 中価格 | 3 | 85.666667 | 27.666667 |
| 高価格 | 3 | 65.666667 | 42.000000 |
| かなり高い | 2 | 89.000000 | 61.500000 |
cut()・qcut()・np.where()の使い分け
pd.cut()に近いものとして、pd.qcut()やnp.where()があります。
ここで大切なのは、どれが上位互換という話ではなく、目的によって使い分けることです。
| 方法 | 向いている場面 | 初心者が迷いやすい点 |
|---|---|---|
pd.cut() |
自分で決めた区間で分けたい | binsとlabelsの数、境界値 |
pd.qcut() |
データ数がなるべく均等になるように分けたい | 等間隔ではなく、件数が基準になる |
np.where() |
2択の条件分岐をしたい | 条件が増えると読みにくくなりやすい |
loc |
条件に合う行だけ値を入れたい | 複数条件を書くときに少し複雑になる |
年齢を「10代・20代・30代」のように、自分で決めた範囲で分けたいならcut()が分かりやすいです。
一方で、点数を「人数がなるべく同じになるように3グループへ分けたい」という場合は、qcut()が候補になります。
qcut()は「個数をなるべく均等に分ける」
qcut()は、区間の幅を自分で決めるというより、データの個数がなるべく均等になるように分けます。
ここでは、詳しい使い方には深入りせず、cut()との考え方の違いだけ確認します。
df["点数_qcut_3分割"] = pd.qcut(df["点数"], q=3, labels=["低め", "中くらい", "高め"])
df[["名前", "点数", "点数_qcut_3分割"]]| 名前 | 点数 | 点数_qcut_3分割 | |
|---|---|---|---|
| 0 | 佐藤 | 45 | 低め |
| 1 | 田中 | 62 | 低め |
| 2 | 鈴木 | 78 | 中くらい |
| 3 | 高橋 | 88 | 高め |
| 4 | 伊藤 | 91 | 高め |
| 5 | 渡辺 | 55 | 低め |
| 6 | 山本 | 73 | 中くらい |
| 7 | 中村 | 69 | 低め |
| 8 | 小林 | 82 | 中くらい |
| 9 | 加藤 | 96 | 高め |
qcut()では、点数の区間幅が同じになるとは限りません。
「各グループに入るデータ数をなるべく近づけたい」ときに使います。
一方、この記事の主役であるcut()は、自分で決めた区間で分けたいときに使います。
np.where()は2択なら分かりやすい
たとえば、点数が60点以上なら「合格」、それ以外なら「要復習」とするだけなら、np.where()でも分かりやすく書けます。
df["合否"] = np.where(df["点数"] >= 60, "合格", "要復習")
df[["名前", "点数", "合否"]]| 名前 | 点数 | 合否 | |
|---|---|---|---|
| 0 | 佐藤 | 45 | 要復習 |
| 1 | 田中 | 62 | 合格 |
| 2 | 鈴木 | 78 | 合格 |
| 3 | 高橋 | 88 | 合格 |
| 4 | 伊藤 | 91 | 合格 |
| 5 | 渡辺 | 55 | 要復習 |
| 6 | 山本 | 73 | 合格 |
| 7 | 中村 | 69 | 合格 |
| 8 | 小林 | 82 | 合格 |
| 9 | 加藤 | 96 | 合格 |
ただし、「要復習・標準・高得点」のように複数の数値区間に分けたい場合は、pd.cut()の方が読みやすくなりやすいです。
2択ならnp.where()、複数の数値区間ならpd.cut()と考えると、初心者でも判断しやすくなります。
境界値・NaN・よくあるミス
pd.cut()で特につまずきやすいのは、次の3つです。
- 境界値がどちらの区間に入るか
NaNが出る理由binsとlabelsの数が合わないエラー
順番に確認します。
境界値はどちらの区間に入るのか
pd.cut()は、初期設定では右側の境界を含みます。
つまり、right=Trueが標準です。
たとえば、bins=[0, 19, 29, 39]の場合、基本的には次のように考えます。
| 値 | 入る区間のイメージ |
|---|---|
| 19 | 10代以下 |
| 20 | 20代 |
| 29 | 20代 |
| 30 | 30代 |
実際に確認してみます。
boundary_df = pd.DataFrame({
"年齢": [19, 20, 29, 30, 39]
})
boundary_df["年代"] = pd.cut(
boundary_df["年齢"],
bins=[0, 19, 29, 39],
labels=["10代以下", "20代", "30代"]
)
boundary_df| 年齢 | 年代 | |
|---|---|---|
| 0 | 19 | 10代以下 |
| 1 | 20 | 20代 |
| 2 | 29 | 20代 |
| 3 | 30 | 30代 |
| 4 | 39 | 30代 |
このように、境界値を含む場合は、実際に小さなデータで確認すると安心です。
「20は20代に入るのか」「30は30代に入るのか」と迷ったときは、境界値だけのDataFrameを作って試すのがおすすめです。
right=Falseにすると左側の境界を含める
初期設定のright=Trueでは、右側の境界を含みます。
一方で、right=Falseを指定すると、左側の境界を含む形になります。
たとえば、年齢を次のように考えたい場合です。
| 区間の考え方 | 例 |
|---|---|
| 20以上30未満 | 20代 |
| 30以上40未満 | 30代 |
このように、「20歳以上30歳未満」のような表現にしたいときは、right=Falseが分かりやすいです。
right_false_df = pd.DataFrame({
"年齢": [19, 20, 29, 30, 39, 40]
})
right_false_df["年代_right_false"] = pd.cut(
right_false_df["年齢"],
bins=[0, 20, 30, 40],
labels=["20歳未満", "20代", "30代"],
right=False
)
right_false_df| 年齢 | 年代_right_false | |
|---|---|---|
| 0 | 19 | 20歳未満 |
| 1 | 20 | 20代 |
| 2 | 29 | 20代 |
| 3 | 30 | 30代 |
| 4 | 39 | 30代 |
| 5 | 40 | NaN |
right=Falseにすると、20は「20代」、30は「30代」に入ります。
ただし、最後の区間は「30以上40未満」になるため、40は範囲外となりNaNになります。
このように、right=Falseを使う場合も、最大値が区間から外れていないかを確認することが大切です。
迷ったときは、実データの最小値・最大値と、境界値だけを小さなDataFrameで確認すると安全です。
最小値を含めたいときはinclude_lowest=True
pd.cut()では、最初の区間の左端が含まれないことで迷う場合があります。
たとえば、0点を含めたいときには、include_lowest=Trueを指定すると分かりやすくなります。
score_check = pd.DataFrame({
"点数": [0, 1, 59, 60]
})
score_check["ランク_include_lowestなし"] = pd.cut(
score_check["点数"],
bins=[0, 59, 100],
labels=["要復習", "合格"]
)
score_check["ランク_include_lowestあり"] = pd.cut(
score_check["点数"],
bins=[0, 59, 100],
labels=["要復習", "合格"],
include_lowest=True
)
score_check| 点数 | ランク_include_lowestなし | ランク_include_lowestあり | |
|---|---|---|---|
| 0 | 0 | NaN | 要復習 |
| 1 | 1 | 要復習 | 要復習 |
| 2 | 59 | 要復習 | 要復習 |
| 3 | 60 | 合格 | 合格 |
0点のように、最初の区切り位置そのものを含めたい場合は、include_lowest=Trueを検討します。
特に点数、金額、年齢のように最小値が意味を持つデータでは、最小値がNaNになっていないか確認しましょう。
NaNが出る主な理由
pd.cut()でNaNが出る主な理由は、次のとおりです。
| 原因 | 例 |
|---|---|
binsの最小値より小さい |
binsが0からなのに、値が-1 |
binsの最大値より大きい |
binsが100までなのに、値が120 |
| 元の値が欠損している | 元データがNaN |
| 境界値が含まれていない | 最小値0が区間に入っていない |
right=Falseで最後の境界値が外れる |
40未満の区間に40が入らない |
実際に、binsの範囲外の値がある例を確認します。
nan_df = pd.DataFrame({
"点数": [-5, 0, 50, 85, 120, np.nan]
})
nan_df["ランク"] = pd.cut(
nan_df["点数"],
bins=[0, 59, 79, 100],
labels=["要復習", "標準", "高得点"],
include_lowest=True
)
nan_df| 点数 | ランク | |
|---|---|---|
| 0 | -5.0 | NaN |
| 1 | 0.0 | 要復習 |
| 2 | 50.0 | 要復習 |
| 3 | 85.0 | 高得点 |
| 4 | 120.0 | NaN |
| 5 | NaN | NaN |
この例では、-5や120は指定したbinsの範囲外なのでNaNになります。
元の値がNaNの場合も、結果はNaNになります。
pd.cut()でNaNが出たときは、まず次の点を確認しましょう。
binsの範囲がデータ全体をカバーしているか- 最小値を含める必要があるか
- 元データに欠損値があるか
labelsの数が合わないとエラーになる
labelsの数は、区間の数と同じにする必要があります。
たとえば、bins=[0, 59, 79, 100]なら区間は3つなので、labelsも3つ必要です。
次のコードでは、あえてlabelsの数を間違えて、どのようなエラーになるかを確認します。
エラーでNotebookが止まらないように、tryとexceptで表示だけ行います。
try:
pd.cut(
df["点数"],
bins=[0, 59, 79, 100],
labels=["要復習", "標準"] # 本来は3つ必要
)
except ValueError as e:
print("エラー内容:")
print(e)エラー内容:
Bin labels must be one fewer than the number of bin edgesこのようなエラーが出た場合は、binsから作られる区間の数と、labelsの数が合っているかを確認します。
覚え方は次のとおりです。
labelsの数 = binsの数 - 1
ただし、これは基本的な考え方です。細かいオプションを使う場合は例外もあるため、初心者のうちはまず基本形で覚えるのがおすすめです。
ヒストグラムのbinsとpd.cut()のbinsは同じですか?
ヒストグラムにもbinsという言葉が出てきます。
pd.cut()にもbinsがあります。
どちらも「数値を区間で分ける」という考え方は近いです。
ただし、目的が少し違います。
| 項目 | 目的 |
|---|---|
ヒストグラムのbins |
分布をグラフで見る |
pd.cut()のbins |
区間カテゴリをデータ列として作る |
ヒストグラムは、数値の分布を可視化したいときに使います。
pd.cut()は、区間ごとのカテゴリ列を作り、その後のvalue_counts()やgroupby()につなげたいときに使います。
分布をグラフで確認したい場合は、ヒストグラムや箱ひげ図の記事に進むと理解しやすくなります。
データ分析の流れの中でのpd.cut()の位置づけ
pd.cut()は、単独で覚えるよりも、データ分析の流れの中で考えると使いどころが分かりやすくなります。
| 流れ | 使う操作の例 | 目的 |
|---|---|---|
| データを確認する | head()、info()、describe() |
列・型・欠損値・分布を確認する |
| データを整える | astype()、fillna()、replace() |
型や欠損値、表記ゆれを整える |
| 数値をカテゴリ化する | pd.cut() |
年代・価格帯・ランクを作る |
| 件数を確認する | value_counts() |
カテゴリごとの数を見る |
| 集計する | groupby() |
カテゴリごとに平均や合計を見る |
| 可視化する | ヒストグラム、棒グラフ | 分布やカテゴリ別の違いを見る |
この記事の主役は、3つ目の「数値をカテゴリ化する」部分です。
列を作る方法そのものを詳しく知りたい場合は「新しい列を追加する方法」、カテゴリごとの件数を詳しく知りたい場合は「value_counts()」、カテゴリ別の平均や合計を出したい場合は「groupby×agg」に進むと、学習の流れがつながります。
まとめ:pd.cut()は数値を集計しやすいカテゴリに変える前処理
この記事では、pandas cut()の使い方を、年齢・点数・購入金額の例で解説しました。
大事なポイントを整理します。
pd.cut()は、連続した数値を区間ごとのカテゴリに分ける関数binsは区切り位置、labelsは区間名bins=3のように区間数だけ指定することもできるbins=3では、Pandasがデータの最小値と最大値をもとに、ほぼ同じ幅の区間を自動で作る- 自動分割では、区間表示に端数が出ることがある
retbins=Trueを使うと、自動分割された境界値を確認できるprecisionは、区間表示を見やすくする指定であり、元データを丸める指定ではないlabelsの数は、基本的にbinsの数より1つ少なくする- 年齢を年代、点数をランク、金額を価格帯に分けると集計しやすくなる
cut()で作ったカテゴリは、value_counts()やgroupby()に使えるvalue_counts()の結果を棒グラフにすると、カテゴリごとの違いを視覚的に確認できるqcut()は、データ数がなるべく均等になるように分けたいときの候補- 2択なら
np.where()、複数の数値区間ならpd.cut()が分かりやすい NaNが出たら、binsの範囲、元データの欠損、境界値、rightの指定を確認する- 下限の0点・0円などを区間に含めたい場合は、
include_lowest=Trueを指定すると安全 - 「20以上30未満」のように左側を含めたい場合は、
right=Falseも候補になる
pd.cut()は、派手な関数ではありませんが、数値データを「分析しやすい形」に変えるためにとても便利です。
CSVを読み込んだあと、年齢・点数・売上金額のような数値列を見つけたら、まずは「そのまま集計するのか」「区間に分けた方が見やすいのか」を考えてみてください。
関連記事:次に読むと理解しやすい記事
今回の記事は、前処理と集計をつなぐ内容です。次の順番で読むと、Pandasの流れがつかみやすくなります。
- Pandas DataFrame入門|作り方・基本操作をわかりやすく解説
- Pandas info()とdescribe()の違い|欠損値・型・統計量の見方を例で解説
- pandas astype()の使い方|文字列・数値への型変換とエラー対処を初心者向けに解説
- pandasで新しい列を追加する方法|df[‘列名’]・assign・条件付き列追加を初心者向けに解説
- pandas value_counts()の使い方|件数集計・割合表示・欠損値の数え方を解説
- Pandas groupby×aggの使い方|基本の集計とaggの書き方を例で解説
- Matplotlib ヒストグラム&箱ひげ図 入門|bins設定と外れ値の可視化・分析
特に、pd.cut()で作ったカテゴリ列は、value_counts()やgroupby()と組み合わせると理解が深まります。
pandasのcut()は何をする関数ですか?
pd.cut()は、数値データを指定した区間に分ける関数です。
たとえば、年齢を「10代以下・20代・30代」、点数を「要復習・標準・高得点」、購入金額を「低価格・中価格・高価格」のように分けられます。
binsとlabelsは何を指定するものですか?
binsは区切り位置、labelsは区間につける名前です。
たとえば、bins=[0, 19, 29, 39]なら区間は3つできるため、labelsも3つ指定します。
labelsの数はいくつにすればよいですか?
基本的には、labelsの数はbinsの数より1つ少なくします。binsが4個なら区間は3つなので、labelsは3個です。
bins=3とは何ですか?
bins=3は、数値列を3つの区間に分ける指定です。
Pandasがデータの最小値と最大値をもとに、ほぼ同じ幅の区間を自動で作ります。
大まかに分けて確認したいときは便利ですが、年代や点数ランクのように意味のある区切りを使いたい場合は、bins=[0, 59, 79, 100]のように自分で指定する方が分かりやすいです。
また、自動分割では区間表示に端数が出ることがあります。気になる場合はretbins=Trueで境界値を確認します。
include_lowest=Trueはいつ使いますか?
include_lowest=Trueは、最初の区間の下限も含めたいときに使います。
たとえば、bins=[0, 59, 79, 100]で「0〜59点」を要復習にしたい場合、0点も含めるために指定しておくと安全です。
pd.cut()でNaNが出るのはなぜですか?
主な理由は、値がbinsの範囲外にあることです。
たとえば、binsを0〜100で指定しているのに、値が120ならNaNになります。元データが欠損している場合もNaNになります。
境界値の20や30はどちらの区間に入りますか?
初期設定では、pd.cut()は右側の境界を含みます。
たとえば、bins=[0, 19, 29, 39]なら、20は20代の区間、30は30代の区間に入ります。迷ったときは、境界値だけの小さなDataFrameで確認するのがおすすめです
right=Falseはいつ使いますか?
right=Falseは、「20以上30未満」のように左側の境界を含めたいときに使います。
初期設定では右側の境界を含むため、境界値がどちらの区間に入るかで迷ったときは、right=Trueとright=Falseの結果を小さなデータで確認すると安心です。
retbins=Trueはいつ使いますか?
retbins=Trueは、bins=3のように区間数だけを指定したときに、Pandasが実際にどの境界値で区切ったのか確認したい場合に使います。
初心者のうちは必須ではありませんが、自動分割の結果を確認したいときに便利です。
precisionは何を指定するものですか?
precisionは、区間ラベルに表示される境界値の桁数を調整する指定です。bins=3のような自動分割では区間表示が小数になることがあるため、見た目を少し整えたいときに使えます。
ただし、precisionは元データを丸める指定ではありません。
分析上の区切りを明確にしたい場合は、precisionで見た目を整えるより、自分でbinsを指定する方が分かりやすいです。
cut()とqcut()の違いは何ですか?
cut()は、自分で決めた区間で分けたいときに使います。qcut()は、データの個数がなるべく均等になるように分けたいときに使います。年代や価格帯のように範囲を自分で決めたいなら、まずはcut()が分かりやすいです。
np.where()とcut()はどう使い分けますか?
2択の条件分岐ならnp.where()が分かりやすいです。
たとえば、60点以上なら「合格」、それ以外なら「要復習」のような場合です。一方で、「要復習・標準・高得点」のように複数の数値区間に分けたい場合は、pd.cut()の方が読みやすくなります。
cut()で作ったカテゴリをvalue_counts()やgroupby()で使えますか?
はい、使えます。pd.cut()で年代や価格帯の列を作り、その列に対してvalue_counts()を使うとカテゴリごとの件数を確認できます。さらに、groupby()を使うと、年代ごとの平均点や価格帯ごとの平均購入金額のような集計もできます。
cut()で作ったカテゴリをグラフで確認できますか?
はい、確認できます。pd.cut()で作ったカテゴリ列に対してvalue_counts()を使い、その結果を棒グラフにすると、カテゴリごとの件数を視覚的に確認できます。
ただし、pd.cut()の記事ではグラフを増やしすぎる必要はありません。
まずは「カテゴリ列を作る」「件数を数える」「必要なら棒グラフで確認する」という流れで理解すると十分です。
ヒストグラムのbinsとpd.cut()のbinsは同じですか?
考え方は近いですが、目的が違います。
ヒストグラムのbinsは分布をグラフで見るためのものです。pd.cut()のbinsは、区間カテゴリを新しい列として作るためのものです。
コメント