CSVを読み込んだあと、DataFrameの中に「注文ID」「日付」「商品コード」のような列があると、次のように迷うことがあります。
- この列は、普通の列のまま使えばよいのか
- 左端のインデックスにしたほうがよいのか
set_index()を使うと、元の列が消えるのかreset_index()とは何が違うのか- 元の列を残したい場合はどう書けばよいのか
- CSVを読み込む時点でインデックスを指定できるのか
結論から言うと、set_index() は DataFrameの列をインデックスにして、行を見つけやすくするためのメソッドです。
たとえば、注文IDをインデックスにすると、注文IDを基準に1行を取り出しやすくなります。また、日付列をインデックスにすれば、日付順に並べ替える操作も考えやすくなります。
また、CSVを読み込む時点で最初からインデックスを指定したい場合は、pd.read_csv(..., index_col="列名") を使えます。すでに読み込んだDataFrameの列をあとからインデックスにする場合は set_index()、読み込み時に決めたい場合は index_col と考えると分かりやすいです。
この記事では、pandas set_index() の基本から、drop=False で元の列を残す方法、reset_index() との違い、CSV読み込み時の index_col、loc や sort_index() とのつながり、反映されない原因までを初心者向けに整理します。
読み終えるころには、「読み込み後に基準列を決めるなら set_index()」「CSV読み込み時に決めるなら index_col」「元に戻したいときは reset_index()」「元の列も残したいときは drop=False」という使い分けができるようになります。
この記事でわかること
set_index()で何ができるか- 「列をインデックスにする」とはどういう意味か
set_index()の基本的な使い方set_index()の処理前→処理後の変化drop=Falseで元の列を残す方法set_index()とreset_index()の違い- CSV読み込み時に
index_colでインデックスを指定する方法 set_index()後にlocやsort_index()が使いやすくなる理由set_index()が反映されない原因- 重複した値をインデックスにするときの注意点
- 複数列を指定すると
MultiIndexになること - 初心者がまず覚えるべき使い分け
このページは、Pandas DataFrame入門 から続く前処理系の記事です。
DataFrameの基本を確認したあとに、「列とインデックスの関係」を理解する記事として読むと流れがつかみやすくなります。
set_index()とは?列をインデックスにするとはどういう意味か
set_index() は、DataFrameの中にある列を インデックスとして使う ためのメソッドです。
インデックスとは、DataFrameの左端に表示される行ラベルのことです。通常は 0, 1, 2, 3... のような番号が自動で付きます。
しかし、実際のデータでは、次のような列を行の目印として使いたいことがあります。
- 注文ID
- 顧客ID
- 商品コード
- 日付
- 店舗名
- 地域
このような列をインデックスにすると、「どの行を見たいのか」をラベルで指定しやすくなります。
最初は、次のように覚えると十分です。
set_index()は、行を見つける基準にしたい列を、DataFrameの左端のインデックスにする処理です。
まずは結論:どの処理を使えばよいか
set_index() の周辺には、似た名前の処理がいくつかあります。最初に、使い分けを表で整理しておきます。
| やりたいこと | 使う処理 | 初心者向けの覚え方 |
|---|---|---|
| 読み込み後のDataFrameで列をインデックスにしたい | set_index() |
あとから基準にしたい列を左端に置く |
| インデックスにしつつ元の列も残したい | set_index(..., drop=False) |
左端にも置き、列としても残す |
| CSV読み込み時に最初からインデックスを指定したい | pd.read_csv(..., index_col="列名") |
読み込む時点で基準列を決める |
| インデックスを列に戻したい | reset_index() |
インデックスを普通の列へ戻す |
| インデックスを0から振り直したい | reset_index(drop=True) |
今のインデックスを捨てて番号を振り直す |
| インデックス名を付けたい | rename_axis() |
左端の見出し名だけ付ける |
| インデックス順に並べたい | sort_index() |
インデックスの値で並び替える |
| 複数列をインデックスにしたい | set_index(["列1", "列2"]) |
複数の基準で階層的に見る |
この記事の中心は set_index() です。drop=False、index_col、reset_index()、rename_axis()、sort_index()、複数列指定は、違いが分かる範囲で必要なところだけ扱います。
サンプルデータでset_index()の基本を確認する
ここからは、実際のDataFrameを使って set_index() の基本を確認します。
まずは注文IDをインデックスにして、処理前と処理後で何が変わるのかを見ていきます。
サンプルデータを作成する
まずは、Google Colabでそのまま実行できる小さな売上データを作ります。
今回のデータには、次の列があります。
- 注文ID
- 日付
- 商品
- 地域
- 売上
set_index() の動きを分かりやすく見るために、注文IDを行の目印として使っていきます。
import pandas as pd
df = pd.DataFrame({
"注文ID": [1001, 1002, 1003, 1004, 1005, 1006],
"日付": ["2026-04-01", "2026-04-03", "2026-04-02", "2026-04-05", "2026-04-04", "2026-04-06"],
"商品": ["りんご", "みかん", "りんご", "バナナ", "みかん", "りんご"],
"地域": ["東京", "大阪", "東京", "福岡", "大阪", "東京"],
"売上": [1200, 980, 1500, 800, 1100, 1300]
})
df| 注文ID | 日付 | 商品 | 地域 | 売上 | |
|---|---|---|---|---|---|
| 0 | 1001 | 2026-04-01 | りんご | 東京 | 1200 |
| 1 | 1002 | 2026-04-03 | みかん | 大阪 | 980 |
| 2 | 1003 | 2026-04-02 | りんご | 東京 | 1500 |
| 3 | 1004 | 2026-04-05 | バナナ | 福岡 | 800 |
| 4 | 1005 | 2026-04-04 | みかん | 大阪 | 1100 |
| 5 | 1006 | 2026-04-06 | りんご | 東京 | 1300 |
この時点では、左端に 0, 1, 2, 3, 4, 5 という番号が表示されます。これはpandasが自動で付けたインデックスです。
一方で、データの中には 注文ID という列があります。この 注文ID は、1件ごとの注文を識別するための列なので、行を見つける基準として使いやすい列です。
set_index()の基本形
set_index() の基本形は、次のように書きます。
df_indexed = df.set_index("列名")
たとえば、注文ID をインデックスにする場合は、次のように書きます。
df_indexed = df.set_index("注文ID")
df_indexed| 日付 | 商品 | 地域 | 売上 | |
|---|---|---|---|---|
| 1001 | 2026-04-01 | りんご | 東京 | 1200 |
| 1002 | 2026-04-03 | みかん | 大阪 | 980 |
| 1003 | 2026-04-02 | りんご | 東京 | 1500 |
| 1004 | 2026-04-05 | バナナ | 福岡 | 800 |
| 1005 | 2026-04-04 | みかん | 大阪 | 1100 |
| 1006 | 2026-04-06 | りんご | 東京 | 1300 |
実行すると、注文ID がDataFrameの左端に移動します。
ここで大事なのは、注文ID の値が削除されたわけではないという点です。注文ID は、普通の列ではなく、行ラベルとして使われる位置に移動したと考えると分かりやすいです。
つまり、set_index() は「データを消す処理」ではなく、行を見つける基準を変える処理です。
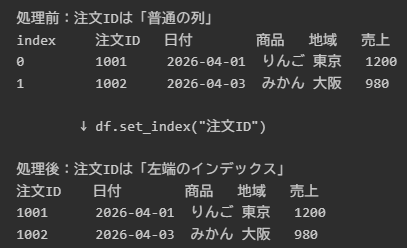
処理前→処理後で変化を見る
set_index() は、文章だけだと少し分かりにくいので、処理前と処理後の違いを表で見てみます。
| 状態 | 左端のインデックス | 注文ID列の見え方 |
|---|---|---|
| 処理前 | 0, 1, 2, 3... |
普通の列として表示される |
set_index("注文ID") 後 |
1001, 1002, 1003... |
インデックスになり、通常の列からは外れて見える |
set_index("注文ID", drop=False) 後 |
1001, 1002, 1003... |
インデックスにもなり、普通の列としても残る |
イメージとしては、次のような変化です。
処理前:注文IDは「普通の列」
index 注文ID 日付 商品 地域 売上
0 1001 2026-04-01 りんご 東京 1200
1 1002 2026-04-03 みかん 大阪 980
↓ df.set_index("注文ID")
処理後:注文IDは「左端のインデックス」
注文ID 日付 商品 地域 売上
1001 2026-04-01 りんご 東京 1200
1002 2026-04-03 みかん 大阪 980
このように、注文ID が左端の行ラベルになります。
削除されたのではなく、普通の列からインデックスの位置へ移動したと考えると理解しやすいです。
元の列が消えたように見える理由
set_index("注文ID") を使うと、注文ID が通常の列一覧から外れます。そのため、初心者のうちは「注文ID列が消えた」と感じることがあります。
実際に、列名の一覧を確認してみます。
print("元のdfの列名:")
print(df.columns.tolist())
print("\nset_index後の列名:")
print(df_indexed.columns.tolist())
print("\nset_index後のインデックス名:")
print(df_indexed.index.name)元のdfの列名: ['注文ID', '日付', '商品', '地域', '売上'] set_index後の列名: ['日付', '商品', '地域', '売上'] set_index後のインデックス名: 注文ID
set_index() 後の列名一覧には、注文ID がありません。ただし、注文ID はインデックス名として残っています。
この違いが、set_index() で最初につまずきやすいポイントです。
- 普通の列として使う場合 →
df["注文ID"] - インデックスとして使う場合 →
df.indexやlocで扱う
このあと、元の列も残す drop=False を確認します。
drop=Falseで元の列も残す
set_index() では、通常、指定した列がインデックスに移動し、通常の列からは外れます。
ただし、元の列としても残したい場合は、drop=False を使います。
df_indexed_keep = df.set_index("注文ID", drop=False)
df_indexed_keep| 注文ID | 日付 | 商品 | 地域 | 売上 | |
|---|---|---|---|---|---|
| 1001 | 1001 | 2026-04-01 | りんご | 東京 | 1200 |
| 1002 | 1002 | 2026-04-03 | みかん | 大阪 | 980 |
| 1003 | 1003 | 2026-04-02 | りんご | 東京 | 1500 |
| 1004 | 1004 | 2026-04-05 | バナナ | 福岡 | 800 |
| 1005 | 1005 | 2026-04-04 | みかん | 大阪 | 1100 |
| 1006 | 1006 | 2026-04-06 | りんご | 東京 | 1300 |
drop=False を使うと、注文ID がインデックスにもなり、列としても残ります。
違いを表にすると、次のようになります。
| 書き方 | インデックス | 注文ID列 | 使いどころ |
|---|---|---|---|
df.set_index("注文ID") |
注文IDになる | 通常の列からは外れる | 注文IDを行ラベルとして使いたいとき |
df.set_index("注文ID", drop=False) |
注文IDになる | 通常の列としても残る | インデックスにもしたいが、列としても参照したいとき |
初心者のうちは、まず通常の set_index("注文ID") を覚えれば十分です。
ただし、後で df["注文ID"] のように列としても使いたい場合は、drop=False が役立ちます。
set_index()とreset_index()の違い
set_index() とよく一緒に出てくるのが、reset_index() です。
名前は似ていますが、向きが逆です。
| メソッド | 何をするか | よく使う場面 |
|---|---|---|
set_index() |
列をインデックスにする | ID列・日付列などを基準にしたいとき |
set_index(..., drop=False) |
列をインデックスにしつつ、元の列も残す | インデックスにも列にも同じ値を残したいとき |
reset_index() |
インデックスを列に戻す | インデックスを普通の列に戻したいとき |
reset_index(drop=True) |
今のインデックスを捨てて0から振り直す | 抽出後や並び替え後に見た目を整えたいとき |
覚え方は、次の通りです。
set_index():基準にしたい列をセットするreset_index():インデックスを戻す、または振り直すdrop=False:インデックスにしても、元の列を残す
実際に、set_index() したDataFrameを reset_index() で戻してみます。
df_restored = df_indexed.reset_index()
df_restored| 注文ID | 日付 | 商品 | 地域 | 売上 | |
|---|---|---|---|---|---|
| 0 | 1001 | 2026-04-01 | りんご | 東京 | 1200 |
| 1 | 1002 | 2026-04-03 | みかん | 大阪 | 980 |
| 2 | 1003 | 2026-04-02 | りんご | 東京 | 1500 |
| 3 | 1004 | 2026-04-05 | バナナ | 福岡 | 800 |
| 4 | 1005 | 2026-04-04 | みかん | 大阪 | 1100 |
| 5 | 1006 | 2026-04-06 | りんご | 東京 | 1300 |
reset_index() を使うと、インデックスになっていた 注文ID が通常の列に戻ります。
つまり、次の流れで考えると分かりやすいです。
普通のDataFrame
↓ set_index("注文ID")
注文IDをインデックスにしたDataFrame
↓ reset_index()
注文IDを普通の列に戻したDataFrame
なお、抽出後や削除後に 0, 1, 2... と番号を振り直したい場合は、reset_index(drop=True) を使います。この使い方は、インデックスを整える目的なので、set_index() の完全な逆とは少し意味が違います。
CSV読み込み時にインデックスを指定する方法|index_col
ここまで見てきた set_index() は、すでに読み込んだDataFrameの列をあとからインデックスにする方法です。
一方で、CSVを読み込む時点で「この列を最初からインデックスにしたい」と決まっている場合は、pd.read_csv() の index_col を使えます。
使い分けは、次のように考えると分かりやすいです。
| 場面 | 使う方法 |
|---|---|
| DataFrameを読み込んだあとに、列をインデックスへ変更したい | df.set_index("注文ID") |
| CSVを読み込む時点で、最初からインデックスを指定したい | pd.read_csv(..., index_col="注文ID") |
ここでは、Google Colabでもそのまま試せるように、文字列のCSVデータを使って確認します。実際のCSVファイルを読む場合は、StringIO は不要で、pd.read_csv("sample.csv", index_col="注文ID") のように書きます。
from io import StringIO
csv_text = """注文ID,日付,商品,地域,売上
1001,2026-04-01,りんご,東京,1200
1002,2026-04-03,みかん,大阪,980
1003,2026-04-02,りんご,東京,1500
"""
df_from_csv = pd.read_csv(StringIO(csv_text), index_col="注文ID")
df_from_csv| 日付 | 商品 | 地域 | 売上 | |
|---|---|---|---|---|
| 1001 | 2026-04-01 | りんご | 東京 | 1200 |
| 1002 | 2026-04-03 | みかん | 大阪 | 980 |
| 1003 | 2026-04-02 | りんご | 東京 | 1500 |
index_col="注文ID" を指定したため、読み込んだ時点で 注文ID がインデックスになっています。
つまり、次の2つは目的が似ています。
df = pd.read_csv("sample.csv")
df = df.set_index("注文ID")
df = pd.read_csv("sample.csv", index_col="注文ID")
ただし、初心者のうちは、まず普通にCSVを読み込んで head() や columns で列名を確認してから、必要に応じて set_index() する流れがおすすめです。列名の確認前に index_col を指定すると、列名のスペル違いや余計な空白に気づきにくいことがあるためです。
set_index()後に便利になる操作
set_index() は、インデックスを変えるだけで終わりではありません。
インデックスを設定すると、loc で行を取り出したり、sort_index() で並べ替えたりしやすくなります。
set_index()後にlocで行を取り出す
set_index() を使うメリットの1つは、loc でラベル指定しやすくなることです。
たとえば、注文ID をインデックスにしておくと、注文IDを指定して1行を取り出せます。
df_indexed = df.set_index("注文ID")
df_indexed.loc[1003]| 1003 | |
|---|---|
| 日付 | 2026-04-02 |
| 商品 | りんご |
| 地域 | 東京 |
| 売上 | 1500 |
dtype: object
このコードでは、インデックスが 1003 の行を取り出しています。
普通の列のままでも条件抽出はできますが、IDを行ラベルとして使いたい場合は、set_index() しておくと loc で見つけやすくなります。
df_indexed.loc[1003]
このように書けるため、「注文IDを基準に1行を見たい」という場面で分かりやすくなります。
loc の詳しい使い方は、pandas locの使い方 や Pandas locとilocの違い で整理すると理解しやすいです。
日付列をインデックスにしてsort_index()で並べる
set_index() は、注文IDだけでなく、日付列にも使えます。
日付をインデックスにすると、日付を基準にデータを見たいときに便利です。ただし、ここでは時系列分析の深い話には進まず、まずは「日付列をインデックスにする」と「インデックス順に並べる」流れだけ確認します。
df_date = df.copy()
df_date["日付"] = pd.to_datetime(df_date["日付"])
df_date_indexed = df_date.set_index("日付")
df_date_indexed| 注文ID | 商品 | 地域 | 売上 | |
|---|---|---|---|---|
| 2026-04-01 | 1001 | りんご | 東京 | 1200 |
| 2026-04-03 | 1002 | みかん | 大阪 | 980 |
| 2026-04-02 | 1003 | りんご | 東京 | 1500 |
| 2026-04-05 | 1004 | バナナ | 福岡 | 800 |
| 2026-04-04 | 1005 | みかん | 大阪 | 1100 |
| 2026-04-06 | 1006 | りんご | 東京 | 1300 |
この時点では、日付列がインデックスになりました。
ただし、元データの日付は完全な昇順ではありません。インデックスの日付順に並べたい場合は、sort_index() を使います。
df_date_sorted = df_date_indexed.sort_index()
df_date_sorted| 注文ID | 商品 | 地域 | 売上 | |
|---|---|---|---|---|
| 2026-04-01 | 1001 | りんご | 東京 | 1200 |
| 2026-04-02 | 1003 | りんご | 東京 | 1500 |
| 2026-04-03 | 1002 | みかん | 大阪 | 980 |
| 2026-04-04 | 1005 | みかん | 大阪 | 1100 |
| 2026-04-05 | 1004 | バナナ | 福岡 | 800 |
| 2026-04-06 | 1006 | りんご | 東京 | 1300 |
ここで大事なのは、set_index() は並び替えの処理ではないという点です。
- 日付列をインデックスにする →
set_index("日付") - インデックスの日付順に並べる →
sort_index()
このように、役割を分けて考えると混乱しにくくなります。
日付の型変換を詳しく知りたい場合は、pandas to_datetime()の使い方 を読むとつながりが分かりやすくなります。
ここまで分かったら知っておきたい補足
ここでは、複数列を指定した場合や、重複した値をインデックスにした場合を軽く確認します。
どちらも便利な考え方ですが、初心者はまず1列の set_index() を理解してからで大丈夫です。
複数列を指定するとMultiIndexになる
set_index() では、1列だけでなく、複数列をインデックスにすることもできます。
たとえば、地域 と 商品 を指定すると、地域と商品を組み合わせたインデックスになります。
df_multi = df.set_index(["地域", "商品"])
df_multi| 注文ID | 日付 | 売上 | ||
|---|---|---|---|---|
| 地域 | 商品 | |||
| 東京 | りんご | 1001 | 2026-04-01 | 1200 |
| 大阪 | みかん | 1002 | 2026-04-03 | 980 |
| 東京 | りんご | 1003 | 2026-04-02 | 1500 |
| 福岡 | バナナ | 1004 | 2026-04-05 | 800 |
| 大阪 | みかん | 1005 | 2026-04-04 | 1100 |
| 東京 | りんご | 1006 | 2026-04-06 | 1300 |
このように、複数の列をインデックスにすると、MultiIndex と呼ばれる階層型インデックスになります。
たとえば、地域 と 商品 の組み合わせを基準にすると、「東京のりんご」「大阪のみかん」のように、複数の条件を組み合わせてデータを見やすくなります。
ただし、初心者のうちは、まず1列の set_index() を理解することが大切です。MultiIndex は便利ですが、選択や集計の考え方が少し難しくなります。
この記事では入口だけに留めます。詳しく学びたい場合は、pandas MultiIndex完全ガイド で確認してください。
複数列をインデックスにすると、次のように組み合わせで行を取り出せます。ここでは発展的な例として、東京 かつ りんご の行を取り出してみます。
df_multi.loc[("東京", "りんご")]/tmp/ipykernel_28653/2274555446.py:1: PerformanceWarning: indexing past lexsort depth may impact performance.
df_multi.loc[("東京", "りんご")]
| 注文ID | 日付 | 売上 | ||
|---|---|---|---|---|
| 地域 | 商品 | |||
| 東京 | りんご | 1001 | 2026-04-01 | 1200 |
| りんご | 1003 | 2026-04-02 | 1500 | |
| りんご | 1006 | 2026-04-06 | 1300 |
このように、複数の基準を組み合わせて行を見たい場合に、複数列の set_index() が役立ちます。
ただし、通常の初心者向けの前処理では、いきなりMultiIndexを多用する必要はありません。まずは、注文IDや日付のような1列をインデックスにする使い方から慣れていきましょう。
set_index()でよくあるつまずき
set_index() でよくあるつまずきは、反映されないこと、列名の指定ミス、似た操作との混同です。
どれも原因を知っておけば、すぐに確認できます。
set_index()が反映されない原因
set_index() でよくあるつまずきが、「実行したのに元のDataFrameが変わらない」というものです。
これは、set_index() が基本的に 変更後の新しいDataFrameを返す メソッドだからです。
次の例を見てください。
df_temp = df.copy()
df_temp.set_index("注文ID")
print("set_index()を実行したあとのdf_temp:")
df_tempset_index()を実行したあとのdf_temp:
| 注文ID | 日付 | 商品 | 地域 | 売上 | |
|---|---|---|---|---|---|
| 0 | 1001 | 2026-04-01 | りんご | 東京 | 1200 |
| 1 | 1002 | 2026-04-03 | みかん | 大阪 | 980 |
| 2 | 1003 | 2026-04-02 | りんご | 東京 | 1500 |
| 3 | 1004 | 2026-04-05 | バナナ | 福岡 | 800 |
| 4 | 1005 | 2026-04-04 | みかん | 大阪 | 1100 |
| 5 | 1006 | 2026-04-06 | りんご | 東京 | 1300 |
上のコードでは、df_temp.set_index("注文ID") を実行していますが、その結果を変数に代入していません。
そのため、df_temp 自体は元のままです。
正しく反映したい場合は、次のように代入します。
df_temp = df.copy()
df_temp = df_temp.set_index("注文ID")
df_temp| 日付 | 商品 | 地域 | 売上 | |
|---|---|---|---|---|
| 1001 | 2026-04-01 | りんご | 東京 | 1200 |
| 1002 | 2026-04-03 | みかん | 大阪 | 980 |
| 1003 | 2026-04-02 | りんご | 東京 | 1500 |
| 1004 | 2026-04-05 | バナナ | 福岡 | 800 |
| 1005 | 2026-04-04 | みかん | 大阪 | 1100 |
| 1006 | 2026-04-06 | りんご | 東京 | 1300 |
初心者のうちは、次の形で覚えるのがおすすめです。
df = df.set_index("注文ID")
inplace=True を使う書き方もありますが、最初は多用しなくて大丈夫です。
df.set_index("注文ID", inplace=True)
inplace=True は元のDataFrameを直接変更する書き方です。メモリを意識する場面などで使われることはありますが、学習中は「どの時点でDataFrameが変わったのか」を追いにくくなることがあります。
そのため、この記事では基本的に 代入する書き方 を使います。
df = df.set_index("注文ID")
存在しない列名を指定するとKeyErrorになる
set_index() では、存在しない列名を指定すると KeyError になります。
たとえば、実際の列名は 注文ID なのに、誤って 注文番号 と書くとエラーになります。
CSVを読み込んだ直後は、列名に空白が入っていたり、思っていた名前と少し違っていたりすることがあるため、まず df.columns.tolist() で列名を確認すると安全です。
print(df.columns.tolist())
try:
df.set_index("注文番号")
except KeyError as e:
print("KeyError:", e)['注文ID', '日付', '商品', '地域', '売上'] KeyError: "None of ['注文番号'] are in the columns"
似た操作:df.indexやrename_axis()との違い
set_index() に近い操作として、df.index への直接代入や rename_axis() があります。
ただし、それぞれ役割が違います。
| 処理 | 何をするか | 初心者向けの使いどころ |
|---|---|---|
set_index("列名") |
既存の列をインデックスにする | 注文IDや日付列を基準にしたいとき |
df.index = [...] |
インデックスの値を直接入れ替える | すでに用意したラベルを直接設定したいとき |
rename_axis("名前") |
インデックスの見出し名を付ける | インデックス名だけ整えたいとき |
初心者がまず覚えるべきなのは、set_index() です。なぜなら、DataFrameの中にある列を使って自然にインデックスを作れるからです。
df_named_index = df.set_index("注文ID").rename_axis("注文番号")
df_named_index| 日付 | 商品 | 地域 | 売上 | |
|---|---|---|---|---|
| 1001 | 2026-04-01 | りんご | 東京 | 1200 |
| 1002 | 2026-04-03 | みかん | 大阪 | 980 |
| 1003 | 2026-04-02 | りんご | 東京 | 1500 |
| 1004 | 2026-04-05 | バナナ | 福岡 | 800 |
| 1005 | 2026-04-04 | みかん | 大阪 | 1100 |
| 1006 | 2026-04-06 | りんご | 東京 | 1300 |
上の例では、注文ID をインデックスにしたあと、rename_axis("注文番号") でインデックスの見出し名を整えています。
ここで注意したいのは、rename_axis() は列をインデックスにする処理ではないという点です。インデックスの名前を付けるだけなので、set_index() とは役割が違います。
重複した値をインデックスにしてもよいのか
インデックスは、必ず一意でなければならないわけではありません。つまり、同じ値が複数行にあってもインデックスにできます。
たとえば、地域 をインデックスにすると、東京や大阪が複数回出てきます。
df_region_indexed = df.set_index("地域")
df_region_indexed| 注文ID | 日付 | 商品 | 売上 | |
|---|---|---|---|---|
| 東京 | 1001 | 2026-04-01 | りんご | 1200 |
| 大阪 | 1002 | 2026-04-03 | みかん | 980 |
| 東京 | 1003 | 2026-04-02 | りんご | 1500 |
| 福岡 | 1004 | 2026-04-05 | バナナ | 800 |
| 大阪 | 1005 | 2026-04-04 | みかん | 1100 |
| 東京 | 1006 | 2026-04-06 | りんご | 1300 |
このように、同じインデックスラベルが複数行にあってもDataFrameとしては成立します。
ただし、初心者のうちは、まず 注文ID のように1行を識別しやすい列で練習するのがおすすめです。重複したインデックスでは、loc["東京"] のように指定したときに複数行が返るため、最初は少し混乱しやすいからです。
df_region_indexed.loc["東京"]| 注文ID | 日付 | 商品 | 売上 | |
|---|---|---|---|---|
| 東京 | 1001 | 2026-04-01 | りんご | 1200 |
| 東京 | 1003 | 2026-04-02 | りんご | 1500 |
| 東京 | 1006 | 2026-04-06 | りんご | 1300 |
この例では、インデックスが 東京 の行が複数あるため、複数行が返ります。
これはエラーではありません。ただし、最初に学ぶ段階では、注文IDのような一意の列から始めるほうが理解しやすいです。
補足:重複をエラーとして確認したい場合は verify_integrity=True
重複した値をインデックスにできるとはいえ、注文IDのように「本来は1行に1つだけ」の列では、重複に気づきたい場面もあります。
その場合は、verify_integrity=True を指定すると、重複があるときにエラーとして確認できます。少し発展的なので、最初は読み飛ばしても大丈夫です。
df_dup = pd.DataFrame({
"注文ID": [1001, 1001, 1002],
"商品": ["りんご", "みかん", "バナナ"],
"売上": [1200, 980, 800]
})
try:
df_dup.set_index("注文ID", verify_integrity=True)
except ValueError as e:
print("ValueError:", e)ValueError: Index has duplicate keys: Index([1001], dtype='int64', name='注文ID')
verify_integrity=True は、インデックスにしようとしている値が重複していないか確認したいときに使えます。
ただし、通常の学習段階では必須ではありません。まずは、set_index()、drop=False、reset_index() の3つを優先して覚えるとよいです。
前処理の流れの中でset_index()を考える
set_index() は単体で覚えるより、CSV読み込み後の前処理の中で考えると役割が分かりやすくなります。
前処理の流れの中でset_index()をどこで使うか
set_index() は、単独で覚えるよりも、前処理の流れの中で考えると役割が分かりやすくなります。
たとえば、CSVを読み込んだあと、次のような流れで使うことがあります。
CSVを読み込む
↓
head() や info() でデータを確認する
↓
rename() で列名を分かりやすく整える
↓
astype() や to_datetime() で型を整える
↓
必要に応じて set_index() で基準列を決める
↓
loc や sort_index() で扱いやすくする
↓
groupby() や可視化へ進む
set_index() は、前処理の中で 行を識別する基準を決める処理 と考えると自然です。
なお、CSVを読み込む時点でインデックスにしたい列が明確に決まっている場合は、pd.read_csv(..., index_col="列名") も使えます。ただし、初心者のうちは、まず普通に読み込んで列名やデータ型を確認してから set_index() する流れのほうが安全です。
たとえば、日付を基準に見るなら日付列をインデックスにする。注文IDを基準に1件ずつ確認したいなら注文IDをインデックスにする。このように、分析で何を基準に見たいかによって使うかどうかを判断します。
set_index()を使わなくてもよい場面
set_index() は便利ですが、いつも使う必要はありません。
次のような場合は、普通の列のままでも十分です。
- その列を行の基準として使わない
- 条件抽出だけできればよい
- CSVとして保存するときに、普通の列として残しておきたい
- まだDataFrameの構造に慣れていない
たとえば、地域 == "東京" のような条件抽出をしたいだけなら、無理に 地域 をインデックスにしなくても大丈夫です。
df[df["地域"] == "東京"]
まずは、行を見つける基準にしたい列だけ set_index() を検討する くらいで十分です。
まとめ
この記事では、pandas set_index() の使い方を初心者向けに整理しました。
大事なポイントは、次の通りです。
set_index()は、DataFrameの列をインデックスにするメソッド- 注文ID・日付・商品コードなど、行を見つける基準にしたい列に使う
- 通常の
set_index()では、指定した列が通常の列から外れて見える - 元の列も残したい場合は
drop=Falseを使う - CSV読み込み時に最初からインデックスを指定したい場合は
index_colを使う - インデックスを列に戻したい場合は
reset_index()を使う set_index()後は、locでラベル指定しやすくなる- インデックス順に並べたい場合は
sort_index()を使う - 複数列を指定すると
MultiIndexになる - 重複を確認したい場合は
verify_integrity=Trueも使える - 反映されないときは、
df = df.set_index(...)のように代入しているか確認する
最初は、次の4つだけ覚えれば十分です。
df = df.set_index("注文ID")
df = df.set_index("注文ID", drop=False)
df = pd.read_csv("sample.csv", index_col="注文ID")
df = df.reset_index()
set_index() は、読み込み後のDataFrameで列をインデックスにして基準を決める処理。drop=False は、元の列も残す指定。index_col は、CSV読み込み時に最初からインデックスを指定する方法。reset_index() は、インデックスを戻す、または振り直す処理です。
この関係を理解すると、DataFrameの前処理や抽出がかなり分かりやすくなります。
次に読みたい関連記事
set_index() を理解したら、次の記事とつなげて読むと、Pandasの前処理から抽出・集計までの流れが見えやすくなります。
まず確認したい記事
Pandas DataFrame入門|作り方・基本操作をわかりやすく解説
DataFrameの列・行・インデックスの基本を確認したい方におすすめです。Google Colab CSV 読み込み&保存入門
CSVを読み込んでから前処理する流れや、読み込み時の指定を確認できます。
次に読みたい記事
pandas reset_index()の使い方
インデックスを列に戻す方法や、0から振り直す方法を確認できます。pandas locの使い方
インデックスや列名を使ってデータを抽出する方法を学べます。pandas 並び替え(sort)入門
sort_values()とsort_index()の違いを確認できます。
発展として読みたい記事
pandas MultiIndex完全ガイド
複数列をインデックスにする発展的な使い方を学びたい方におすすめです。Pandas groupby×aggの使い方
前処理したデータを集計する流れにつなげられます。
set_index()を使うと元の列は消えますか?
完全に消えるわけではありません。通常は、指定した列がインデックスに移動し、普通の列一覧からは外れて見えます。元の列としても残したい場合は、drop=False を指定します。
set_index()とreset_index()の違いは何ですか?
set_index() は、DataFrameの列をインデックスにする処理です。一方、reset_index() は、インデックスを普通の列に戻したり、0から番号を振り直したりする処理です。
CSVを読み込むときに最初からインデックスを指定できますか?
できます。pd.read_csv("sample.csv", index_col="注文ID") のように index_col を指定すると、CSVを読み込む時点で特定の列をインデックスにできます。
set_index()が反映されないのはなぜですか?
set_index() は、元のDataFrameを直接変更するのではなく、新しいDataFrameを返します。そのため、結果を残したい場合は、df = df.set_index("注文ID") のように変数へ代入します。
コメント