条件抽出・行削除・並び替えをしたあとに、DataFrameの左端の番号が 0, 1, 2... ではなく、0, 3, 5... のように飛び飛びになることがあります。
「pandasでインデックスを0から振り直したい」「indexを連番に戻したい」ときに使うのが、reset_index() です。
この左端の番号は、Pandasの index(インデックス) です。
結論からいうと、抽出・削除・並び替えなどで崩れたインデックスを0からの連番に戻したいときは、reset_index() を使います。
特に、元のインデックスが不要な場合は、次の書き方を使うことが多いです。
df = df.reset_index(drop=True)
この記事では、reset_index() の基本、drop=True の意味、set_index() や sort_index() との違い、そして「実行したのに反映されない」と感じる原因を、初心者向けに整理します。
まずは、元のインデックスを残すか、捨てるかで判断できるようになれば十分です。
先に結論:迷ったらこの3つで判断します
reset_index() で最初に迷いやすいのは、主に次の3つです。
| やりたいこと | 使う書き方 | 考え方 |
|---|---|---|
| インデックスを0から振り直したい | df = df.reset_index(drop=True) |
元のインデックスが不要なら基本はこれ |
| 元のインデックスを列として残したい | df = df.reset_index() |
元の行番号や元データの位置を確認したい場合 |
| 特定の列をインデックスにしたい | df = df.set_index("列名") |
商品ID・日付などをインデックスにしたい場合 |
この記事で最も大事なのは、次の判断です。
元のインデックスが不要なら reset_index(drop=True)、元のインデックスを残したいなら reset_index() を使います。
条件抽出・欠損値削除・重複削除・並び替えのあとに「左端の番号を見やすくしたい」だけなら、まずは reset_index(drop=True) を選べば大丈夫です。
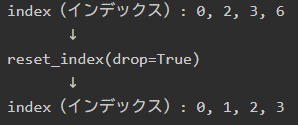
図解:reset_index(drop=True)で何が変わるのか
reset_index(drop=True) のイメージは、次のように考えるとわかりやすいです。
条件抽出後
index(インデックス): 0, 2, 3, 6
↓
reset_index(drop=True)
↓
index(インデックス): 0, 1, 2, 3
つまり、reset_index(drop=True) は、抽出後に残っていた元のインデックスを捨てて、上から順番に 0, 1, 2, 3... と振り直す処理です。
一方、reset_index() のように drop=True を付けない場合は、元のインデックスを列として残します。今回のように元のインデックスに名前がない場合は、通常 index という列名になります。
この記事でわかること
この記事では、次の内容を扱います。
reset_index()で何ができるか- index(インデックス)が飛び飛びになる理由
reset_index()とreset_index(drop=True)の違いdrop=Trueを使う場面・使わないほうがよい場面reset_index()が反映されない原因inplace=Trueより代入する書き方をおすすめする理由set_index()、sort_index()、concat(ignore_index=True)との違い
この記事の中心は、条件抽出・削除・並び替えのあとに、インデックスをどう整えるかです。
groupby() や value_counts() などの集計後に使う例も紹介しますが、初心者のうちは「集計結果を普通のDataFrameに戻すことがある」と押さえれば十分です。
reset_index()の基本
まずは、reset_index() をどの場面で使うのかを整理します。
reset_index() は、DataFrameを加工したあとに、インデックスを整えるためによく使います。
よくある場面は次の通りです。
- 条件抽出したあと
- 欠損値や重複行を削除したあと
- 並び替えたあと
- グループごとに集計したあと
- 複数のDataFrameを結合したあと
「データを加工したあと、左端のインデックスを見やすく整える処理」と考えるとわかりやすいです。
reset_index()とは何か
reset_index() は、DataFrameのindex(インデックス)をリセットするためのメソッドです。
たとえば、条件抽出をすると、元のインデックスがそのまま残ることがあります。
| 状態 | インデックスの例 |
|---|---|
| 元のDataFrame | 0, 1, 2, 3, 4 |
| 条件抽出後 | 1, 3, 4 |
reset_index(drop=True) 後 |
0, 1, 2 |
見た目の行番号を0から振り直したいだけなら、基本は reset_index(drop=True) を使います。
ただし、元のインデックスにも意味がある場合は、drop=True を付けずに reset_index() を使い、元のインデックスを列として残すこともあります。
つまり、reset_index() は「必ず使うもの」ではなく、次の処理でインデックスをどう扱いたいかによって使い分けるものです。
サンプルデータを作成する
ここからは、Google Colabでそのまま実行しやすい小さなデータを使います。
今回は、売上データのようなDataFrameを作ります。
import pandas as pd
df = pd.DataFrame({
"注文ID": [101, 102, 103, 104, 105, 106, 107],
"商品": ["ノート", "ペン", "ノート", "電卓", "ペン", "ファイル", "電卓"],
"地域": ["東京", "大阪", "東京", "福岡", "大阪", "東京", "福岡"],
"売上": [1200, 500, 1800, 3200, 700, 900, 3500],
"数量": [2, 5, 3, 1, 7, 4, 2]
})
print("元のDataFrame")
display(df)
元のDataFrame
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 1 | 102 | ペン | 大阪 | 500 | 5 |
| 2 | 103 | ノート | 東京 | 1800 | 3 |
| 3 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 4 | 105 | ペン | 大阪 | 700 | 7 |
| 5 | 106 | ファイル | 東京 | 900 | 4 |
| 6 | 107 | 電卓 | 福岡 | 3500 | 2 |
元のDataFrameでは、左端のindex(インデックス)が 0, 1, 2, 3... と連番になっています。
ただし、このインデックスは「表示上の番号」ではなく、Pandasが行を識別するために持っているラベルです。
条件抽出後にインデックスが飛び飛びになる理由
たとえば、売上が1000円以上の行だけを抽出してみます。
df_high = df[df["売上"] >= 1000]
print("売上が1000円以上の行だけを抽出")
display(df_high)
売上が1000円以上の行だけを抽出
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 2 | 103 | ノート | 東京 | 1800 | 3 |
| 3 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 6 | 107 | 電卓 | 福岡 | 3500 | 2 |
reset_index()とreset_index(drop=True)の違いを確認する
reset_index() で混乱しやすいのは、次の3つの状態の違いです。
| 状態 | インデックスの見え方 | 元のインデックス列 |
|---|---|---|
| 条件抽出後 | 元のインデックスが残るため飛び飛びになる | まだ列にはならない |
reset_index() 後 |
0からの連番になる | 列として残る(今回の例ではindex列) |
reset_index(drop=True) 後 |
0からの連番になる | 残らない |
実際に、同じデータを3つ並べて確認してみましょう。
print("① 条件抽出後:元のindexが残る")
display(df_high)
print("② reset_index()後:元のindexが列として残る")
display(df_high.reset_index())
print("③ reset_index(drop=True)後:元のindexを捨てて0から振り直す")
display(df_high.reset_index(drop=True))
① 条件抽出後:元のindexが残る
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 2 | 103 | ノート | 東京 | 1800 | 3 |
| 3 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 6 | 107 | 電卓 | 福岡 | 3500 | 2 |
② reset_index()後:元のindexが列として残る
| index | 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|---|
| 0 | 0 | 101 | ノート | 東京 | 1200 | 2 |
| 1 | 2 | 103 | ノート | 東京 | 1800 | 3 |
| 2 | 3 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 3 | 6 | 107 | 電卓 | 福岡 | 3500 | 2 |
③ reset_index(drop=True)後:元のindexを捨てて0から振り直す
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 1 | 103 | ノート | 東京 | 1800 | 3 |
| 2 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 3 | 107 | 電卓 | 福岡 | 3500 | 2 |
抽出結果を見ると、左端のインデックスが 0, 2, 3, 6 のように飛び飛びになっているはずです。
これはエラーではありません。
Pandasは、条件に合う行を取り出しても、元のDataFrameで使われていたインデックスをそのまま残します。
| 処理 | インデックスの状態 |
|---|---|
| 元のDataFrame | 0, 1, 2, 3, 4, 5, 6 |
| 条件抽出後 | 0, 2, 3, 6 |
| インデックスを振り直した後 | 0, 1, 2, 3 |
このように、抽出後の表を見やすくしたい場合に reset_index() を使います。
reset_index()だけを使うと元のインデックスが列として残る
まずは、drop=True を付けずに reset_index() を使ってみます。
df_reset = df_high.reset_index()
print("reset_index()を使った結果")
display(df_reset)
reset_index()を使った結果
| index | 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|---|
| 0 | 0 | 101 | ノート | 東京 | 1200 | 2 |
| 1 | 2 | 103 | ノート | 東京 | 1800 | 3 |
| 2 | 3 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 3 | 6 | 107 | 電卓 | 福岡 | 3500 | 2 |
reset_index() を使うと、左端のインデックスは 0, 1, 2, 3 の連番になります。
ただし、元のインデックスが列として残ります。今回の例では、元のインデックスに名前がないため、index という列名になります。
| 処理 | 結果 |
|---|---|
reset_index() |
新しいインデックスを0から作り、元のインデックスを列として残す |
reset_index(drop=True) |
新しいインデックスを0から作り、元のインデックスは捨てる |
元のインデックスに意味がある場合は、列として残すのも有効です。
たとえば、元データの何行目から来たのかを確認したい場合には、reset_index() が役立ちます。
reset_index(drop=True)でインデックスを0から振り直す
見た目の行番号を0から振り直したいだけなら、drop=True を付けます。
df_high_reset = df_high.reset_index(drop=True)
print("reset_index(drop=True)を使った結果")
display(df_high_reset)
reset_index(drop=True)を使った結果
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 1 | 103 | ノート | 東京 | 1800 | 3 |
| 2 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 3 | 107 | 電卓 | 福岡 | 3500 | 2 |
reset_index(drop=True) を使うと、元のインデックス列を残さず、左端のインデックスだけが0からの連番になります。
初心者のうちは、条件抽出や削除のあとに「左端の番号をきれいにしたい」だけなら、次の書き方を基本にするとわかりやすいです。
df = df.reset_index(drop=True)
ただし、元のインデックスにも意味がある場合は、drop=True を付けるとその情報は消えます。
迷ったときは、「元のインデックスをあとで使うか」を考えると判断しやすくなります。
drop=Trueを使わないほうがよいケース
drop=True は便利ですが、いつでも付ければよいわけではありません。
元のインデックスが「元データのどの行から来たか」を確認する手がかりになる場合は、drop=True を付けずに reset_index() を使う方が安全です。
| 状況 | おすすめ |
|---|---|
| 抽出後の表を見やすくしたいだけ | reset_index(drop=True) |
| 元データの行位置をあとで確認したい | reset_index() |
| CSV保存やグラフ化の前に形を整えたい | 多くの場合 reset_index(drop=True) |
groupby() の集計結果を普通の列に戻したい |
reset_index() |
つまり、見た目を整えるなら drop=True、元のインデックス情報を残したいなら drop=True なしと考えると整理しやすいです。
実務でよくある使い方
ここからは、reset_index() が実際のデータ加工でよく出てくる場面を確認します。
欠損値や重複を削除したあとにもreset_index()を使う
reset_index() は、条件抽出だけでなく、dropna() や drop_duplicates() のあとにもよく使います。
ここでは、欠損値と重複を含む小さなデータで確認します。
df_dirty = pd.DataFrame({
"注文ID": [201, 202, 203, 204, 204, 205],
"商品": ["ノート", "ペン", None, "電卓", "電卓", "ファイル"],
"売上": [1200, 500, 1800, 3200, 3200, None]
})
print("欠損値と重複を含むDataFrame")
display(df_dirty)
df_clean = df_dirty.dropna().drop_duplicates()
print("欠損値と重複を削除した後")
display(df_clean)
df_clean_reset = df_clean.reset_index(drop=True)
print("indexを振り直した後")
display(df_clean_reset)
欠損値と重複を含むDataFrame
| 注文ID | 商品 | 売上 | |
|---|---|---|---|
| 0 | 201 | ノート | 1200.0 |
| 1 | 202 | ペン | 500.0 |
| 2 | 203 | None | 1800.0 |
| 3 | 204 | 電卓 | 3200.0 |
| 4 | 204 | 電卓 | 3200.0 |
| 5 | 205 | ファイル | NaN |
欠損値と重複を削除した後
| 注文ID | 商品 | 売上 | |
|---|---|---|---|
| 0 | 201 | ノート | 1200.0 |
| 1 | 202 | ペン | 500.0 |
| 3 | 204 | 電卓 | 3200.0 |
indexを振り直した後
| 注文ID | 商品 | 売上 | |
|---|---|---|---|
| 0 | 201 | ノート | 1200.0 |
| 1 | 202 | ペン | 500.0 |
| 2 | 204 | 電卓 | 3200.0 |
欠損値や重複を削除すると、削除された行のインデックスが抜けるため、左端の番号が飛び飛びになることがあります。
その後に reset_index(drop=True) を使うと、次の処理に進むときに表が見やすくなります。
ただし、dropna() や drop_duplicates() の詳しい使い方は別テーマです。この記事では、削除後にインデックスを整える場面として押さえれば十分です。
sort_values()・sort_index()との違い
次に、売上が大きい順に並び替えてみます。
ここでは、sort_values() と sort_index() の違いもあわせて確認します。
df_sorted = df.sort_values("売上", ascending=False)
print("売上が大きい順に並び替え")
display(df_sorted)
df_sorted_reset = df_sorted.reset_index(drop=True)
print("並び替え後にindexを振り直し")
display(df_sorted_reset)
print("参考:sort_index()はindexの順番で並び替える")
display(df_sorted.sort_index())
売上が大きい順に並び替え
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 6 | 107 | 電卓 | 福岡 | 3500 | 2 |
| 3 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 2 | 103 | ノート | 東京 | 1800 | 3 |
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 5 | 106 | ファイル | 東京 | 900 | 4 |
| 4 | 105 | ペン | 大阪 | 700 | 7 |
| 1 | 102 | ペン | 大阪 | 500 | 5 |
並び替え後にindexを振り直し
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 107 | 電卓 | 福岡 | 3500 | 2 |
| 1 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 2 | 103 | ノート | 東京 | 1800 | 3 |
| 3 | 101 | ノート | 東京 | 1200 | 2 |
| 4 | 106 | ファイル | 東京 | 900 | 4 |
| 5 | 105 | ペン | 大阪 | 700 | 7 |
| 6 | 102 | ペン | 大阪 | 500 | 5 |
参考:sort_index()はindexの順番で並び替える
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 1 | 102 | ペン | 大阪 | 500 | 5 |
| 2 | 103 | ノート | 東京 | 1800 | 3 |
| 3 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 4 | 105 | ペン | 大阪 | 700 | 7 |
| 5 | 106 | ファイル | 東京 | 900 | 4 |
| 6 | 107 | 電卓 | 福岡 | 3500 | 2 |
sort_values() で並び替えると、行の順番は変わりますが、元のインデックスは残ります。
売上順のランキング表のように見せたい場合は、reset_index(drop=True) で0から振り直すと読みやすくなります。
一方、通常の sort_index() はインデックスの順番で行を並び替えるためのメソッドです。reset_index() のように「現在の行順のままインデックスを0から振り直す」操作とは目的が異なります。
| メソッド | 何を基準にするか | 使う場面 |
|---|---|---|
sort_values("売上") |
列の値 | 売上順・点数順に並べたい |
sort_index() |
インデックス | インデックス順に並べたい |
reset_index(drop=True) |
現在の行の並び | 左端のインデックスを0から振り直したい |
並び順を変えるのが sort_values() や sort_index()、インデックスを整えるのが reset_index() と覚えると迷いにくいです。
reset_index()が反映されない原因とinplace=Trueの考え方
初心者がつまずきやすいのが、reset_index() を実行したのに元のDataFrameが変わっていないように見えるケースです。
原因は、reset_index() は基本的に新しいDataFrameを返すだけで、元のDataFrameを直接変更しないためです。
df_temp = df[df["地域"] == "東京"]
print("抽出後のDataFrame")
display(df_temp)
# この行だけでは、df_temp自体は変更されません
df_temp.reset_index(drop=True)
print("reset_index(drop=True)を実行しただけのdf_temp")
display(df_temp)
# 代入すると反映されます
df_temp = df_temp.reset_index(drop=True)
print("代入した後のdf_temp")
display(df_temp)
抽出後のDataFrame
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 2 | 103 | ノート | 東京 | 1800 | 3 |
| 5 | 106 | ファイル | 東京 | 900 | 4 |
reset_index(drop=True)を実行しただけのdf_temp
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 2 | 103 | ノート | 東京 | 1800 | 3 |
| 5 | 106 | ファイル | 東京 | 900 | 4 |
代入した後のdf_temp
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 1 | 103 | ノート | 東京 | 1800 | 3 |
| 2 | 106 | ファイル | 東京 | 900 | 4 |
reset_index() の結果を使いたい場合は、次のように代入します。
df_temp = df_temp.reset_index(drop=True)
inplace=True を使う方法もあります。
df_temp.reset_index(drop=True, inplace=True)
ただし、初心者には基本的に 代入する書き方 をおすすめします。
| 書き方 | 初心者向けのおすすめ度 | 理由 |
|---|---|---|
df = df.reset_index(drop=True) |
高い | 処理の前後が追いやすい |
df.reset_index(drop=True, inplace=True) |
低め | 元データを直接変更するため、戻しにくい |
inplace=True は使ってはいけないわけではありません。
大きなデータでメモリ使用量を意識する場面や、一時的な処理で元データを直接更新したい場面で使われることもあります。
ただし、inplace=True が常にメモリ面で有利とは限りません。また、処理の前後が見えにくくなり、学習中は「どの時点でDataFrameが変わったのか」を追いにくくなります。
そのため、このブログでは初心者向けに、まずは次のような代入する書き方を基本にします。
df = df.reset_index(drop=True)
「処理した結果を新しいDataFrameとして受け取る」と考えると、Pandasの流れを理解しやすくなります。
関連メソッドとの違い・使い分け
ここからは、reset_index() と一緒に検索されやすいメソッドとの違いを整理します。
全部を一度に深く覚える必要はありません。まずは、何をしたいときにどのメソッドを選ぶかを押さえれば大丈夫です。
set_index()との違い
reset_index() とよく混同されるのが、set_index() です。
set_index():列をインデックスにするreset_index():インデックスを列に戻す、または0から振り直す
実際に、注文ID をインデックスにしてから、元に戻してみます。
df_order_index = df.set_index("注文ID")
print("注文IDをindexにしたDataFrame")
display(df_order_index)
df_order_reset = df_order_index.reset_index()
print("reset_index()で注文IDを列に戻したDataFrame")
display(df_order_reset)
注文IDをindexにしたDataFrame
| 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|
| 101 | ノート | 東京 | 1200 | 2 |
| 102 | ペン | 大阪 | 500 | 5 |
| 103 | ノート | 東京 | 1800 | 3 |
| 104 | 電卓 | 福岡 | 3200 | 1 |
| 105 | ペン | 大阪 | 700 | 7 |
| 106 | ファイル | 東京 | 900 | 4 |
| 107 | 電卓 | 福岡 | 3500 | 2 |
reset_index()で注文IDを列に戻したDataFrame
| 注文ID | 商品 | 地域 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 101 | ノート | 東京 | 1200 | 2 |
| 1 | 102 | ペン | 大阪 | 500 | 5 |
| 2 | 103 | ノート | 東京 | 1800 | 3 |
| 3 | 104 | 電卓 | 福岡 | 3200 | 1 |
| 4 | 105 | ペン | 大阪 | 700 | 7 |
| 5 | 106 | ファイル | 東京 | 900 | 4 |
| 6 | 107 | 電卓 | 福岡 | 3500 | 2 |
この例では、set_index("注文ID") によって、注文ID 列がインデックスになります。
その後、reset_index() を使うと、インデックスだった 注文ID が普通の列に戻ります。
| やりたいこと | 使うメソッド |
|---|---|
| 列をインデックスにしたい | set_index() |
| インデックスを普通の列に戻したい | reset_index() |
| インデックスを0からの連番に戻したい | reset_index(drop=True) |
set_index() はインデックスをリセットする関数ではありません。
「何かの列をインデックスとして使いたい」のか、「インデックスを普通の形に戻したい」のかを分けて考えると、迷いにくくなります。
groupby()やvalue_counts()のあとにreset_index()を使う場面
reset_index() は、集計結果を普通のDataFrameとして扱いやすくしたいときにも使います。
ただし、ここでは深追いせず、集計結果でインデックスになったものを列に戻せるという考え方だけ押さえれば十分です。
sales_by_area = df.groupby("地域")["売上"].sum()
print("groupby()の結果")
display(sales_by_area)
sales_by_area_df = sales_by_area.reset_index()
print("reset_index()でDataFrameとして扱いやすくした結果")
display(sales_by_area_df)
groupby()の結果
| 売上 | |
|---|---|
| 大阪 | 1200 |
| 東京 | 3900 |
| 福岡 | 6700 |
reset_index()でDataFrameとして扱いやすくした結果
| 地域 | 売上 | |
|---|---|---|
| 0 | 大阪 | 1200 |
| 1 | 東京 | 3900 |
| 2 | 福岡 | 6700 |
groupby() の結果では、地域 がインデックスになっています。
このままでも集計結果としては使えますが、CSV保存やグラフ化、別のDataFrameとの結合を考えると、reset_index() で普通の列に戻した方が扱いやすいことがあります。
同じ考え方は、value_counts() の結果にも使えます。
なお、groupby(as_index=False) という書き方もありますが、初心者のうちはまず「集計後にインデックスになった列を reset_index() で戻す」と理解すれば十分です。
product_counts = df["商品"].value_counts()
print("value_counts()の結果")
display(product_counts)
product_counts_df = product_counts.reset_index()
product_counts_df.columns = ["商品", "件数"]
print("reset_index()でDataFrameに整えた結果")
display(product_counts_df)
value_counts()の結果
| count | |
|---|---|
| ノート | 2 |
| ペン | 2 |
| 電卓 | 2 |
| ファイル | 1 |
reset_index()でDataFrameに整えた結果
| 商品 | 件数 | |
|---|---|---|
| 0 | ノート | 2 |
| 1 | ペン | 2 |
| 2 | 電卓 | 2 |
| 3 | ファイル | 1 |
value_counts() の結果も、必要に応じて reset_index() でDataFrameの形に整えられます。
ここで大事なのは、groupby() や value_counts() の細かい使い方ではありません。
インデックスになっている情報を、普通の列として扱いたいときに reset_index() が役立つという点だけ押さえておけば十分です。
concat(ignore_index=True)との違い
複数のDataFrameを縦に結合するときは、reset_index() ではなく、concat(ignore_index=True) が便利なことがあります。
まずは、2つのDataFrameを縦に結合してみます。
df_a = pd.DataFrame({
"商品": ["ノート", "ペン"],
"売上": [1200, 500]
})
df_b = pd.DataFrame({
"商品": ["電卓", "ファイル"],
"売上": [3200, 900]
})
df_concat = pd.concat([df_a, df_b])
print("ignore_index=Trueなしで結合")
display(df_concat)
df_concat_ignore = pd.concat([df_a, df_b], ignore_index=True)
print("ignore_index=Trueで結合")
display(df_concat_ignore)
ignore_index=Trueなしで結合
| 商品 | 売上 | |
|---|---|---|
| 0 | ノート | 1200 |
| 1 | ペン | 500 |
| 0 | 電卓 | 3200 |
| 1 | ファイル | 900 |
ignore_index=Trueで結合
| 商品 | 売上 | |
|---|---|---|
| 0 | ノート | 1200 |
| 1 | ペン | 500 |
| 2 | 電卓 | 3200 |
| 3 | ファイル | 900 |
pd.concat() で縦に結合すると、元のDataFrameのインデックスがそのまま残るため、0, 1, 0, 1 のようにインデックスが重複することがあります。
結合する時点で最初から連番にしたい場合は、ignore_index=True が便利です。
| 場面 | 使う方法 |
|---|---|
| すでにあるDataFrameのインデックスを後から整える | reset_index(drop=True) |
| 複数DataFrameを結合するときに最初から連番にする | concat(ignore_index=True) |
concat() の詳しい使い方は別記事で扱う内容なので、ここでは「結合時にはignore_indexも候補になる」と押さえておけば十分です。
補足:似たメソッドとの違いはここまででOK
reset_index() を調べていると、set_index()、sort_index()、reindex() など、似た名前のメソッドも出てきます。
初心者のうちは、まず次の違いがわかれば十分です。
| メソッド | 役割 | 最初に覚えるポイント |
|---|---|---|
reset_index() |
インデックスをリセットする、または列に戻す | 最重要 |
reset_index(drop=True) |
元のインデックスを捨てて0から振り直す | 抽出・削除・並び替え後によく使う |
set_index() |
列をインデックスにする | reset_index() とは反対方向の操作 |
sort_index() |
インデックス順に並べ替える | 通常は並び替えが目的で、reset_index() とは役割が異なる |
concat(ignore_index=True) |
結合時に新しい連番インデックスを作る | 縦結合で便利 |
reindex() や rename_axis()、MultiIndex は発展的な内容です。必要になったときに学べば問題ありません。
この関数の次にやること:データ分析の流れで考える
reset_index() は、単独で覚えるよりも、データ分析の流れの中で考えると理解しやすくなります。
たとえば、次のような流れです。
- CSVを読み込む
head()やinfo()でDataFrameを確認する- 条件抽出や欠損値処理をする
- 並び替える
- 必要に応じて
reset_index(drop=True)でインデックスを整える - 集計・グラフ化・CSV保存に進む
抽出・削除・並び替えのあとに表を見やすく整えたい場合は、reset_index(drop=True) がよく使われます。
一方で、元の行番号を追跡したい場合は、drop=True を付けずに元のインデックスを列として残します。
関連メソッドの違いで迷ったときは、次のように考えると整理しやすいです。
| やりたいこと | 選ぶ操作 |
|---|---|
| 今の行順のままインデックスを振り直したい | reset_index(drop=True) |
| インデックスを普通の列に戻したい | reset_index() |
| 列をインデックスにしたい | set_index() |
| インデックス順に並び替えたい | sort_index() |
| 縦結合の時点で連番にしたい | concat(ignore_index=True) |
まずは reset_index(drop=True) を基本形として覚え、必要に応じて他のメソッドとの違いを確認していきましょう。
まとめ
この記事では、pandas reset_index の使い方を初心者向けに解説しました。
重要なポイントは次の通りです。
reset_index()は、DataFrameのindex(インデックス)をリセットするために使う- 条件抽出・削除・並び替えのあと、インデックスが飛び飛びになることがある
- 元のインデックスが不要なら
reset_index(drop=True)が基本 - 元のインデックスを列として残したいなら
reset_index()を使う drop=Trueを付けると、元のインデックス情報は列として残らないreset_index()の結果を反映するには、代入する書き方がわかりやすいset_index()は列をインデックスにする操作sort_index()はインデックス順に並び替える操作concat(ignore_index=True)は結合時に新しい連番インデックスを作る方法
初心者のうちは、次の判断で十分です。
| 状況 | 書き方 |
|---|---|
| 左端の番号を0から振り直したい | df = df.reset_index(drop=True) |
| 元のインデックスを列として残したい | df = df.reset_index() |
| 列をインデックスにしたい | df = df.set_index("列名") |
| インデックス順に並べ替えたい | df = df.sort_index() |
迷ったら、「元のインデックスをあとで使うか」を考えると判断しやすくなります。
まずは reset_index(drop=True) を基本形として覚え、元のインデックスを残したい場面だけ reset_index() を使う、と整理しておきましょう。
次に読みたい関連記事
この記事とあわせて読むと、Pandasの前処理から集計までの流れが理解しやすくなります。
まずは、次の順番で読むのがおすすめです。
- Pandas DataFrame入門|作り方・基本操作をわかりやすく解説
- pandas 条件抽出(filtering)入門|AND/OR・query関数・複数条件の指定方法
- Pandas dropna()・drop_duplicates()の使い方|欠損/重複の削除とdrop()基本
- pandas 並び替え(sort)入門|sort_values・sort_indexの違いと複数列ソート
- Pandas groupby×aggの使い方|基本の集計とaggの書き方を例で解説
- Pandas concat完全ガイド|複数CSVからDataFrameを縦横結合する方法
- pandas rename()の使い方|列名変更・一部だけ変更・反映されない原因を初心者向けに解説
reset_index() は、条件抽出・削除・並び替え・結合などのあとに使うことが多いので、上の記事とあわせて読むと前処理の流れがつながります。
reset_index(drop=True)は何をするのですか?
reset_index(drop=True) は、元のindex(インデックス)を列として残さず、新しく0から連番のindexに振り直す方法です。条件抽出や並び替えの後に、左端の番号をきれいに整えたい場合によく使います。
reset_index()とset_index()の違いは何ですか?
reset_index() は、indexを普通の列に戻したり、0から振り直したりするメソッドです。一方、set_index() は、指定した列をindexに設定するメソッドです。
reset_index()が反映されないのはなぜですか?
reset_index() は元のDataFrameを直接書き換えず、新しいDataFrameを返します。そのため、結果を使いたい場合は df = df.reset_index(drop=True) のように代入する必要があります。
pandasでインデックスを0から振り直すにはどうすればよいですか?
元のindexが不要な場合は、df = df.reset_index(drop=True) と書くのが基本です。条件抽出、欠損値削除、重複削除、並び替えの後によく使います。
sort_values()やsort_index()との違いは何ですか?
sort_values() は値で並び替えるメソッド、sort_index() は通常、indexの順番で並び替えるメソッドです。reset_index() は並び替えではなく、現在の行順のままindexを振り直すためのメソッドです。
drop=Trueを使わないほうがよいのはどんなときですか?
元のインデックスに意味がある場合です。たとえば、抽出後の行が元データのどの行から来たのかを確認したい場合は、drop=True を付けずに reset_index() を使うと、元のインデックスを列として残せます。
コメント