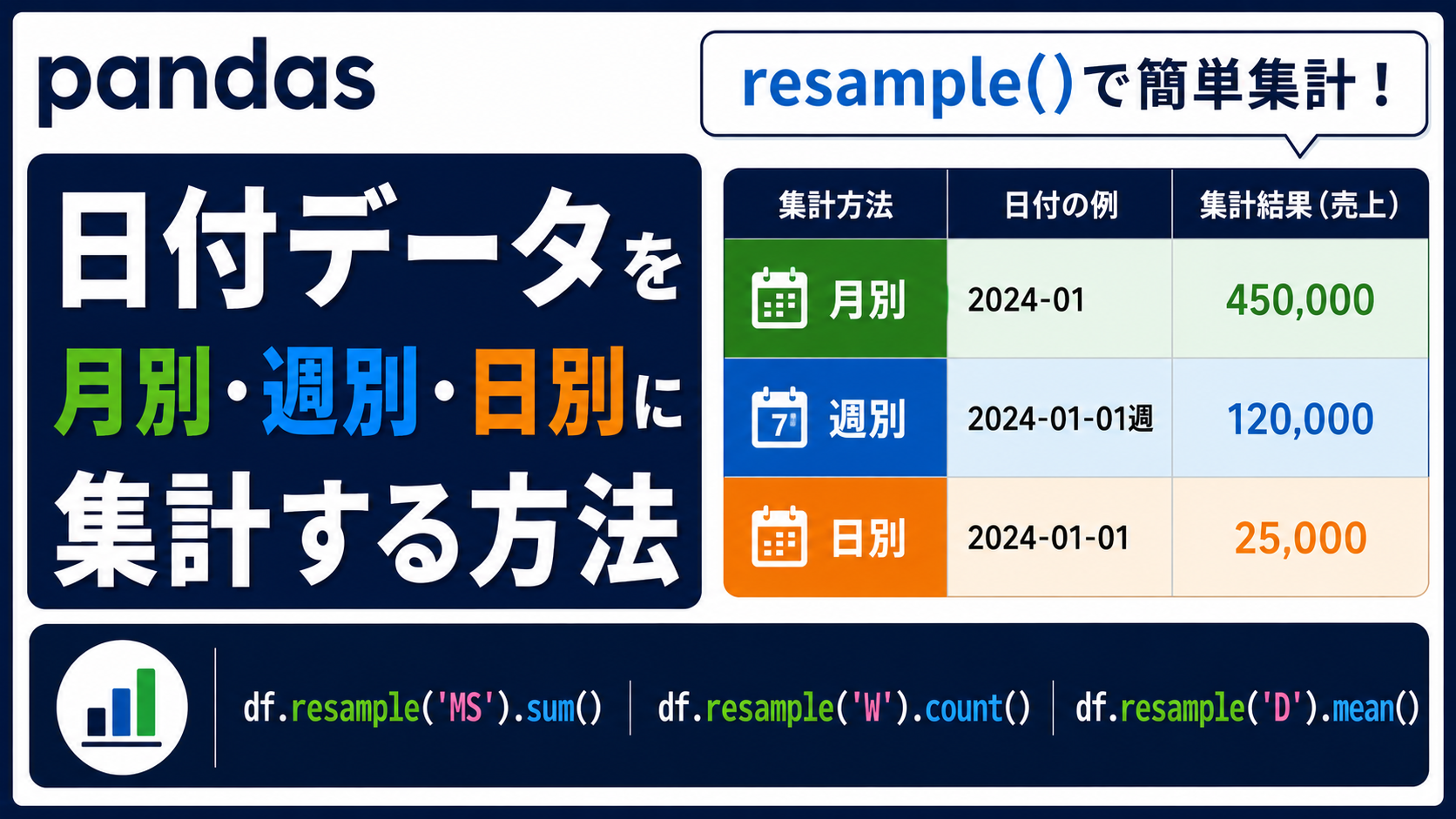
CSVやExcelを読み込んだあと、注文日・来店日・売上日などの日付列はあるのに、次のような集計で迷うことがあります。
- 月ごとの売上合計を出したい
- 週ごとの注文件数を数えたい
- 日別の平均売上を確認したい
- 集計した結果を折れ線グラフで見たい
このようなときに役立つのが、pandasの resample() です。
resample() は、日付データを日別・週別・月別などの時間単位でまとめて集計するためのメソッドです。
イメージとしては、1行ずつ並んでいる日付データを「1日ごと」「1週間ごと」「1か月ごと」の箱に分け、その箱ごとに合計・平均・件数を計算する処理です。
たとえば、1件ずつ並んでいる注文データから、月別売上や週別件数を作りたいときに使います。
この記事では、to_datetime() で日付列を整えるところから、resample() で月別・週別・日別に集計し、最後にグラフ化へつなげる流れまで、Google Colabで試しやすいサンプルデータを使って解説します。
- この記事でわかること
- 関連する前提知識
- まず結論:resample()は日付を時間単位でまとめるときに使う
- サンプルデータを用意する
- resample()を使う前に日付列をdatetime型にする
- 方法1:日付列をインデックスにしてresample()する
- 月別売上を集計する:resample(“MS”).sum()
- 頻度指定の基本:D・W・MS・MEを使い分ける
- 複数の集計をまとめて出す
- 週別件数を集計する:resample(“W”).count()
- 日別平均を集計する:resample(“D”).mean()
- 方法2:on引数で日付列を指定してresample()する
- groupby()・dt・resample()の違い
- 比較用:dtで年月列を作ってgroupby()する方法
- 補足:resample()とasfreq()の違い
- 集計結果をreset_index()で通常の表に戻す
- 集計結果をグラフで確認する
- よくあるミスと確認ポイント
- resample()はデータ分析の流れのどこで使うか
- まとめ
- 次に読みたい関連記事
この記事でわかること
この記事では、次の内容を学びます。
resample()が何をするメソッドかresample()を使う前に日付列をdatetime型にする理由set_index()してからresample()する基本on="日付列"で日付列を指定して集計する方法- 日別・週別・月別に集計する方法
sum()、mean()、count()の使い分けgroupby()・dt・resample()の違いresample()とasfreq()の違い- 集計結果を
reset_index()で扱いやすい表に戻す方法 - 集計結果をグラフ化へつなげる流れ
この記事のゴールは、日付列をdatetime型に整え、resample()で日別・週別・月別に集計し、集計結果を表やグラフで確認できるようになることです。
関連する前提知識
この記事は、日付データを「時間のまとまり」で集計する記事です。
先に次の内容を確認しておくと、より理解しやすくなります。
- Google ColabでCSVを読み込む方法|Drive連携とpandas read_csvを初心者向けに解説
- pandas to_datetime()の使い方|文字列の日付変換と format・NaT 対処を初心者向けに解説
- pandas dtの使い方|日付から年・月・曜日を取り出す方法を初心者向けに解説
- pandas set_index()の使い方|列をインデックスにする・drop=False・index_col・reset_indexとの違いを解説
- Pandas groupby×aggの使い方|基本の集計とaggの書き方を例で解説
ただし、この記事では必要な部分を順番に確認するため、最初から読んでも進められるようにしています。
まず結論:resample()は日付を時間単位でまとめるときに使う
resample() は、日付データを一定の時間単位でまとめるために使います。
たとえば、次のような明細データがあるとします。
| 注文日 | カテゴリ | 売上 |
|---|---|---|
| 2026-01-05 | 食品 | 1200 |
| 2026-01-12 | 日用品 | 600 |
| 2026-02-03 | 日用品 | 2600 |
| 2026-03-15 | 食品 | 1800 |
このような1件ずつのデータを、次のように月別にまとめたいときに resample() が役立ちます。
| 年月 | 売上合計 |
|---|---|
| 2026-01 | 4000 |
| 2026-02 | 10980 |
| 2026-03 | 5100 |
ポイントは、resample() が「カテゴリごと」ではなく、日付を基準にして、日別・週別・月別などの時間のまとまりで集計することです。
最初に判断基準を整理すると、次のようになります。
| やりたいこと | 使うもの | 例 |
|---|---|---|
| 日付を月別・週別・日別にまとめたい | resample() |
月別売上、週別件数 |
| カテゴリや店舗ごとにまとめたい | groupby() |
カテゴリ別売上、店舗別平均 |
| 日付から年・月・曜日を取り出したい | dt |
年列、月列、曜日列を追加 |
| 文字列の日付を日付型に変換したい | to_datetime() |
"2026-01-05" をdatetime型にする |
この記事では、このうち resample() を中心に扱います。
サンプルデータを用意する
ここでは、注文日・カテゴリ・商品・売上・数量を持つ小さな売上データを使います。
実際のCSVでは日付順に並んでいるとは限らないため、サンプルデータもあえて少し日付順をばらしています。
import pandas as pd
df = pd.DataFrame({
"注文日": [
"2026-03-15", "2026-01-05", "2026-02-03", "2026-01-18",
"2026-03-28", "2026-02-25", "2026-01-28", "2026-02-12",
"2026-03-02", "2026-01-12", "2026-02-05", "2026-03-05"
],
"カテゴリ": [
"食品", "食品", "日用品", "食品",
"日用品", "食品", "日用品", "日用品",
"食品", "日用品", "食品", "食品"
],
"商品": [
"コーヒー", "パン", "洗剤", "お茶",
"ティッシュ", "お米", "歯ブラシ", "シャンプー",
"牛乳", "ノート", "卵", "ヨーグルト"
],
"売上": [1800, 1200, 2600, 1500, 900, 4200, 700, 3200, 1100, 600, 980, 1300],
"数量": [3, 2, 1, 3, 2, 1, 2, 1, 2, 3, 2, 2]
})
display(df)
print(df.dtypes)
| 注文日 | カテゴリ | 商品 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 0 | 2026-03-15 | 食品 | コーヒー | 1800 | 3 |
| 1 | 2026-01-05 | 食品 | パン | 1200 | 2 |
| 2 | 2026-02-03 | 日用品 | 洗剤 | 2600 | 1 |
| 3 | 2026-01-18 | 食品 | お茶 | 1500 | 3 |
| 4 | 2026-03-28 | 日用品 | ティッシュ | 900 | 2 |
| 5 | 2026-02-25 | 食品 | お米 | 4200 | 1 |
| 6 | 2026-01-28 | 日用品 | 歯ブラシ | 700 | 2 |
| 7 | 2026-02-12 | 日用品 | シャンプー | 3200 | 1 |
| 8 | 2026-03-02 | 食品 | 牛乳 | 1100 | 2 |
| 9 | 2026-01-12 | 日用品 | ノート | 600 | 3 |
| 10 | 2026-02-05 | 食品 | 卵 | 980 | 2 |
| 11 | 2026-03-05 | 食品 | ヨーグルト | 1300 | 2 |
注文日 object カテゴリ object 商品 object 売上 int64 数量 int64 dtype: object
注文日 は日付のように見えますが、この時点では object 型です。
resample() で日付を基準に集計するには、日付列を datetime 型に変換する必要があります。
CSVやExcelを読み込んだ直後は、まず dtypes や info() で型を確認するのが大切です。
resample()を使う前に日付列をdatetime型にする
注文日 を pd.to_datetime() で datetime 型に変換します。
ここでは、変換後に日付順で並び替えておきます。
日付順に並んでいなくても集計自体はできますが、表示や確認がしやすくなります。
df_date = df.copy()
df_date["注文日"] = pd.to_datetime(df_date["注文日"])
df_date = df_date.sort_values("注文日")
display(df_date)
print(df_date.dtypes)
| 注文日 | カテゴリ | 商品 | 売上 | 数量 | |
|---|---|---|---|---|---|
| 1 | 2026-01-05 | 食品 | パン | 1200 | 2 |
| 9 | 2026-01-12 | 日用品 | ノート | 600 | 3 |
| 3 | 2026-01-18 | 食品 | お茶 | 1500 | 3 |
| 6 | 2026-01-28 | 日用品 | 歯ブラシ | 700 | 2 |
| 2 | 2026-02-03 | 日用品 | 洗剤 | 2600 | 1 |
| 10 | 2026-02-05 | 食品 | 卵 | 980 | 2 |
| 7 | 2026-02-12 | 日用品 | シャンプー | 3200 | 1 |
| 5 | 2026-02-25 | 食品 | お米 | 4200 | 1 |
| 8 | 2026-03-02 | 食品 | 牛乳 | 1100 | 2 |
| 11 | 2026-03-05 | 食品 | ヨーグルト | 1300 | 2 |
| 0 | 2026-03-15 | 食品 | コーヒー | 1800 | 3 |
| 4 | 2026-03-28 | 日用品 | ティッシュ | 900 | 2 |
注文日 datetime64[ns] カテゴリ object 商品 object 売上 int64 数量 int64 dtype: object
注文日 の型が datetime64[ns] になりました。
これで、pandasがこの列を「日付として扱える状態」になりました。
日付変換そのものを詳しく知りたい場合は、pandas to_datetime()の使い方で、format や NaT の考え方を確認できます。
方法1:日付列をインデックスにしてresample()する
resample() の基本は、日付列をインデックスにしてから集計する書き方です。
ここでは、set_index("注文日") で 注文日 をインデックスにします。
df_time = df_date.set_index("注文日")
display(df_time)
print(type(df_time.index))
| カテゴリ | 商品 | 売上 | 数量 | |
|---|---|---|---|---|
| 2026-01-05 | 食品 | パン | 1200 | 2 |
| 2026-01-12 | 日用品 | ノート | 600 | 3 |
| 2026-01-18 | 食品 | お茶 | 1500 | 3 |
| 2026-01-28 | 日用品 | 歯ブラシ | 700 | 2 |
| 2026-02-03 | 日用品 | 洗剤 | 2600 | 1 |
| 2026-02-05 | 食品 | 卵 | 980 | 2 |
| 2026-02-12 | 日用品 | シャンプー | 3200 | 1 |
| 2026-02-25 | 食品 | お米 | 4200 | 1 |
| 2026-03-02 | 食品 | 牛乳 | 1100 | 2 |
| 2026-03-05 | 食品 | ヨーグルト | 1300 | 2 |
| 2026-03-15 | 食品 | コーヒー | 1800 | 3 |
| 2026-03-28 | 日用品 | ティッシュ | 900 | 2 |
<class 'pandas.core.indexes.datetimes.DatetimeIndex'>
注文日 がインデックスになり、DatetimeIndex として扱われるようになりました。
| 状態 | 注文日の位置 | resample()での扱いやすさ |
|---|---|---|
| 処理前 | 通常の列 | そのままでは基本形のresample()に使いにくい |
| 処理後 | DatetimeIndex | df.resample("MS") のように集計できる |
set_index() の詳しい使い方は、pandas set_index()の使い方で確認できます。
月別売上を集計する:resample(“MS”).sum()
まずは、月別の売上合計を出します。
ここでは resample("MS") を使います。
MSは、月初基準の月別集計ですMEは、月末基準の月別集計です- 古い記事では
Mと書かれていることがありますが、最近のpandasでは月末基準を表すならMEを使う方が安全です sum()は、売上を合計するために使います
「月別売上を知りたい」場合は、平均ではなく合計を出すことが多いため、ここでは sum() を使います。
この記事では、月ごとの結果を表で見たときに読みやすいように、月初の日付で表示される MS を中心に使います。
monthly_sales = df_time.resample("MS")["売上"].sum().to_frame("月別売上合計")
display(monthly_sales)
| 月別売上合計 | |
|---|---|
| 2026-01-01 | 4000 |
| 2026-02-01 | 10980 |
| 2026-03-01 | 5100 |
1件ずつ並んでいた明細データが、月ごとの売上合計にまとまりました。
| 処理前 | 処理後 |
|---|---|
| 注文日ごとに1行ずつ並んだ明細データ | 月ごとに売上を合計した集計表 |
| 売上の推移が見えにくい | 2026年1月、2月、3月の売上合計を比較しやすい |
このように、resample() は時系列データを「見やすい単位」にまとめるときに役立ちます。
出力例で見る:MS・ME・Mの違い
MS と ME の違いは、集計結果の「ラベル日付」に出ます。
MS:月初の日付で表示されますME:月末の日付で表示されますM:古い記事や古いコードで見かける月末基準の書き方です
売上合計の金額は同じでも、表示される日付ラベルが変わる点を確認してみましょう。
monthly_ms = df_time.resample("MS")["売上"].sum().reset_index()
monthly_ms.columns = ["MSのラベル日付", "MSの売上合計"]
monthly_me = df_time.resample("ME")["売上"].sum().reset_index()
monthly_me.columns = ["MEのラベル日付", "MEの売上合計"]
# 古い記事では resample("M") を見かけることがあります。
# 最近のpandasでは月末基準を表す場合、resample("ME") を使う方が安全です。
try:
import warnings
with warnings.catch_warnings():
warnings.simplefilter("ignore", FutureWarning)
monthly_m = df_time.resample("M")["売上"].sum().reset_index()
monthly_m.columns = ["Mのラベル日付", "Mの売上合計"]
display(pd.concat([monthly_ms, monthly_me, monthly_m], axis=1))
except Exception:
print("このpandas環境では resample('M') を実行できません。月末基準は resample('ME') を使ってください。")
display(pd.concat([monthly_ms, monthly_me], axis=1))
| MSのラベル日付 | MSの売上合計 | MEのラベル日付 | MEの売上合計 | Mのラベル日付 | Mの売上合計 | |
|---|---|---|---|---|---|---|
| 0 | 2026-01-01 | 4000 | 2026-01-31 | 4000 | 2026-01-31 | 4000 |
| 1 | 2026-02-01 | 10980 | 2026-02-28 | 10980 | 2026-02-28 | 10980 |
| 2 | 2026-03-01 | 5100 | 2026-03-31 | 5100 | 2026-03-31 | 5100 |
MS は 2026-01-01、2026-02-01 のように月初の日付で表示されます。
一方、ME は 2026-01-31、2026-02-28 のように月末の日付で表示されます。
古い記事で見かける M は、月末基準の古い書き方として出てくることがあります。新しく記事を書く場合や、これから学ぶ場合は、月末基準なら ME、月初基準なら MS と覚えておくと混乱しにくいです。
頻度指定の基本:D・W・MS・MEを使い分ける
resample() のカッコの中には、どの時間単位でまとめるかを指定します。
初心者のうちは、まず次の指定を覚えれば十分です。
| 指定 | 意味 | 使う場面 |
|---|---|---|
"D" |
日別 | 日ごとの平均・件数を見たい |
"W" |
週別 | 週ごとの注文件数や売上を見たい |
"MS" |
月別(月初基準) | 月別集計を月初の日付で表示したい |
"ME" |
月別(月末基準) | 月別集計を月末の日付で表示したい |
"M" |
月別(月末基準の古い書き方) | 古い記事や古いコードで見かけることがある |
"QE" |
四半期 | 四半期ごとに軽くまとめたい |
"YE" |
年別 | 年ごとに軽くまとめたい |
検索すると、月別集計の例で resample("M") を見かけることがあります。
ただし、最近のpandasでは M よりも、月末基準なら ME、月初基準なら MS と書く方がわかりやすく、今後も安心です。
この記事では、月別の表として見やすいように、主に "MS" を使います。
複数の集計をまとめて出す
月別に、売上合計・注文件数・平均売上・数量合計をまとめて出すこともできます。
ここでは、次のように集計します。
| 出したい値 | 使う集計 |
|---|---|
| 売上合計 | sum() |
| 注文件数 | count() |
| 平均売上 | mean() |
| 数量合計 | sum() |
売上合計と平均売上は意味が違います。
また、count() は指定した列の欠損値を数えません。今回のように 売上 列に欠損がない前提なら注文件数として使えますが、行数そのものを数えたい場合は size() も候補になります。
見出しや表の名前と、実際に使う集計方法がズレないように注意しましょう。
monthly_summary = df_time.resample("MS").agg(
売上合計=("売上", "sum"),
注文件数=("売上", "count"),
平均売上=("売上", "mean"),
数量合計=("数量", "sum")
)
display(monthly_summary)
| 売上合計 | 注文件数 | 平均売上 | 数量合計 | |
|---|---|---|---|---|
| 2026-01-01 | 4000 | 4 | 1000.0 | 10 |
| 2026-02-01 | 10980 | 4 | 2745.0 | 5 |
| 2026-03-01 | 5100 | 4 | 1275.0 | 9 |
この表を見ると、月ごとの売上合計だけでなく、注文件数や平均売上も確認できます。
実務では、売上合計だけを見ると「2月が大きい」とわかります。
さらに注文件数や平均売上を見ると、「件数が多いのか、1件あたりの売上が大きいのか」も確認しやすくなります。
週別件数を集計する:resample(“W”).count()
次に、週ごとの注文件数を数えてみます。
ここでは「売上の合計」ではなく、「何件の注文があったか」を見たいので、count() を使います。今回のサンプルでは 売上 列に欠損がないため、売上 を数えることで注文件数を確認できます。
weekly_count = df_time.resample("W")["売上"].count().to_frame("週別注文件数")
display(weekly_count)
| 週別注文件数 | |
|---|---|
| 2026-01-11 | 1 |
| 2026-01-18 | 2 |
| 2026-01-25 | 0 |
| 2026-02-01 | 1 |
| 2026-02-08 | 2 |
| 2026-02-15 | 1 |
| 2026-02-22 | 0 |
| 2026-03-01 | 1 |
| 2026-03-08 | 2 |
| 2026-03-15 | 1 |
| 2026-03-22 | 0 |
| 2026-03-29 | 1 |
W は週別の集計です。
週別集計では、週の区切り方によって結果の見え方が変わることがあります。
初心者のうちは、まず「週ごとにざっくり件数を見る」用途で使い、細かい週の開始日・終了日の指定は必要になったときに確認すれば十分です。
日別平均を集計する:resample(“D”).mean()
次に、日別の平均売上を確認します。
ここでは resample("D") で日別にまとめ、mean() で平均を出します。
daily_mean = df_time.resample("D")["売上"].mean().to_frame("日別平均売上")
display(daily_mean.head(10))
| 日別平均売上 | |
|---|---|
| 2026-01-05 | 1200.0 |
| 2026-01-06 | NaN |
| 2026-01-07 | NaN |
| 2026-01-08 | NaN |
| 2026-01-09 | NaN |
| 2026-01-10 | NaN |
| 2026-01-11 | NaN |
| 2026-01-12 | 600.0 |
| 2026-01-13 | NaN |
| 2026-01-14 | NaN |
日別にすると、注文がない日も期間として表示されることがあります。
この例では、注文がない日の平均売上は NaN になります。
これはエラーではなく、「その日に集計できるデータがなかった」という意味です。
欠損期間の補完や ffill()、interpolate() などの処理は便利ですが、この記事では深入りしません。
まずは、resample() によって空の期間が見えることがある、と理解しておきましょう。
方法2:on引数で日付列を指定してresample()する
resample() は、必ず set_index() しないと使えないわけではありません。
日付列が datetime 型になっていれば、on="注文日" のように指定して集計できます。
インデックスを変更したくない場合は、この書き方が便利です。
monthly_sales_on = (
df_date
.resample("MS", on="注文日")["売上"]
.sum()
.reset_index(name="月別売上合計")
)
display(monthly_sales_on)
| 注文日 | 月別売上合計 | |
|---|---|---|
| 0 | 2026-01-01 | 4000 |
| 1 | 2026-02-01 | 10980 |
| 2 | 2026-03-01 | 5100 |
on="注文日" を使うと、注文日 をインデックスにしなくても月別集計ができます。
| 書き方 | 特徴 |
|---|---|
set_index("注文日").resample("MS") |
時系列データとして扱う流れがわかりやすい |
resample("MS", on="注文日") |
インデックスを変えずに日付列を指定できる |
初心者の学習では、まず set_index() する基本形を理解し、慣れてきたら on 引数を使うとよいです。
groupby()・dt・resample()の違い
日付データを扱うときは、groupby()、dt、resample() の違いで迷いやすいです。
ここで一度、使い分けを整理します。
| 使うもの | 役割 | 例 |
|---|---|---|
resample() |
日付を日別・週別・月別などの時間単位で集計する | 月別売上、週別件数 |
groupby() |
カテゴリや作成した列ごとに集計する | カテゴリ別売上、店舗別平均 |
dt |
日付から年・月・曜日などを取り出す | 月列を作る、曜日列を作る |
月別集計は、dt.month で月列を作って groupby() する方法でもできます。
ただし、年をまたぐデータで「月」だけを使うと、2025年1月と2026年1月が混ざる可能性があります。
日付の流れに沿って月別・週別にまとめたい場合は、resample() を使うと自然です。
比較用:dtで年月列を作ってgroupby()する方法
比較のために、dt.to_period("M") で年月列を作り、groupby() で月別集計する例も確認します。
これは resample() の代わりに使える場面もありますが、この記事ではあくまで違いを理解するための補足です。
df_group = df_date.copy()
df_group["年月"] = df_group["注文日"].dt.to_period("M")
monthly_groupby = (
df_group
.groupby("年月")["売上"]
.sum()
.reset_index(name="月別売上合計")
)
display(monthly_groupby)
| 年月 | 月別売上合計 | |
|---|---|---|
| 0 | 2026-01 | 4000 |
| 1 | 2026-02 | 10980 |
| 2 | 2026-03 | 5100 |
dt と groupby() を組み合わせても月別集計はできます。
ただし、今回のように「日付を時間単位でまとめる」ことが目的なら、resample() を使うと、日別・週別・月別への切り替えがしやすくなります。
dt の詳しい使い方は pandas dtの使い方 で、カテゴリ別集計は Pandas groupby×aggの使い方 で確認できます。
補足:resample()とasfreq()の違い
時系列データの記事では、resample() と一緒に asfreq() というメソッドを見かけることがあります。
初心者のうちは、まず次のように分けて考えると十分です。
| やりたいこと | 使うもの | 考え方 |
|---|---|---|
| 月別売上の合計を出したい | resample().sum() |
期間ごとに集計する |
| 週別の平均を出したい | resample().mean() |
期間ごとに集計する |
| 日付の間隔だけそろえたい | asfreq() |
指定した頻度の行を作る |
| 欠けている日付を表示したい | asfreq() |
集計せず、日付の並びをそろえる |
| 欠けた期間も含めて集計結果を確認したい | resample() |
期間の箱を作って集計する |
resample() は、日付を一定期間の箱に分けて、その箱ごとに合計・平均・件数などを計算します。
一方、asfreq() は、日付の頻度をそろえるための処理です。基本的には集計をするメソッドではありません。
この記事では、月別売上や週別件数のように「期間ごとに集計する」ことが目的なので、主役は resample() です。ここでは、asfreq() が集計ではなく日付の間隔をそろえる処理であることを、短いコードで確認します。
daily_asfreq = df_time["売上"].asfreq("D").to_frame("asfreq_D")
daily_resample_sum = df_time["売上"].resample("D").sum().to_frame("resample_D_sum")
daily_compare = pd.concat([daily_asfreq, daily_resample_sum], axis=1)
display(daily_compare.head(10))
| asfreq_D | resample_D_sum | |
|---|---|---|
| 2026-01-05 | 1200.0 | 1200 |
| 2026-01-06 | NaN | 0 |
| 2026-01-07 | NaN | 0 |
| 2026-01-08 | NaN | 0 |
| 2026-01-09 | NaN | 0 |
| 2026-01-10 | NaN | 0 |
| 2026-01-11 | NaN | 0 |
| 2026-01-12 | 600.0 | 600 |
| 2026-01-13 | NaN | 0 |
| 2026-01-14 | NaN | 0 |
上の表を見ると、asfreq("D") は日付の間隔を日別にそろえるだけなので、注文がない日は NaN になります。
一方、resample("D").sum() は日別の箱を作って売上を合計するため、注文がない日は合計が0のように表示されることがあります。
つまり、集計したいなら resample()、日付の並びをそろえたいなら asfreq() と考えると分かりやすいです。
集計結果をreset_index()で通常の表に戻す
resample() の結果は、日付がインデックスになっていることが多いです。
このままでも分析できますが、CSVに保存したり、他の表と結合したり、WordPress記事で表として見せたりする場合は、reset_index() で通常の列に戻すと扱いやすくなります。
monthly_summary_reset = monthly_summary.reset_index()
monthly_summary_reset["年月"] = monthly_summary_reset["注文日"].dt.strftime("%Y-%m")
display(monthly_summary_reset)
| 注文日 | 売上合計 | 注文件数 | 平均売上 | 数量合計 | 年月 | |
|---|---|---|---|---|---|---|
| 0 | 2026-01-01 | 4000 | 4 | 1000.0 | 10 | 2026-01 |
| 1 | 2026-02-01 | 10980 | 4 | 2745.0 | 5 | 2026-02 |
| 2 | 2026-03-01 | 5100 | 4 | 1275.0 | 9 | 2026-03 |
reset_index() によって、インデックスだった 注文日 が通常の列に戻りました。
さらに strftime("%Y-%m") を使うと、2026-01 のような年月表示も作れます。
reset_index() の詳しい使い方は、pandas reset_index()の使い方で確認できます。
集計結果をグラフで確認する
月別集計ができたら、折れ線グラフや棒グラフにすると推移を確認しやすくなります。
ここでは、月別売上合計を簡単な折れ線グラフで表示します。
グラフ装飾は深入りせず、集計結果を可視化につなげる流れだけ確認します。
なお、Google Colabでは日本語フォント設定をしていないと、グラフ内の日本語ラベルが文字化けすることがあります。ここでは、まず resample() の集計結果を確認することを優先し、グラフのタイトルや軸ラベルは英語表記にしています。
ここでは月別の集計結果を折れ線グラフにします。日付ラベルが重ならないように、x軸の表示をYYYY-MM形式にし、ラベルを少し回転させています。
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
plot_df = monthly_summary_reset.copy()
fig, ax = plt.subplots(figsize=(8, 4))
ax.plot(plot_df["注文日"], plot_df["売上合計"], marker="o")
ax.set_title("Monthly Sales")
ax.set_xlabel("Month")
ax.set_ylabel("Sales")
ax.grid(True)
# x軸の日付ラベルが重ならないように、表示形式と角度を調整します
ax.xaxis.set_major_formatter(mdates.DateFormatter("%Y-%m"))
plt.xticks(rotation=45, ha="right")
plt.tight_layout()
plt.show()

このように、resample() で月別に集計すると、売上の推移をグラフで確認しやすくなります。
折れ線グラフの設定を詳しく知りたい場合は、Matplotlib折れ線グラフの描き方を参考にしてください。
月別売上を棒グラフで比較したい場合は、Matplotlib 棒グラフ入門も役立ちます。
よくあるミスと確認ポイント
resample() でつまずきやすいポイントを整理します。
日付列がobject型のままになっている
日付に見えても、object 型のままだと resample() でうまく扱えません。
まず pd.to_datetime() で日付型に変換しましょう。
DatetimeIndexまたはonで指定した日付列が必要
resample() は、日付列そのものを自動で探してくれるわけではありません。
基本形では、日付列をインデックスにします。
インデックスにしたくない場合は、on="注文日" のように指定します。
売上合計・平均・件数を混同しない
sum()、mean()、count() は意味が違います。
| 見たいもの | 使う集計 |
|---|---|
| 売上合計 | sum() |
| 平均売上 | mean() |
| 注文件数 | count() または size() |
count() は、指定した列の欠損値を数えません。欠損を含む列で件数を数える場合は、count() と size() の違いに注意します。
「月別売上を集計する」という見出しなら sum()、
「平均を出す」という見出しなら mean() を使うように、説明とコードを一致させることが大切です。
月だけでgroupbyすると年をまたいだときに混ざる
dt.month だけで集計すると、2025年1月と2026年1月が同じ「1月」としてまとまる可能性があります。
年をまたぐデータでは、dt.to_period("M") を使うか、resample() で年月を意識した集計にする方が安全です。
欠損期間が出ることがある
日別や週別で集計すると、データがない期間が表示されることがあります。
平均なら NaN、合計なら0のように見える場合があります。
これは、resample() が時間の区切りを作って集計しているためです。
resample()はデータ分析の流れのどこで使うか
resample() は、データ分析の流れの中では「日付を使った集計」の場面で使います。
全体の流れで見ると、次の位置づけです。
- CSVやExcelを読み込む
head()やinfo()でデータを確認するto_datetime()で日付列を日付型にする- 必要に応じて
sort_values()で日付順に並べる resample()で日別・週別・月別に集計するreset_index()で表として扱いやすくする- Matplotlibで推移を可視化する
つまり、resample() は、単独で覚えるよりも、日付変換・集計・可視化へ進む流れの中で覚えると使いやすくなります。
なお、移動平均を出す rolling() や、頻度をそろえる asfreq() も時系列データで使われます。
ただし、この記事では resample() の基本に集中するため、詳しい使い方は別記事で扱う範囲です。
まとめ
この記事では、pandasの resample() を使って、日付データを月別・週別・日別に集計する方法を解説しました。
重要なポイントは次のとおりです。
resample()は、日付データを日別・週別・月別などの時間単位で集計するために使う- 使う前に、日付列を
pd.to_datetime()でdatetime型に変換する - 基本形では、
set_index("日付列")で日付をインデックスにしてからresample()する - インデックスを変えたくない場合は、
on="日付列"を使える - 月別売上なら
sum()、平均売上ならmean()、件数ならcount()を使う - カテゴリ別にまとめたいなら
groupby()、年・月・曜日を取り出したいならdt、時間単位でまとめたいならresample()を使う - 集計結果は
reset_index()で通常の表に戻すと扱いやすい - 月別集計の結果は、折れ線グラフや棒グラフにすると推移を確認しやすい
resample() を使えるようになると、CSVやExcelで読み込んだ日付付きデータから、月別売上・週別件数・日別平均などを作れるようになります。
日付データを前処理して、集計し、可視化する流れの中で、とても役立つメソッドです。
次に読みたい関連記事
日付集計をさらに理解するには、次の記事も参考になります。
- pandas to_datetime()の使い方|文字列の日付変換と format・NaT 対処を初心者向けに解説
- pandas dtの使い方|日付から年・月・曜日を取り出す方法を初心者向けに解説
- pandas set_index()の使い方|列をインデックスにする・drop=False・index_col・reset_indexとの違いを解説
- pandas reset_index()の使い方|インデックスを振り直す・drop=Trueを初心者向けに解説
- Pandas groupby×aggの使い方|基本の集計とaggの書き方を例で解説
- pandas 並び替え(sort)入門|sort_values・sort_indexの違いと複数列ソート
- Matplotlib折れ線グラフの描き方:色・線種・凡例を完全解説
- Matplotlib 棒グラフ入門:横棒・グループ化・積み上げまで解説
- Google ColabでCSVを読み込む方法|Drive連携とpandas read_csvを初心者向けに解説
resample()とgroupby()の違いは何ですか?
resample() は、日付を日別・週別・月別などの時間単位でまとめるときに使います。
一方、groupby() は、カテゴリ・店舗・商品など、列の値ごとにまとめるときに使います。
月別売上や週別件数のように、時間の区切りで集計したい場合は resample() が向いています。
カテゴリ別売上や店舗別平均のように、分類ごとに集計したい場合は groupby() が向いています。
resample()とasfreq()の違いは何ですか?
resample()
一方、asfreq() は、日付の間隔をそろえるために使います。基本的には集計をするメソッドではありません。
たとえば、注文がない日を日付として表示したいだけなら asfreq()、日ごとの売上合計を出したいなら resample("D").sum() を使います。
月別売上や週別件数を出したい場合は resample()、日付の並びをそろえたい場合は asfreq() と考えると分かりやすいです。
resample()を使うには必ずset_index()が必要ですか?
必ずではありません。
基本形では、日付列を set_index() でインデックスにしてから resample() します。
ただし、日付列が datetime 型になっていれば、resample("MS", on="注文日") のように on 引数で日付列を指定することもできます。
日付列がobject型のままだとresample()できますか?
基本的には、日付列は datetime 型に変換してから使います。
日付に見える文字列でも、pandas上では object 型になっていることがあります。
その場合は、先に pd.to_datetime() で変換しましょう。
月別集計はresample()とdt.month+groupby()のどちらがよいですか?
日付の流れに沿って月別・週別・日別に集計したい場合は、resample() が自然です。dt.month で月だけを取り出して groupby() する方法もありますが、年をまたぐデータでは、2025年1月と2026年1月が混ざる可能性があります。
年も含めて集計したい場合は、dt.to_period("M") を使うか、resample() を使うと安全です。
resample(“M”)・resample(“ME”)・resample(“MS”)の違いは何ですか?
MS は月初基準、ME は月末基準の月別集計です。
たとえば、1月の集計結果を 2026-01-01 のような月初日付で表示したい場合は MS、2026-01-31 のような月末日付で表示したい場合は ME を使います。
古い記事や古いコードでは resample("M") を見かけることがあります。これは月末基準の古い書き方として出てくることがありますが、最近のpandasでは ME と書く方が安全です。
初心者向けの記事や表では、月初基準の MS の方が月ごとのまとまりを読み取りやすいことがあります。
resample()した後に普通の列に戻すにはどうすればよいですか?
reset_index() を使います。resample() の結果は、日付がインデックスになっていることがあります。
CSVに保存したり、他のDataFrameと結合したり、表として見せたりする場合は、reset_index() で日付を通常の列に戻すと扱いやすくなります。
コメント