CSVやExcelを読み込んだあと、画面上では「1000」「2500」のように数字に見えるのに、sum()やmean()でうまく計算できないことがあります。
その原因の1つが、数字に見える列が、pandas上では文字列(object型)として扱われていることです。
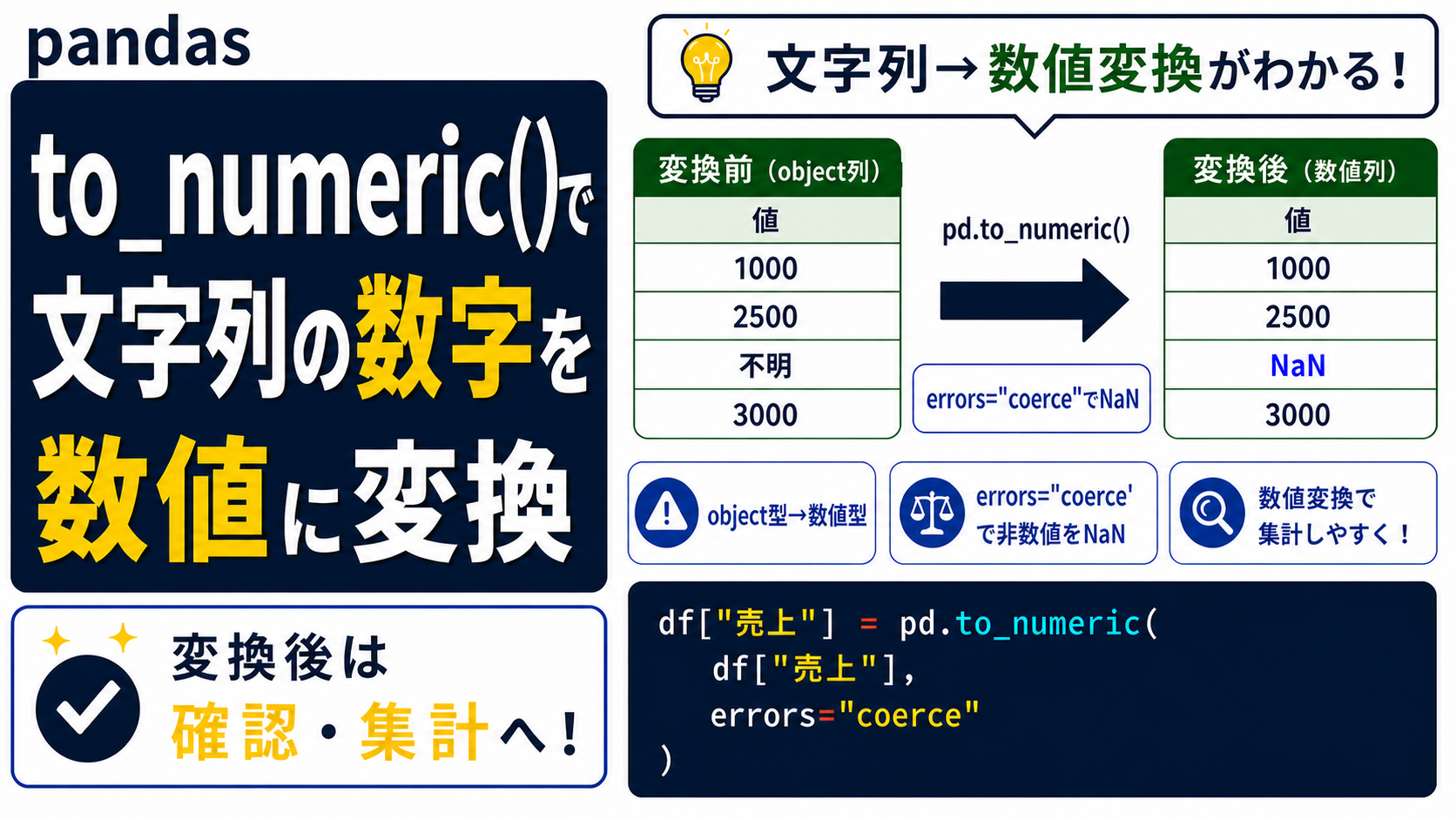
このようなときに役立つのが、pd.to_numeric()です。
pd.to_numeric()は、数字に見える文字列を、計算できる数値型に変換するための関数です。特に、列の中に「不明」「-」「空欄」など、数値に変換できない値が混ざっている場合は、errors="coerce"を使うと安全に確認しながら前処理できます。
この記事では、to_numeric()の基本から、astype()との違い、errors="coerce"でNaNになる理由、変換後に集計や可視化へつなげる流れまで、初心者向けに順番に解説します。
- この記事でわかること
- Pandas前処理の中での位置づけ
- まず結論:to_numeric()は「計算できる数値」に変換するために使う
- 数字に見えるのに計算できない例
- to_numeric()の基本的な使い方
- 処理前後で見る:文字列の数字が数値になる
- 変換できない値が混ざるとエラーになる
- errors=”coerce”で変換できない値をNaNにする
- NaNになった行を確認する
- errorsの違いを軽く整理する
- to_numeric()とastype()の違い
- カンマ入り数値や「円」付きの金額を数値化する
- 変換後のNaNをどう扱うか
- 数値化できると集計や可視化に進みやすくなる
- すべてのobject型を数値化すればよいわけではない
- よくあるミスと確認ポイント
- まとめ
- 次に読みたい関連記事
この記事でわかること
この記事では、次の内容を学びます。
pd.to_numeric()で文字列の数字を数値に変換する方法- 数字に見える列が
object型になってしまう理由 errors="coerce"で変換できない値をNaNにする考え方to_numeric()とastype()の違い- カンマ入り数値や「円」付きの金額を数値化する基本
- 変換後に
fillna()、dropna()、groupby()、グラフ化へつなげる流れ
この記事のゴールは、数字に見えるのに計算できない列を、to_numeric()で安全に数値化し、欠損確認・集計・可視化へ進める前処理の流れを理解することです。
Pandas前処理の中での位置づけ
to_numeric()は、Pandasの前処理の中では「型を整える」場面で使います。
データ分析では、次のような流れで作業することが多いです。
- CSVやExcelを読み込む
head()やinfo()でデータの状態を確認する- 文字列になっている数値列を数値型に変換する
- 欠損値や変換できなかった値を処理する
- 集計やグラフ化に進む
to_numeric()は、特に3番目の「文字列になっている数値列を数値型に変換する」場面で役立ちます。
Pandasの基本的な流れを先に確認したい場合は、以下の記事も参考になります。
まず結論:to_numeric()は「計算できる数値」に変換するために使う
pd.to_numeric()は、文字列として入っている数字を、計算できる数値型に変換するために使います。
たとえば、次のような列があるとします。
| 変換前の値 | pandas上の見え方 | 問題 |
|---|---|---|
"1000" |
文字列 | 見た目は数字だが、計算用の数値ではない |
"2500" |
文字列 | 合計や平均で意図しない結果になることがある |
"不明" |
文字列 | 数値に変換できない |
"-" |
文字列 | 欠損や未入力を表している可能性がある |
このような列を扱うときは、まずinfo()やdtypesで型を確認し、必要に応じてpd.to_numeric()で数値化します。
判断基準:売上・数量・点数・金額のように「合計や平均を出したい列」はto_numeric()で数値化します。一方、商品コード・郵便番号・電話番号のような「識別のための列」は、数字に見えても文字列のまま扱うことがあります。
import pandas as pd
# サンプルデータ:売上が文字列として入っている例
df = pd.DataFrame({
"商品": ["A", "B", "C", "D"],
"売上": ["1000", "2500", "1800", "3200"],
"数量": ["2", "5", "3", "4"]
})
display(df)
print(df.dtypes)
| 商品 | 売上 | 数量 | |
|---|---|---|---|
| 0 | A | 1000 | 2 |
| 1 | B | 2500 | 5 |
| 2 | C | 1800 | 3 |
| 3 | D | 3200 | 4 |
商品 object
売上 object
数量 object
dtype: object上の例では、売上列も数量列も見た目は数字ですが、dtypesを見るとobject型になっています。
object型は、文字列などが入っているときによく見られる型です。つまり、この状態では「数字のように見える文字列」として扱われています。
数字に見えるのに計算できない例
文字列のまま集計しようとすると、思った結果にならないことがあります。
たとえば、文字列の列に対してsum()を使うと、数値の合計ではなく、文字列がつながってしまう場合があります。
# 文字列のままsum()すると、数値の合計ではなく文字列の連結になることがあります
print(df["売上"].sum())
# 平均は計算できないため、エラーになります
try:
print(df["売上"].mean())
except Exception as e:
print(type(e).__name__)
print(e)
1000250018003200
TypeError
Could not convert string '1000250018003200' to numericこのように、見た目が数字でも、pandas上で文字列として扱われていると、集計や平均計算で困ることがあります。
そのため、CSVやExcelを読み込んだあとに計算がうまくいかない場合は、まず次の順番で確認します。
info()またはdtypesで型を見る- 数値として使いたい列が
object型になっていないか確認する - 必要なら
pd.to_numeric()で数値型に変換する
次に、実際にto_numeric()で変換してみます。
to_numeric()の基本的な使い方
pd.to_numeric()の基本形は、次のように書きます。
df["列名"] = pd.to_numeric(df["列名"])
ここでは、売上列と数量列を数値に変換します。
df_basic = df.copy()
df_basic["売上"] = pd.to_numeric(df_basic["売上"])
df_basic["数量"] = pd.to_numeric(df_basic["数量"])
display(df_basic)
print(df_basic.dtypes)
| 商品 | 売上 | 数量 | |
|---|---|---|---|
| 0 | A | 1000 | 2 |
| 1 | B | 2500 | 5 |
| 2 | C | 1800 | 3 |
| 3 | D | 3200 | 4 |
商品 object
売上 int64
数量 int64
dtype: object変換後は、売上列と数量列が数値型になりました。
この状態になれば、合計や平均を自然に計算できます。
print("売上合計:", df_basic["売上"].sum())
print("売上平均:", df_basic["売上"].mean())
print("数量合計:", df_basic["数量"].sum())
売上合計: 8500
売上平均: 2125.0
数量合計: 14複数列をまとめて数値に変換したい場合
慣れてきたら、複数の列をまとめてto_numeric()で変換することもできます。
ただし、初心者のうちは、まず1列ずつ変換して、どの列でNaNが出たか確認する方が安全です。ここでは、売上列と数量列をまとめて変換する最小例だけ確認します。
df_multi = df.copy()
cols = ["売上", "数量"]
df_multi[cols] = df_multi[cols].apply(pd.to_numeric, errors="coerce")
display(df_multi)
print(df_multi.dtypes)
| 商品 | 売上 | 数量 | |
|---|---|---|---|
| 0 | A | 1000 | 2 |
| 1 | B | 2500 | 5 |
| 2 | C | 1800 | 3 |
| 3 | D | 3200 | 4 |
商品 object
売上 int64
数量 int64
dtype: object複数列をまとめて変換するとコードは短くなります。
一方で、どの列に変換できない値があったのか見落としやすくなることもあります。そのため、最初は1列ずつ確認し、慣れてきたら複数列の一括変換を使うのがおすすめです。
処理前後で見る:文字列の数字が数値になる
to_numeric()の役割を、処理前後で整理すると次のようになります。
| 状態 | 売上列の例 | pandas上の型 | できること |
|---|---|---|---|
| 変換前 | "1000" |
object | 見た目は数字でも、計算で困ることがある |
| 変換後 | 1000 |
intまたはfloat | 合計・平均・集計・グラフ化に使いやすい |
ポイントは、表示されている見た目ではなく、pandas上の型を確認することです。
「数字に見えるから大丈夫」と判断せず、info()やdtypesで確認する習慣をつけると、前処理で迷いにくくなります。
変換できない値が混ざるとエラーになる
実際のCSVやExcelでは、数値列の中に「不明」「-」「空欄」「error」などが混ざっていることがあります。
たとえば、次のような売上データを考えます。
df_dirty = pd.DataFrame({
"商品": ["A", "B", "C", "D", "E"],
"カテゴリ": ["食品", "食品", "日用品", "日用品", "食品"],
"売上": ["1000", "2500", "不明", "3000", "-"],
"数量": ["2", "5", "3", "error", "1"]
})
display(df_dirty)
print(df_dirty.dtypes)
| 商品 | カテゴリ | 売上 | 数量 | |
|---|---|---|---|---|
| 0 | A | 食品 | 1000 | 2 |
| 1 | B | 食品 | 2500 | 5 |
| 2 | C | 日用品 | 不明 | 3 |
| 3 | D | 日用品 | 3000 | error |
| 4 | E | 食品 | – | 1 |
商品 object
カテゴリ object
売上 object
数量 object
dtype: object売上列には「不明」や「-」が含まれています。
数量列には「error」が含まれています。
このような列をそのままpd.to_numeric()で変換しようとすると、数値に変換できない値があるためエラーになります。
try:
pd.to_numeric(df_dirty["売上"])
except Exception as e:
print(type(e).__name__)
print(e)
ValueError
Unable to parse string "不明" at position 2エラーが出ること自体は悪いことではありません。
むしろ、「この列には数値に変換できない値が混ざっている」と気づくきっかけになります。
ただし、実務では、変換できない値をいったんNaNにして確認したいことがよくあります。そこで使うのが、errors="coerce"です。
errors=”coerce”で変換できない値をNaNにする
errors="coerce"を指定すると、数値に変換できない値をNaNにできます。
pd.to_numeric(df["列名"], errors="coerce")
coerceは「無理に変換する」という意味に近い指定です。
ただし、ここで大切なのは、エラーを隠すためではなく、変換できなかった値をNaNとして見つけるために使うという考え方です。
df_coerce = df_dirty.copy()
df_coerce["売上_数値"] = pd.to_numeric(df_coerce["売上"], errors="coerce")
df_coerce["数量_数値"] = pd.to_numeric(df_coerce["数量"], errors="coerce")
display(df_coerce)
print(df_coerce.dtypes)
| 商品 | カテゴリ | 売上 | 数量 | 売上_数値 | 数量_数値 | |
|---|---|---|---|---|---|---|
| 0 | A | 食品 | 1000 | 2 | 1000.0 | 2.0 |
| 1 | B | 食品 | 2500 | 5 | 2500.0 | 5.0 |
| 2 | C | 日用品 | 不明 | 3 | NaN | 3.0 |
| 3 | D | 日用品 | 3000 | error | 3000.0 | NaN |
| 4 | E | 食品 | – | 1 | NaN | 1.0 |
商品 object
カテゴリ object
売上 object
数量 object
売上_数値 float64
数量_数値 float64
dtype: object処理前後を表で見ると、次のようなイメージです。
| 変換前 | errors="coerce"後 |
意味 |
|---|---|---|
"1000" |
1000.0 |
数値に変換できた |
"2500" |
2500.0 |
数値に変換できた |
"不明" |
NaN |
数値に変換できなかった |
"3000" |
3000.0 |
数値に変換できた |
"-" |
NaN |
数値に変換できなかった |
to_numeric()後にNaNが出た場合、それは元データに数値化できない値が混ざっていたサインです。
NaNになった行を確認する
errors="coerce"を使ったあとに大切なのは、NaNになった行を確認することです。
NaNになった値は、単なる欠損値ではなく、数値に変換できなかった値である可能性があります。
# 売上_数値がNaNになった行を確認
display(df_coerce[df_coerce["売上_数値"].isna()])
# 数量_数値がNaNになった行を確認
display(df_coerce[df_coerce["数量_数値"].isna()])
| 商品 | カテゴリ | 売上 | 数量 | 売上_数値 | 数量_数値 | |
|---|---|---|---|---|---|---|
| 2 | C | 日用品 | 不明 | 3 | NaN | 3.0 |
| 4 | E | 食品 | – | 1 | NaN | 1.0 |
| 商品 | カテゴリ | 売上 | 数量 | 売上_数値 | 数量_数値 | |
|---|---|---|---|---|---|---|
| 3 | D | 日用品 | 3000 | error | 3000.0 | NaN |
この確認を入れることで、次に何をすべきか判断しやすくなります。
たとえば、
- 「不明」は本当に欠損として扱ってよいのか
- 「-」は未入力を意味するのか
- 「error」は入力ミスなのか
- 行を除外するのか、0で埋めるのか、別途確認するのか
といった判断ができます。
to_numeric()は、数値化するだけでなく、データの汚れを見つける入口としても役立ちます。
errorsの違いを軽く整理する
pd.to_numeric()のerrorsでは、初心者のうちは次の2つを押さえれば十分です。
| 指定 | 動き | 初心者向けの使いどころ |
|---|---|---|
errors="raise" |
変換できない値があるとエラーにする | どこで失敗するか厳密に確認したいとき |
errors="coerce" |
変換できない値をNaNにする |
実務で混ざった不正値を見つけたいとき |
まずは、変換できない値があるとエラーになるerrors="raise"で、データに問題があることを確認できます。
実務では、変換できない値をNaNにしてあとから確認したい場面が多いため、この記事では主にerrors="coerce"を使って説明します。
なお、古い記事や古いpandas環境ではerrors="ignore"を見かけることがあります。
ただし、初心者向けの記事では通常の選択肢として覚える必要はありません。変換できない値を曖昧に残すより、errors="coerce"でNaNにして確認する方が、前処理の流れを理解しやすくなります。
to_numeric()とastype()の違い
数値変換では、astype()もよく使われます。
どちらも型変換に関係しますが、使いどころが少し違います。
| 方法 | 向いている場面 | 注意点 |
|---|---|---|
astype() |
値がきれいで、変換先の型を明示したいとき | 変換できない値が混ざるとエラーになりやすい |
to_numeric() |
数字に見える文字列を数値化したいとき | errors="coerce"でNaNになる値を確認する必要がある |
to_datetime() |
日付文字列を日付型に変換したいとき | 数値ではなく日付用 |
replace() |
「不明」「-」「円」などを置換したいとき | 置換だけでは数値型にはならないことがある |
ざっくり言うと、きれいな値ならastype()、汚れた数値列を安全に扱うならto_numeric()と考えると分かりやすいです。
# astype()は、きれいな値なら分かりやすく変換できます
df_astype_ok = pd.DataFrame({
"売上": ["1000", "2500", "1800"]
})
df_astype_ok["売上"] = df_astype_ok["売上"].astype(int)
display(df_astype_ok)
print(df_astype_ok.dtypes)
| 売上 | |
|---|---|
| 0 | 1000 |
| 1 | 2500 |
| 2 | 1800 |
売上 int64
dtype: object# ただし、不明などが混ざるとastype()ではエラーになります
df_astype_ng = pd.DataFrame({
"売上": ["1000", "2500", "不明", "3000"]
})
try:
df_astype_ng["売上"].astype(int)
except Exception as e:
print(type(e).__name__)
print(e)
ValueError
invalid literal for int() with base 10: '不明'このように、astype()は値がきれいなときには便利です。
一方で、実際のCSVやExcelでは「不明」「-」「空欄」などが混ざることがあります。
そのような場合は、pd.to_numeric(..., errors="coerce")で変換できない値をNaNにして確認する方が、前処理の流れを作りやすくなります。
astype()全体の使い方は、別記事のpandas astype()の使い方で詳しく扱っています。
カンマ入り数値や「円」付きの金額を数値化する
CSVやExcelでは、次のような値が入っていることがあります。
| 値の例 | そのまま数値化できるか | 対応の考え方 |
|---|---|---|
"1,000" |
そのままでは変換しづらい | カンマを削除してから数値化 |
"2,500円" |
そのままでは変換しづらい | カンマと「円」を削除してから数値化 |
"3000円" |
そのままでは変換しづらい | 「円」を削除してから数値化 |
"不明" |
数値化できない | errors="coerce"でNaNにして確認 |
ここでは、複雑な正規表現には深入りせず、基本的な置換だけで考えます。
df_money = pd.DataFrame({
"商品": ["A", "B", "C", "D"],
"売上": ["1,000", "2,500円", "3000円", "不明"]
})
display(df_money)
| 商品 | 売上 | |
|---|---|---|
| 0 | A | 1,000 |
| 1 | B | 2,500円 |
| 2 | C | 3000円 |
| 3 | D | 不明 |
df_money_clean = df_money.copy()
# カンマと「円」を取り除く
df_money_clean["売上_整形後"] = (
df_money_clean["売上"]
.str.replace(",", "", regex=False)
.str.replace("円", "", regex=False)
)
# 数値に変換する
df_money_clean["売上_数値"] = pd.to_numeric(df_money_clean["売上_整形後"], errors="coerce")
display(df_money_clean)
print(df_money_clean.dtypes)
| 商品 | 売上 | 売上_整形後 | 売上_数値 | |
|---|---|---|---|---|
| 0 | A | 1,000 | 1000 | 1000.0 |
| 1 | B | 2,500円 | 2500 | 2500.0 |
| 2 | C | 3000円 | 3000 | 3000.0 |
| 3 | D | 不明 | 不明 | NaN |
商品 object
売上 object
売上_整形後 object
売上_数値 float64
dtype: object処理の流れを整理すると、次のようになります。
| 元の値 | 整形後 | 数値変換後 |
|---|---|---|
"1,000" |
"1000" |
1000.0 |
"2,500円" |
"2500" |
2500.0 |
"3000円" |
"3000" |
3000.0 |
"不明" |
"不明" |
NaN |
ここでのポイントは、replace()やstr.replace()で文字を整えたあと、最後にto_numeric()で数値型にすることです。
置換処理そのものを詳しく学びたい場合は、pandas replace()の使い方も参考になります。
変換後のNaNをどう扱うか
to_numeric(errors="coerce")でNaNになった値は、次のどちらかで処理することが多いです。
| 方法 | 使う場面 | 例 |
|---|---|---|
fillna() |
欠損値を0や平均値などで埋めたい | 未入力の売上を0として扱う |
dropna() |
変換できなかった行を分析対象から外したい | 不明な売上行を除いて平均を出す |
ただし、どちらが正しいかはデータの意味によって変わります。
たとえば、売上の「不明」を0円とみなしてよいとは限りません。
0で埋める前に、NaNになった理由を確認することが大切です。
df_after = df_coerce.copy()
# 例1:売上_数値のNaNを0で埋める
df_fill = df_after.copy()
df_fill["売上_数値"] = df_fill["売上_数値"].fillna(0)
print("NaNを0で埋めた例")
display(df_fill)
# 例2:売上_数値がNaNの行を除外する
df_drop = df_after.dropna(subset=["売上_数値"])
print("売上_数値がNaNの行を除外した例")
display(df_drop)
NaNを0で埋めた例
| 商品 | カテゴリ | 売上 | 数量 | 売上_数値 | 数量_数値 | |
|---|---|---|---|---|---|---|
| 0 | A | 食品 | 1000 | 2 | 1000.0 | 2.0 |
| 1 | B | 食品 | 2500 | 5 | 2500.0 | 5.0 |
| 2 | C | 日用品 | 不明 | 3 | 0.0 | 3.0 |
| 3 | D | 日用品 | 3000 | error | 3000.0 | NaN |
| 4 | E | 食品 | – | 1 | 0.0 | 1.0 |
売上_数値がNaNの行を除外した例
| 商品 | カテゴリ | 売上 | 数量 | 売上_数値 | 数量_数値 | |
|---|---|---|---|---|---|---|
| 0 | A | 食品 | 1000 | 2 | 1000.0 | 2.0 |
| 1 | B | 食品 | 2500 | 5 | 2500.0 | 5.0 |
| 3 | D | 日用品 | 3000 | error | 3000.0 | NaN |
fillna()とdropna()は、どちらもよく使う欠損処理です。
欠損値を埋める処理を詳しく学びたい場合:
pandas fillna()の使い方欠損行を削除する処理を詳しく学びたい場合:
pandas dropna()・drop_duplicates()・drop()の使い方
今回の記事では、to_numeric()で数値化したあとに、必要に応じて欠損処理へ進む流れだけ押さえれば十分です。
数値化できると集計や可視化に進みやすくなる
to_numeric()で数値化できると、合計・平均・グループ別集計・グラフ化に進みやすくなります。
ここでは、カテゴリ別に売上合計を出す例を見てみます。
# 集計用のデータを作る
# グラフの文字化けを避けるため、カテゴリ名は英語にしています
df_sales = pd.DataFrame({
"商品": ["A", "B", "C", "D", "E", "F"],
"カテゴリ": ["Food", "Food", "Daily goods", "Daily goods", "Food", "Daily goods"],
"売上": ["1000", "2500", "不明", "3000", "1200", "1800"]
})
# 売上を数値化
df_sales["売上_数値"] = pd.to_numeric(df_sales["売上"], errors="coerce")
display(df_sales)
| 商品 | カテゴリ | 売上 | 売上_数値 | |
|---|---|---|---|---|
| 0 | A | Food | 1000 | 1000.0 |
| 1 | B | Food | 2500 | 2500.0 |
| 2 | C | Daily goods | 不明 | NaN |
| 3 | D | Daily goods | 3000 | 3000.0 |
| 4 | E | Food | 1200 | 1200.0 |
| 5 | F | Daily goods | 1800 | 1800.0 |
# NaNを除いてカテゴリ別に売上を集計
category_sales = (
df_sales
.dropna(subset=["売上_数値"])
.groupby("カテゴリ")["売上_数値"]
.sum()
.reset_index()
)
display(category_sales)
| カテゴリ | 売上_数値 | |
|---|---|---|
| 0 | Daily goods | 4800.0 |
| 1 | Food | 4700.0 |
このように、文字列だった売上列を数値化すると、groupby()でカテゴリ別に集計できるようになります。
groupby()を詳しく学びたい場合は、Pandas groupby×aggの使い方も参考になります。
import matplotlib.pyplot as plt
# 数値化した結果を棒グラフで確認
category_sales.plot(kind="bar", x="カテゴリ", y="売上_数値", legend=False)
plt.title("Sales by Category")
plt.xlabel("Category")
plt.ylabel("Sales")
plt.show()

Google Colabでは、日本語フォントの設定をしていないとグラフ内の日本語が文字化けすることがあります。
この記事ではto_numeric()で数値化したあとにグラフ化へ進める流れを確認することが目的なので、グラフ用のカテゴリ名とラベルは英語にしています。
グラフ化そのものはこの記事の主題ではありませんが、数値列が正しく数値型になっていると、Matplotlibで可視化しやすくなります。
棒グラフの作り方を詳しく学びたい場合は、Matplotlib 棒グラフ入門へ進むと理解がつながります。
補足:グラフを日本語表示したい場合
Google Colabでグラフ内の日本語を表示したい場合は、japanize-matplotlibを使う方法もあります。
!pip install japanize-matplotlib > /dev/null
import japanize_matplotlib
ただし、この記事の主題はto_numeric()で数値化する前処理です。
そのため、本文ではグラフの日本語表示設定には深入りせず、数値化後に集計・可視化へ進める流れの確認にとどめます。
Matplotlibの見やすいグラフ設定を詳しく学びたい場合は、関連記事のMatplotlib入門記事へ進んでください。
すべてのobject型を数値化すればよいわけではない
ここまで、object型の数値列をto_numeric()で変換する方法を見てきました。
ただし、すべてのobject型を数値化すればよいわけではありません。
たとえば、次のような列は、数字のように見えても文字列のまま扱った方がよいことがあります。
| 列の例 | 数値化しない方がよい理由 |
|---|---|
| 商品コード | 合計や平均を出すものではない |
| 会員番号 | 数値というより識別子として使う |
| 郵便番号 | 先頭の0が消えると困る |
| 電話番号 | 計算対象ではない |
to_numeric()を使う前に、その列を計算に使うのかを確認することが大切です。
売上、数量、点数、金額のように合計や平均を出したい列なら数値化します。
一方で、IDやコードのように識別のための列は、文字列のまま扱うこともあります。
よくあるミスと確認ポイント
to_numeric()で初心者がつまずきやすいポイントを整理します。
| よくあるミス | 原因 | 確認すること |
|---|---|---|
| 数字なのに合計できない | 文字列として読み込まれている | dtypesやinfo()を見る |
astype(int)でエラーになる |
「不明」や空欄が混ざっている | to_numeric(errors="coerce")を使う |
変換後にNaNが増える |
数値に変換できない値がある | isna()で行を確認する |
| intではなくfloatになる | NaNが含まれている |
欠損処理後に必要なら型を検討する |
| カンマ入り金額が変換できない | ,や「円」が文字として含まれている |
先に文字を整える |
| 日付まで数値化しようとする | 数値変換と日付変換を混同している | 日付はto_datetime()を使う |
日付変換については、pandas to_datetime()の使い方で詳しく解説しています。
まとめ
この記事では、pandas to_numeric()の使い方を解説しました。
ポイントを整理します。
pd.to_numeric()は、数字に見える文字列を計算できる数値型に変換する関数- CSVやExcelを読み込んだあと、数値列が
object型になることがある - 変換前後は
info()やdtypesで確認する - 変換できない値が混ざる場合は、
errors="coerce"でNaNにできる NaNになった値は、変換できなかった値として確認する- きれいな値なら
astype()、汚れた数値列を安全に扱うならto_numeric()が使いやすい - カンマや「円」付きの値は、文字を整えてから数値化する
- まずは1列ずつ確認し、慣れてきたら複数列の一括変換も使える
- 数値化できると、
sum()、mean()、groupby()、Matplotlibによる可視化へ進みやすくなる
to_numeric()は、派手な機能ではありませんが、データ分析の前処理ではとても重要です。
「数字に見えるのに計算できない」と感じたら、まずdtypesで型を確認し、必要に応じてpd.to_numeric()で数値化してみましょう。
次に読みたい関連記事
今回の記事とあわせて読むと、Pandasの前処理から集計・可視化までの流れがつながりやすくなります。
- Pandas DataFrame入門|作り方・基本操作をわかりやすく解説
- Pandas info()とdescribe()の違い|欠損値・型・統計量の見方を例で解説
- pandas astype()の使い方|文字列・数値への型変換とエラー対処を初心者向けに解説
- pandas to_datetime()の使い方|文字列の日付変換と format・NaT 対処を初心者向けに解説
- pandas replace()の使い方|値の置換・表記ゆれ・欠損値変換を解説
- pandas fillna()の使い方|欠損値を0・平均値・中央値・最頻値で埋める方法を初心者向けに解説
- pandas dropna()・drop_duplicates()・drop()の使い方
- Google Colab CSV 読み込み&保存入門
- pandas read_excel()の使い方|Excelファイル読み込み・sheet_name・usecolsを解説
- Pandas groupby×aggの使い方|基本の集計とaggの書き方を例で解説
- Matplotlib 棒グラフ入門
- Pandas初心者向け学習ロードマップ
to_numeric()とastype()は何が違いますか?
astype()は、値がきれいで変換先の型を明示したいときに使いやすい方法です。
一方、to_numeric()は、数字に見える文字列を数値化したいときに向いています。特に、「不明」「-」「空欄」などが混ざる可能性がある列では、errors="coerce"を使って、変換できない値をNaNとして確認できます。
ざっくり言うと、きれいな型変換はastype()、汚れた数値列の安全な数値化はto_numeric()と考えると分かりやすいです。
errors=”coerce”とは何ですか?
errors="coerce"は、数値に変換できない値をNaNにする指定です。
たとえば、"1000"は数値に変換できますが、"不明"や"-"はそのままでは数値にできません。
そのような値をNaNにして、あとで確認できるようにするのがerrors="coerce"です。
to_numeric()でNaNになるのはなぜですか?
元の値に、数値へ変換できない文字が含まれているためです。
たとえば、"不明"、"error"、"-"、"1,000"、"3000円"などは、そのままでは数値化できない場合があります。NaNになった行は、isna()で確認して、置換するのか、0で埋めるのか、除外するのかを判断します。
カンマ入りの「1,000」はそのまま数値にできますか?
そのままでは変換できないことがあります。
基本的には、先にカンマを取り除いてからto_numeric()を使います。df["売上"] = df["売上"].str.replace(",", "", regex=False) df["売上"] = pd.to_numeric(df["売上"], errors="coerce")
「円」が付いた金額はどうすればよいですか?
カンマや「円」を取り除いてから、to_numeric()で数値化します。本文の例と同じく、最後にerrors="coerce"で変換できない値を確認すると安全です。df["金額"] = (
df["金額"]
.str.replace(",", "", regex=False)
.str.replace("円", "", regex=False) ) df["金額"] = pd.to_numeric(df["金額"], errors="coerce")
read_csvで読み込んだ列がobject型になるのはなぜですか?
列の中に、数値だけでなく文字や空欄、記号が混ざっていると、pandasがその列を文字列寄りのobject型として読み込むことがあります。
たとえば、売上列に"1000"、"2500"、"不明"が混ざっていると、数値列として扱いにくくなります。
その場合は、読み込んだあとにinfo()やdtypesで確認し、必要に応じてto_numeric()で変換します。
コメント